Position: LLM Watermarking Should Align Stakeholders' Incentives for Practical Adoption
作者: Yepeng Liu, Xuandong Zhao, Dawn Song, Gregory W. Wornell, Yuheng Bu
分类: cs.CR, cs.CL
发布日期: 2025-10-21
💡 一句话要点
提出激励对齐的LLM水印方案,促进实际应用落地
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM水印 激励对齐 上下文水印 滥用检测 学术诚信
📋 核心要点
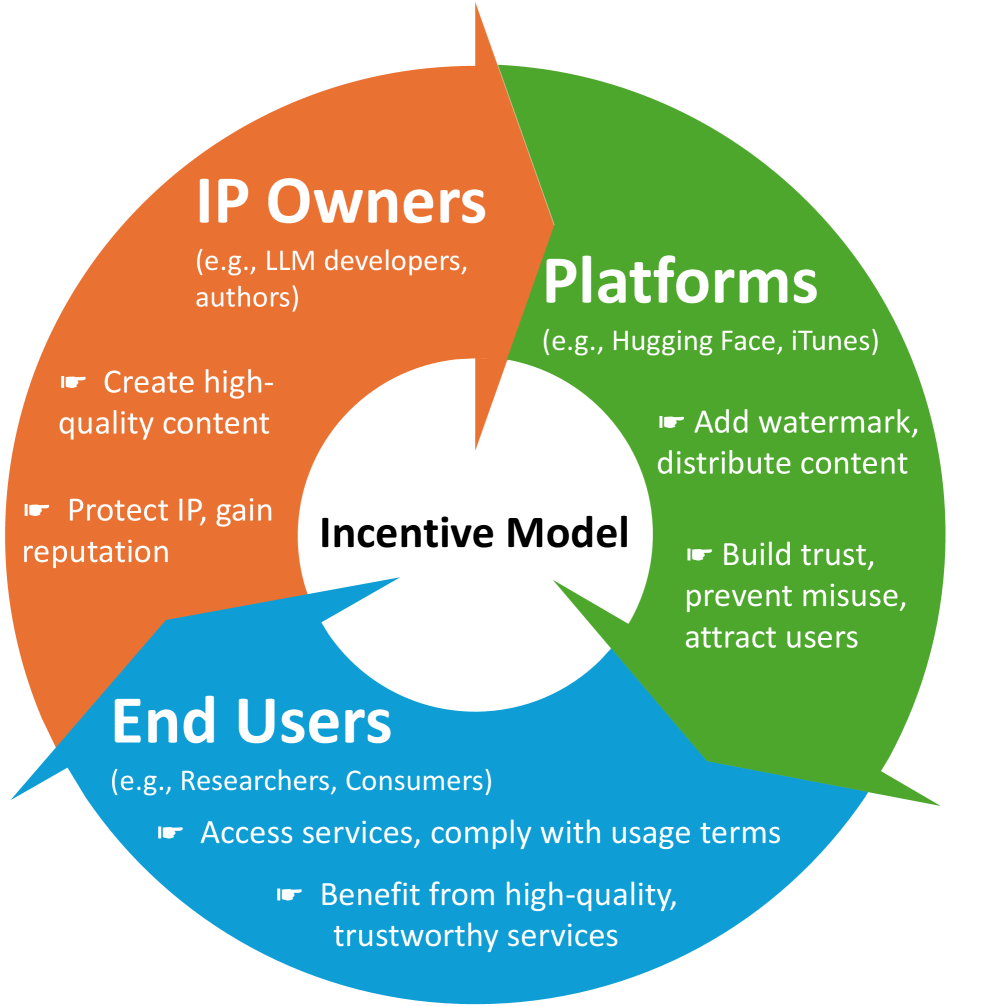
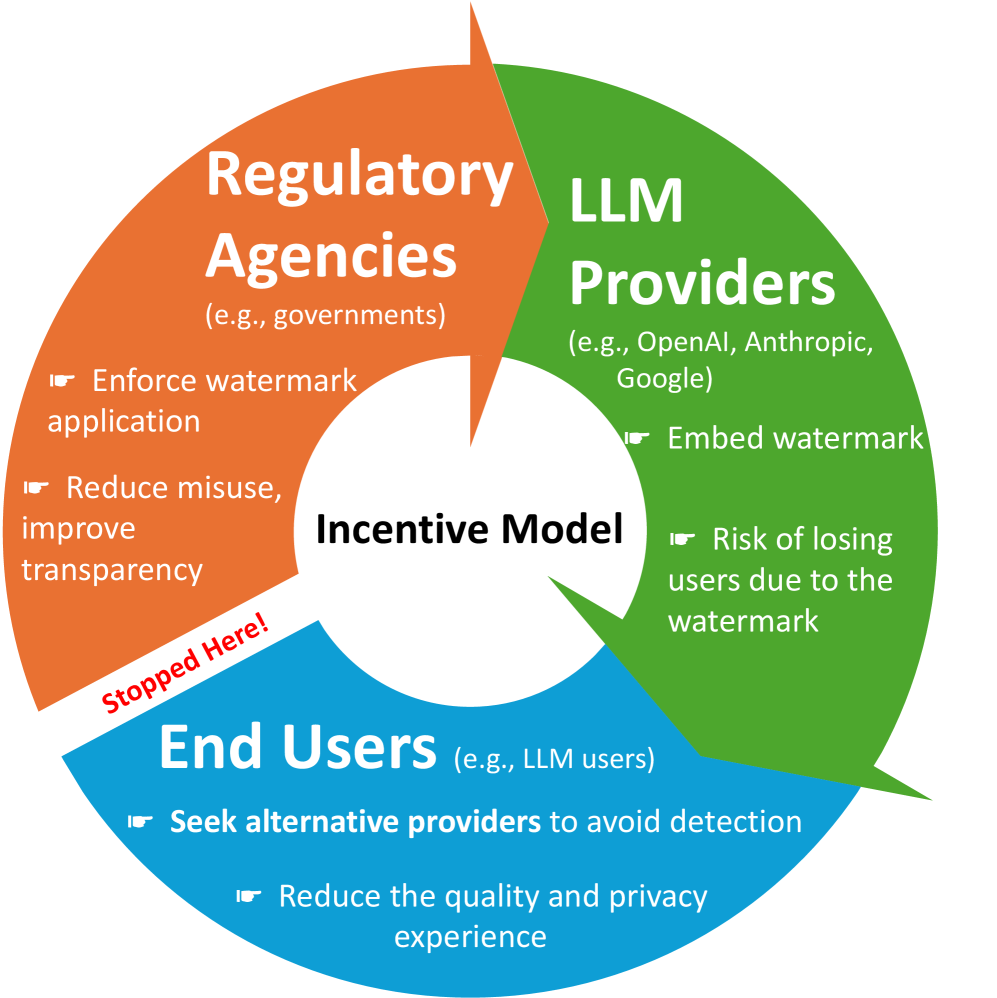
- 现有LLM水印算法部署受限,主要挑战在于LLM提供商、平台和用户之间的激励不一致。
- 论文提出激励对齐的水印方法,例如上下文水印(ICW),以解决特定场景下的滥用检测问题。
- ICW通过在文档中嵌入隐藏水印指令,使LLM输出带有可检测的水印,从而实现滥用溯源。
📝 摘要(中文)
尽管大型语言模型(LLM)的水印算法取得了进展,但实际部署仍然有限。我们认为,这种差距源于LLM提供商、平台和最终用户之间的激励不一致,这表现为四个关键障碍:竞争风险、检测工具治理、鲁棒性问题和归属问题。我们通过这个视角重新审视了三类水印技术。模型水印自然符合LLM提供商的利益,但在开源生态系统中面临新的挑战。LLM文本水印如果仅被视为一种反滥用工具,对提供商的益处有限,但在数据集去污染或用户控制的出处等狭窄范围内可以获得吸引力。上下文水印(ICW)专为可信方(如会议组织者或教育工作者)定制,他们将隐藏的水印指令嵌入到文档中。如果不诚实的审稿人或学生将此文本提交给LLM,则输出将带有可检测的水印,表明存在滥用行为。这种设置对齐了激励:用户不会体验到质量损失,可信方获得检测工具,LLM提供商通过简单地遵循水印指令保持中立。我们提倡更广泛地探索激励对齐的方法,以ICW为例,在可信方需要可靠工具来检测滥用的领域中应用。更广泛地说,我们提炼了激励对齐的、特定领域水印的设计原则,并概述了未来的研究方向。我们的立场是,LLM水印的实际应用需要在目标应用领域中对齐利益相关者的激励,并促进积极的社区参与。
🔬 方法详解
问题定义:现有LLM水印技术在实际应用中面临挑战,因为LLM提供商、平台和最终用户之间的激励不一致。例如,LLM提供商可能担心水印会影响模型性能或暴露专有信息,平台可能缺乏有效的检测工具治理机制,而最终用户可能不愿接受水印带来的质量损失。这些问题导致水印技术难以大规模部署和应用。
核心思路:论文的核心思路是设计激励对齐的水印方案,使LLM提供商、平台和最终用户都能从中受益。通过将水印技术与特定应用场景相结合,并明确各方的责任和利益,可以有效解决现有水印技术面临的挑战。例如,上下文水印(ICW)通过在文档中嵌入水印指令,使可信方能够检测LLM的滥用行为,从而实现激励对齐。
技术框架:论文主要讨论了三种类型的水印技术:模型水印、LLM文本水印和上下文水印(ICW)。模型水印旨在保护LLM的知识产权,LLM文本水印旨在防止LLM生成有害内容,而ICW旨在检测LLM的滥用行为。ICW的技术框架包括:1) 可信方在文档中嵌入水印指令;2) 用户将文档提交给LLM;3) LLM按照水印指令生成带有水印的文本;4) 可信方使用检测工具检测文本中的水印,从而判断是否存在滥用行为。
关键创新:论文的关键创新在于提出了激励对齐的水印设计原则,并以上下文水印(ICW)为例,展示了如何将这些原则应用于实际场景中。与传统的LLM水印技术相比,ICW更加注重各方的利益,并提供了一种更加灵活和可控的水印方案。
关键设计:ICW的关键设计包括:1) 水印指令的设计,需要确保LLM能够正确理解和执行;2) 水印检测算法的设计,需要确保能够准确检测文本中的水印,同时避免误报;3) 激励机制的设计,需要确保各方都有动力参与水印过程。
🖼️ 关键图片

📊 实验亮点
论文提出了上下文水印(ICW)的概念,并展示了其在学术诚信检测中的应用潜力。ICW通过在文档中嵌入水印指令,使LLM输出带有可检测的水印,从而实现滥用溯源。这种方法不仅可以有效检测LLM的滥用行为,还可以保护可信方的利益,并促进LLM的健康发展。
🎯 应用场景
该研究成果可应用于学术诚信检测、版权保护、内容溯源等领域。例如,会议组织者可以使用ICW来检测审稿人是否使用LLM撰写评审意见,教育机构可以使用ICW来检测学生是否使用LLM完成作业。通过激励对齐的水印方案,可以有效提高LLM水印技术的实际应用价值,并促进LLM的健康发展。
📄 摘要(原文)
Despite progress in watermarking algorithms for large language models (LLMs), real-world deployment remains limited. We argue that this gap stems from misaligned incentives among LLM providers, platforms, and end users, which manifest as four key barriers: competitive risk, detection-tool governance, robustness concerns and attribution issues. We revisit three classes of watermarking through this lens. \emph{Model watermarking} naturally aligns with LLM provider interests, yet faces new challenges in open-source ecosystems. \emph{LLM text watermarking} offers modest provider benefit when framed solely as an anti-misuse tool, but can gain traction in narrowly scoped settings such as dataset de-contamination or user-controlled provenance. \emph{In-context watermarking} (ICW) is tailored for trusted parties, such as conference organizers or educators, who embed hidden watermarking instructions into documents. If a dishonest reviewer or student submits this text to an LLM, the output carries a detectable watermark indicating misuse. This setup aligns incentives: users experience no quality loss, trusted parties gain a detection tool, and LLM providers remain neutral by simply following watermark instructions. We advocate for a broader exploration of incentive-aligned methods, with ICW as an example, in domains where trusted parties need reliable tools to detect misuse. More broadly, we distill design principles for incentive-aligned, domain-specific watermarking and outline future research directions. Our position is that the practical adoption of LLM watermarking requires aligning stakeholder incentives in targeted application domains and fostering active community engagement.