BrailleLLM: Braille Instruction Tuning with Large Language Models for Braille Domain Tasks
作者: Tianyuan Huang, Zepeng Zhu, Hangdi Xing, Zirui Shao, Zhi Yu, Chaoxiong Yang, Jiaxian He, Xiaozhong Liu, Jiajun Bu
分类: cs.CL
发布日期: 2025-10-21
备注: Accepted to EMNLP 2025
💡 一句话要点
BrailleLLM:通过大型语言模型和盲文指令调优,解决盲文领域任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 盲文 大型语言模型 指令调优 知识微调 数据增强
📋 核心要点
- 盲文数据稀缺和混合文本歧义给盲文信息处理带来挑战,传统微调方法效果不佳。
- 论文提出基于盲文知识的微调(BKFT),降低盲文特征学习难度,并结合指令调优。
- 实验表明,BKFT在盲文翻译任务上显著优于传统微调,为低资源盲文研究奠定基础。
📝 摘要(中文)
盲文在视障人士的教育和信息可访问性方面起着至关重要的作用。然而,盲文信息处理面临着数据稀缺和混合文本上下文中存在歧义等挑战。我们构建了包含数学公式的英语和中文盲文混合数据集(EBMD/CBMD),以支持多样化的盲文领域研究,并提出了一种针对盲文数据定制的基于语法树的增强方法。为了解决传统微调方法在盲文相关任务中的表现不佳问题,我们研究了基于盲文知识的微调(BKFT),它降低了盲文上下文特征的学习难度。BrailleLLM通过指令调优采用BKFT,以实现统一的盲文翻译、公式到盲文的转换和混合文本翻译。实验表明,在盲文翻译场景中,BKFT比传统的微调方法取得了显著的性能提升。我们开源的数据集和方法为低资源多语种盲文研究奠定了基础。
🔬 方法详解
问题定义:论文旨在解决盲文信息处理中数据稀缺和混合文本歧义的问题,以及传统微调方法在盲文相关任务中表现不佳的痛点。现有方法难以有效学习盲文的上下文特征,导致翻译和转换效果不理想。
核心思路:论文的核心思路是利用盲文领域的知识,通过一种特殊的微调方法(BKFT)来引导大型语言模型更好地学习盲文的特征表示。通过指令调优,使模型能够统一处理盲文翻译、公式转换和混合文本翻译等多种任务。
技术框架:BrailleLLM的技术框架主要包括以下几个部分:首先,构建包含数学公式的英语和中文盲文混合数据集(EBMD/CBMD);其次,提出基于语法树的盲文数据增强方法;然后,采用基于盲文知识的微调(BKFT)方法;最后,通过指令调优将BKFT应用于大型语言模型,实现统一的盲文处理能力。
关键创新:论文的关键创新在于提出了基于盲文知识的微调(BKFT)方法。BKFT通过引入盲文领域的知识,例如盲文的结构和规则,来指导模型的微调过程,从而降低了学习盲文上下文特征的难度。这与传统的微调方法不同,后者通常直接在目标任务上进行微调,而忽略了领域知识的重要性。
关键设计:论文的关键设计包括:1) 基于语法树的盲文数据增强方法,用于扩充训练数据;2) BKFT的具体实现方式,可能涉及到特定的损失函数设计或网络结构调整,以更好地融入盲文知识;3) 指令调优的具体指令设计,用于指导模型学习不同类型的盲文任务。
🖼️ 关键图片


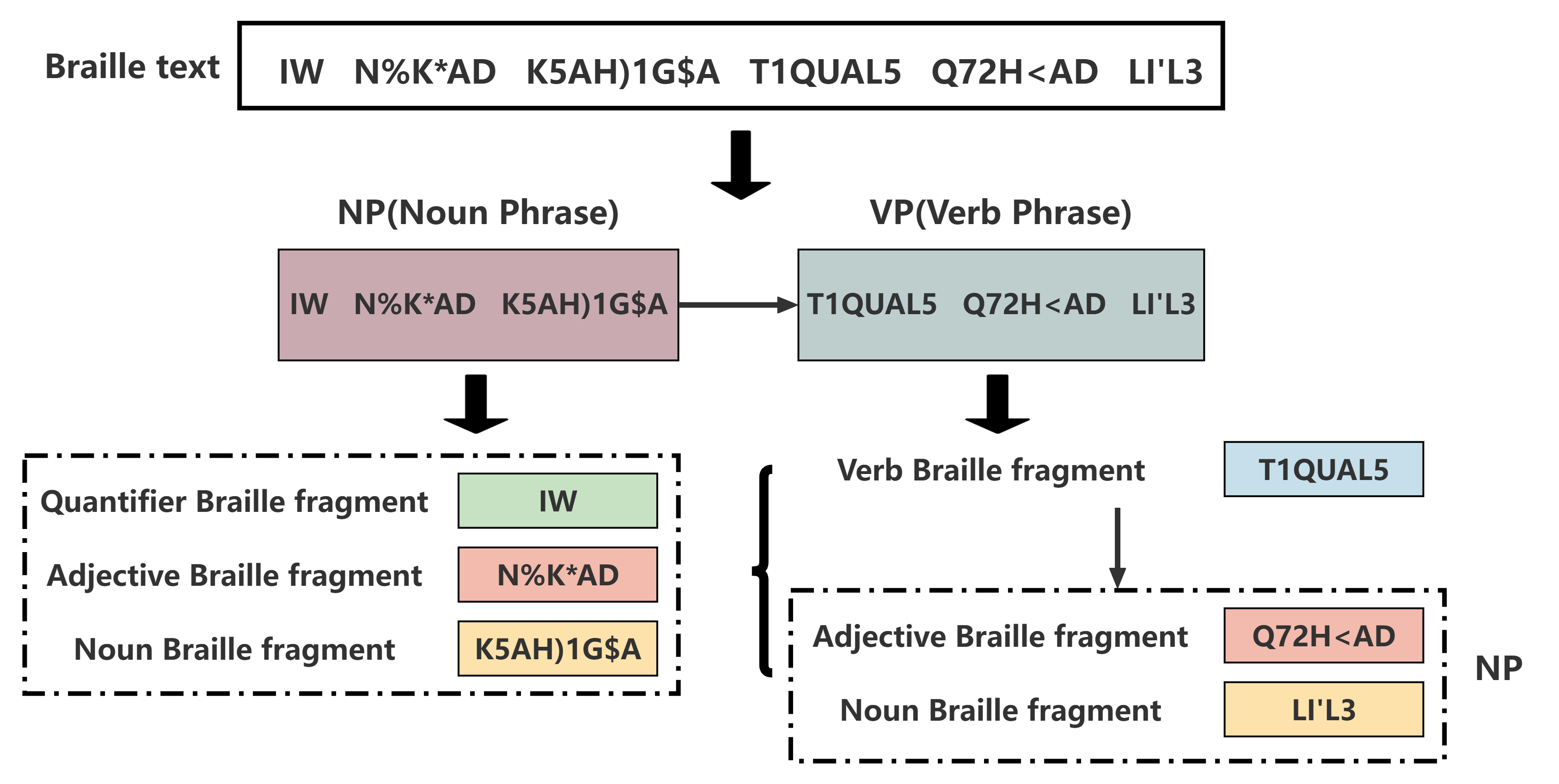
📊 实验亮点
实验结果表明,基于盲文知识的微调(BKFT)方法在盲文翻译场景中显著优于传统的微调方法。具体的性能数据和提升幅度需要在论文中查找,但摘要明确指出BKFT取得了“显著的性能提升”。该结果验证了BKFT的有效性,并为盲文领域的模型微调提供了新的思路。
🎯 应用场景
该研究成果可应用于开发更高效的盲文翻译工具、数学公式到盲文的转换系统,以及支持混合文本的盲文阅读器。这些应用能够显著提升视障人士获取信息和接受教育的便利性,促进信息无障碍化,并为未来的多语种盲文研究提供基础。
📄 摘要(原文)
Braille plays a vital role in education and information accessibility for visually impaired individuals. However, Braille information processing faces challenges such as data scarcity and ambiguities in mixed-text contexts. We construct English and Chinese Braille Mixed Datasets (EBMD/CBMD) with mathematical formulas to support diverse Braille domain research, and propose a syntax tree-based augmentation method tailored for Braille data. To address the underperformance of traditional fine-tuning methods in Braille-related tasks, we investigate Braille Knowledge-Based Fine-Tuning (BKFT), which reduces the learning difficulty of Braille contextual features. BrailleLLM employs BKFT via instruction tuning to achieve unified Braille translation, formula-to-Braille conversion, and mixed-text translation. Experiments demonstrate that BKFT achieves significant performance improvements over conventional fine-tuning in Braille translation scenarios. Our open-sourced datasets and methodologies establish a foundation for low-resource multilingual Braille research.