Combining Distantly Supervised Models with In Context Learning for Monolingual and Cross-Lingual Relation Extraction
作者: Vipul Rathore, Malik Hammad Faisal, Parag Singla, Mausam
分类: cs.CL
发布日期: 2025-10-21
💡 一句话要点
提出HYDRE框架,结合远程监督模型与上下文学习,提升单语和跨语关系抽取效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 远程监督关系抽取 上下文学习 大型语言模型 低资源语言 跨语言学习
📋 核心要点
- 现有远程监督关系抽取模型依赖特定任务训练,与大型语言模型上下文学习结合不足,易受噪声标注影响。
- HYDRE框架结合预训练DSRE模型和动态范例检索,为LLM提供可靠的句子级别范例,提升关系抽取准确性。
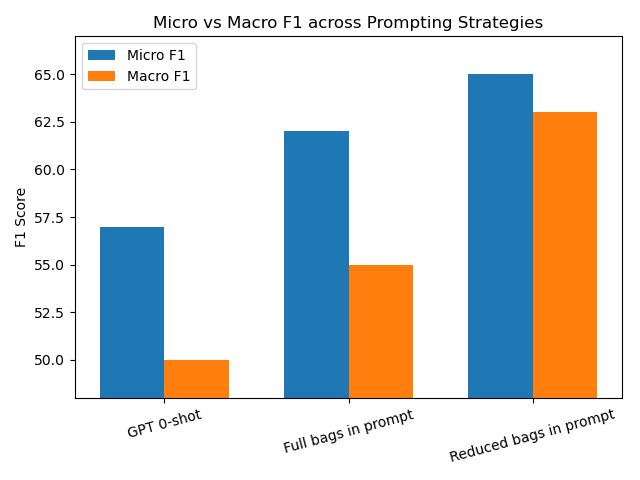
- 实验表明,HYDRE在英语和多种低资源印度语言上,相比现有方法,F1值平均提升17-20点。
📝 摘要(中文)
远程监督关系抽取(DSRE)是NLP领域一个长期存在的挑战,模型必须从噪声的包级别标注中学习,同时进行句子级别的预测。现有的最先进(SoTA) DSRE模型依赖于特定任务的训练,但它们与使用大型语言模型(LLM)的上下文学习(ICL)的集成仍未被充分探索。一个关键的挑战是,由于噪声标注,LLM可能无法正确学习关系语义。为了解决这个问题,我们提出了HYDRE——混合远程监督关系抽取框架。它首先使用训练好的DSRE模型来识别给定测试句子的前k个候选关系,然后使用一种新颖的动态范例检索策略,从训练数据中提取可靠的句子级别范例,这些范例随后被提供在LLM提示中,以输出最终的关系。我们进一步将HYDRE扩展到跨语言设置,用于低资源语言的关系抽取。使用现有的英语DSRE训练数据,我们评估了所有方法在英语以及新策划的涵盖四种不同的低资源印度语言(奥里亚语、桑塔利语、曼尼普尔语和图卢语)的基准上。HYDRE在英语上实现了高达20 F1点的增益,并且在印度语言上平均比之前的SoTA DSRE模型高出17 F1点。详细的消融实验展示了HYDRE与其他提示策略相比的有效性。
🔬 方法详解
问题定义:远程监督关系抽取(DSRE)旨在从大规模文本数据中自动学习实体之间的关系。然而,远程监督数据通常包含噪声标注,即一个实体对可能被错误地标注为某种关系。现有的DSRE模型虽然在特定任务上表现良好,但缺乏与大型语言模型(LLM)的有效集成,无法充分利用LLM的知识和推理能力。此外,直接使用LLM进行关系抽取容易受到噪声标注的影响,导致关系语义学习不准确。
核心思路:HYDRE的核心思路是结合传统DSRE模型和LLM的优势,利用DSRE模型初步筛选候选关系,然后通过动态范例检索为LLM提供高质量的上下文信息,从而提高关系抽取的准确性和鲁棒性。这种混合方法旨在减轻噪声标注对LLM的影响,并充分利用LLM的泛化能力。
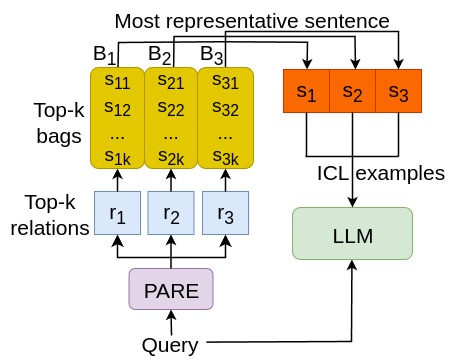
技术框架:HYDRE框架主要包含以下几个阶段: 1. DSRE模型预测:使用预训练的DSRE模型对输入句子进行关系预测,得到top-k个候选关系。 2. 动态范例检索:根据输入句子和候选关系,从训练数据中检索与输入句子语义相似且关系标注可靠的范例句子。检索策略旨在选择信息量大且与当前句子相关的范例。 3. LLM提示:将检索到的范例句子和输入句子一起构建成LLM的提示,要求LLM预测输入句子的关系。 4. 关系预测:LLM根据提示进行关系预测,输出最终的关系抽取结果。
关键创新:HYDRE的关键创新在于动态范例检索策略。传统的上下文学习方法通常使用固定的范例集,或者随机选择范例。而HYDRE根据输入句子和候选关系动态地选择范例,确保LLM能够获得与当前任务最相关的上下文信息。这种动态选择策略能够有效提高LLM的性能,并减轻噪声标注的影响。
关键设计:动态范例检索策略是HYDRE的关键设计。具体来说,该策略使用句子嵌入和关系嵌入来衡量句子和关系之间的相似度。检索过程包括以下步骤: 1. 计算输入句子和训练集中所有句子的句子嵌入。 2. 对于每个候选关系,计算该关系的关系嵌入。 3. 对于每个训练句子,计算其句子嵌入与关系嵌入的相似度。 4. 选择相似度最高的top-n个训练句子作为范例。
🖼️ 关键图片
📊 实验亮点
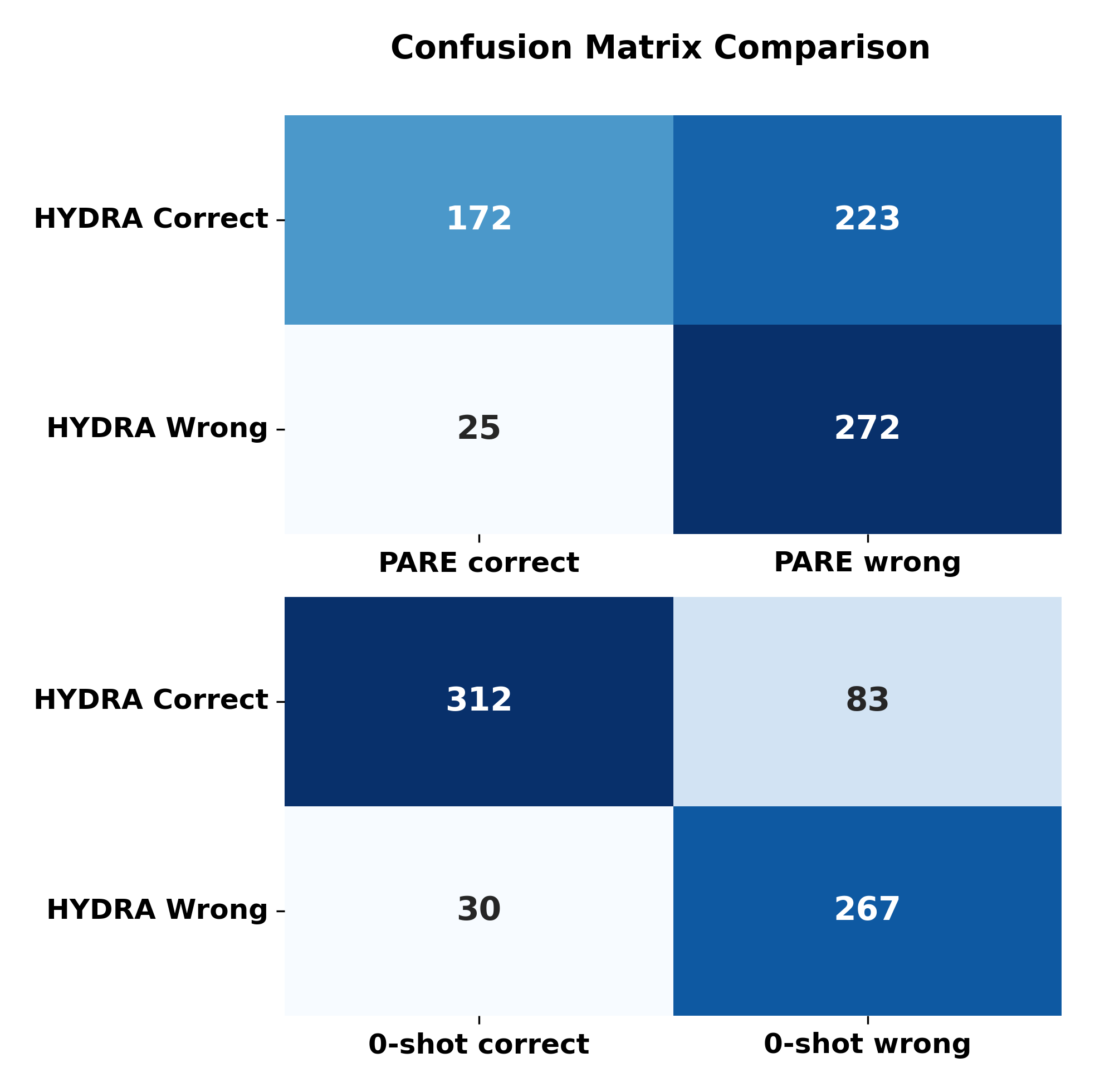
HYDRE在英语和四种低资源印度语言(奥里亚语、桑塔利语、曼尼普尔语和图卢语)上进行了评估。实验结果表明,HYDRE在英语上实现了高达20 F1点的增益,在印度语言上平均比之前的SoTA DSRE模型高出17 F1点。消融实验验证了动态范例检索策略的有效性。
🎯 应用场景
HYDRE框架可应用于各种需要关系抽取的场景,例如知识图谱构建、信息检索、问答系统等。尤其在低资源语言环境下,HYDRE能够有效利用现有的英语数据,提升跨语言关系抽取的性能,具有重要的实际应用价值。未来,该方法可以进一步扩展到其他NLP任务,例如事件抽取、情感分析等。
📄 摘要(原文)
Distantly Supervised Relation Extraction (DSRE) remains a long-standing challenge in NLP, where models must learn from noisy bag-level annotations while making sentence-level predictions. While existing state-of-the-art (SoTA) DSRE models rely on task-specific training, their integration with in-context learning (ICL) using large language models (LLMs) remains underexplored. A key challenge is that the LLM may not learn relation semantics correctly, due to noisy annotation. In response, we propose HYDRE -- HYbrid Distantly Supervised Relation Extraction framework. It first uses a trained DSRE model to identify the top-k candidate relations for a given test sentence, then uses a novel dynamic exemplar retrieval strategy that extracts reliable, sentence-level exemplars from training data, which are then provided in LLM prompt for outputting the final relation(s). We further extend HYDRE to cross-lingual settings for RE in low-resource languages. Using available English DSRE training data, we evaluate all methods on English as well as a newly curated benchmark covering four diverse low-resource Indic languages -- Oriya, Santali, Manipuri, and Tulu. HYDRE achieves up to 20 F1 point gains in English and, on average, 17 F1 points on Indic languages over prior SoTA DSRE models. Detailed ablations exhibit HYDRE's efficacy compared to other prompting strategies.