ECG-LLM -- training and evaluation of domain-specific large language models for electrocardiography
作者: Lara Ahrens, Wilhelm Haverkamp, Nils Strodthoff
分类: cs.CL, cs.LG
发布日期: 2025-10-21
备注: 34 pages, 8 figures, code available at https://github.com/AI4HealthUOL/ecg-llm
💡 一句话要点
ECG-LLM:心电图领域专用大语言模型的训练与评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心电图 大语言模型 领域自适应 微调 检索增强生成
📋 核心要点
- 现有通用LLM在医疗领域的应用面临隐私和部署挑战,需要领域自适应的开源模型。
- 通过在心电图文献上微调开源LLM,并结合RAG,提升模型在特定任务上的性能。
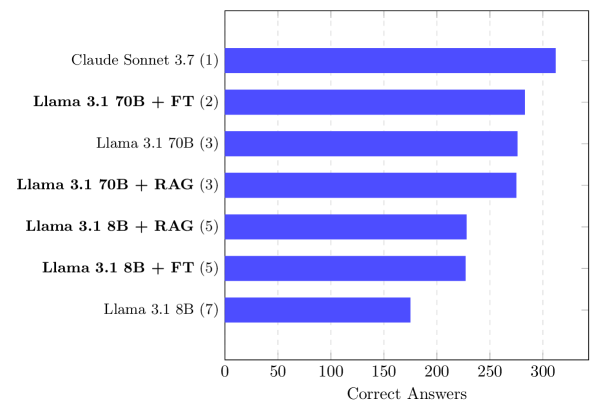
- 实验表明,微调后的Llama 3.1 70B在多项评估中表现出色,接近甚至超越通用模型。
📝 摘要(中文)
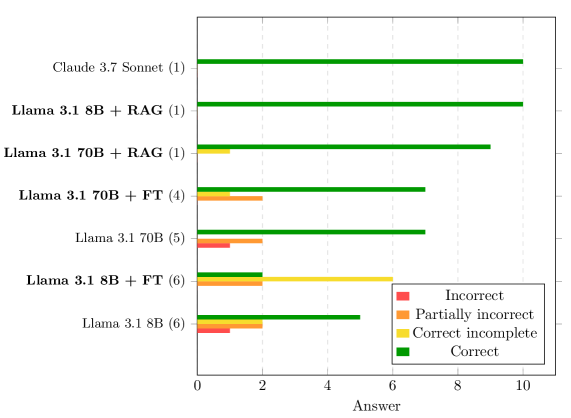
本文研究了领域自适应的开源大语言模型(LLM)在医疗保健领域的应用,重点关注心电图(ECG)领域。通过在领域特定文献上微调开源模型,并实施多层评估框架,对比了微调模型、检索增强生成(RAG)以及通用模型Claude Sonnet 3.7的性能。结果表明,微调后的Llama 3.1 70B在多项选择评估和自动文本指标上表现优异,在LLM-as-a-judge评估中仅次于Claude 3.7。人类专家评估更倾向于Claude 3.7和RAG方法处理复杂查询。微调模型在几乎所有评估模式下均显著优于其基础模型。研究揭示了评估方法之间存在显著的性能异质性,强调了评估的复杂性。总之,通过微调和RAG实现的领域特定适应能够与专有模型竞争,支持了具有隐私保护、可本地部署的临床解决方案的可行性。
🔬 方法详解
问题定义:论文旨在解决心电图领域缺乏高性能、可本地部署且隐私保护的大语言模型的问题。现有通用LLM虽然强大,但在处理专业医学知识时表现不足,且存在数据安全风险。领域自适应模型能够更好地理解和处理心电图相关信息,但如何有效训练和评估这些模型仍然是一个挑战。
核心思路:论文的核心思路是通过在心电图领域的专业文献上微调开源大语言模型,使其具备更强的领域知识和推理能力。同时,结合检索增强生成(RAG)技术,进一步提升模型在处理复杂查询时的性能。通过多层评估框架,全面评估微调模型、RAG以及通用模型的性能。
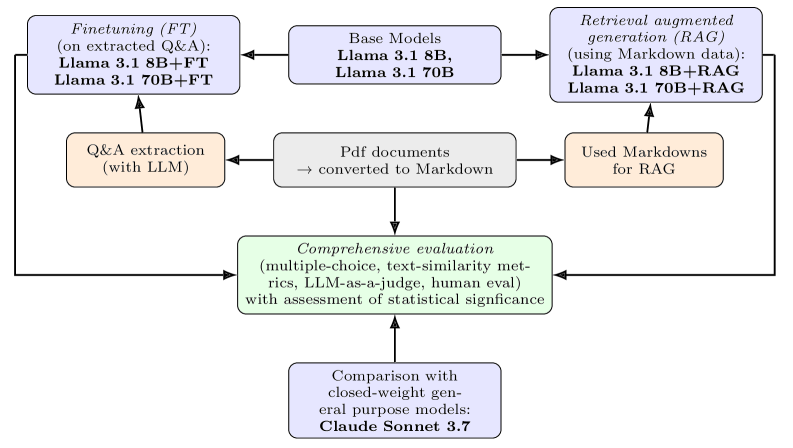
技术框架:整体框架包括数据收集与预处理、模型微调、RAG构建和多层评估四个主要阶段。首先,收集心电图领域的文献数据,并进行清洗和格式化。然后,选择合适的开源LLM(如Llama 3.1)进行微调,使其适应心电图领域的语言风格和知识体系。接着,构建RAG系统,利用检索模块从知识库中检索相关信息,并将其融入生成过程中。最后,通过多项选择评估、自动文本指标评估、LLM-as-a-judge评估和人类专家评估等多种方式,全面评估模型的性能。
关键创新:论文的关键创新在于针对心电图领域,系统性地研究了领域自适应LLM的训练和评估方法。通过对比微调模型、RAG和通用模型的性能,揭示了不同评估方法之间的差异,并验证了领域自适应方法在保护隐私的前提下,能够实现与专有模型相媲美的性能。
关键设计:论文采用了Llama 3.1 70B作为基础模型进行微调,并使用了领域特定的数据集进行训练。RAG系统的检索模块采用了基于向量相似度的检索方法,生成模块则利用微调后的LLM。在评估方面,采用了多种评估指标,包括准确率、BLEU、ROUGE等自动文本指标,以及LLM-as-a-judge和人类专家评估等主观评估方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,微调后的Llama 3.1 70B在多项选择评估和自动文本指标上表现优异,在LLM-as-a-judge评估中仅次于Claude 3.7。微调模型在几乎所有评估模式下均显著优于其基础模型。这些结果验证了领域自适应方法在心电图领域的有效性,并为构建隐私保护的临床解决方案提供了有力支持。
🎯 应用场景
该研究成果可应用于智能心电图诊断、辅助临床决策、医学知识问答等领域。通过本地部署领域自适应LLM,可以保护患者隐私,并为医生提供更准确、高效的诊断支持。未来,该技术有望推广到其他医学领域,推动医疗智能化发展。
📄 摘要(原文)
Domain-adapted open-weight large language models (LLMs) offer promising healthcare applications, from queryable knowledge bases to multimodal assistants, with the crucial advantage of local deployment for privacy preservation. However, optimal adaptation strategies, evaluation methodologies, and performance relative to general-purpose LLMs remain poorly characterized. We investigated these questions in electrocardiography, an important area of cardiovascular medicine, by finetuning open-weight models on domain-specific literature and implementing a multi-layered evaluation framework comparing finetuned models, retrieval-augmented generation (RAG), and Claude Sonnet 3.7 as a representative general-purpose model. Finetuned Llama 3.1 70B achieved superior performance on multiple-choice evaluations and automatic text metrics, ranking second to Claude 3.7 in LLM-as-a-judge assessments. Human expert evaluation favored Claude 3.7 and RAG approaches for complex queries. Finetuned models significantly outperformed their base counterparts across nearly all evaluation modes. Our findings reveal substantial performance heterogeneity across evaluation methodologies, underscoring assessment complexity. Nevertheless, domain-specific adaptation through finetuning and RAG achieves competitive performance with proprietary models, supporting the viability of privacy-preserving, locally deployable clinical solutions.