Text or Pixels? It Takes Half: On the Token Efficiency of Visual Text Inputs in Multimodal LLMs
作者: Yanhong Li, Zixuan Lan, Jiawei Zhou
分类: cs.CL, cs.AI
发布日期: 2025-10-21 (更新: 2025-10-22)
备注: Accepted to EMNLP 2025 Findings ("Text or Pixels? Evaluating Efficiency and Understanding of LLMs with Visual Text Inputs")
💡 一句话要点
提出文本图像化压缩方法,在多模态LLM中降低Token使用量并保持性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 文本压缩 视觉文本 长文本处理 Token效率
📋 核心要点
- 现有方法在处理长文本时,需要消耗大量的token,增加了计算成本和模型负担。
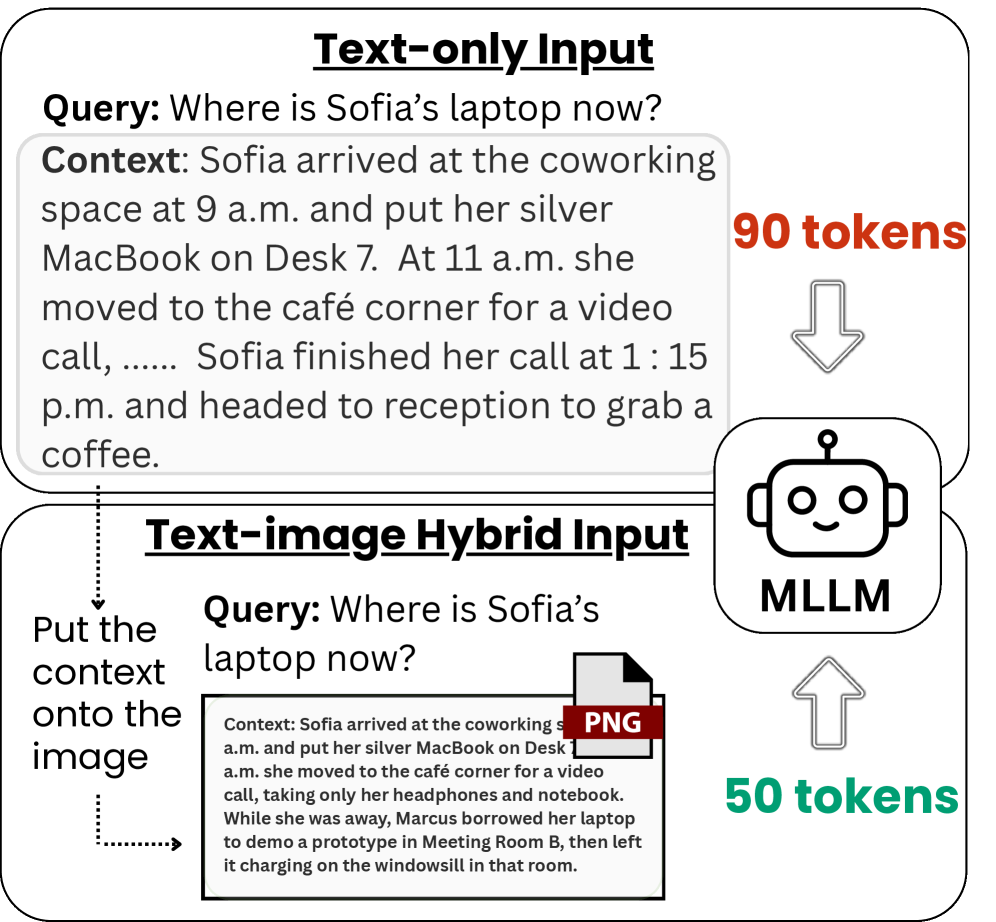
- 论文提出将长文本渲染为图像,并将其作为视觉输入提供给多模态LLM,以减少token使用量。
- 实验表明,该方法在长文本检索和文档摘要任务中,能够显著节省token,同时保持甚至提升性能。
📝 摘要(中文)
大型语言模型(LLMs)及其多模态变体现在可以处理视觉输入,包括文本图像。这引出了一个有趣的问题:我们能否通过将文本输入渲染为图像来压缩文本输入,从而减少token的使用,同时保持性能?在本文中,我们表明,视觉文本表示是一种实用且出人意料地有效的解码器LLM输入压缩形式。我们利用将长文本输入渲染为单个图像并将其直接提供给模型的想法。这显著减少了所需的解码器token数量,提供了一种新的输入压缩形式。通过在两个不同的基准测试RULER(长上下文检索)和CNN/DailyMail(文档摘要)上的实验,我们证明了这种文本图像化方法可以节省大量token(通常接近一半),而不会降低任务性能。
🔬 方法详解
问题定义:现有的大型语言模型在处理长文本输入时,需要将文本分解为大量的token,这导致了计算资源的浪费和处理效率的降低。尤其是在多模态LLM中,文本token的消耗与图像token的消耗叠加,使得长文本处理的成本更加高昂。因此,如何在不损失性能的前提下,减少长文本输入的token数量,是一个亟待解决的问题。
核心思路:论文的核心思路是将文本转换为图像,利用图像的压缩特性来减少输入LLM的token数量。具体来说,就是将长文本渲染成一张图像,然后将这张图像作为视觉输入提供给多模态LLM。由于图像可以被压缩成相对较少的token,因此可以有效地降低输入LLM的token数量。同时,多模态LLM具备处理图像信息的能力,因此可以从文本图像中提取出文本信息,用于后续的任务处理。
技术框架:该方法的技术框架主要包括两个步骤:首先,将长文本输入渲染成一张图像。这一步可以使用各种文本渲染技术,例如将文本按照一定的格式排版,然后将其转换为图像。其次,将渲染后的图像作为视觉输入提供给多模态LLM。多模态LLM利用其视觉处理能力,从图像中提取出文本信息,并将其用于后续的任务处理,例如长文本检索和文档摘要。
关键创新:该方法最重要的技术创新点在于,它将文本压缩问题转化为图像压缩问题,利用图像的压缩特性来减少输入LLM的token数量。与传统的文本压缩方法相比,该方法更加简单有效,并且可以与现有的多模态LLM无缝集成。此外,该方法还探索了一种新的文本表示方式,即文本图像,为未来的文本处理研究提供了新的思路。
关键设计:在文本渲染方面,论文可能采用了某种特定的字体、字号和排版方式,以保证渲染后的图像能够清晰地表达文本信息。在多模态LLM方面,论文可能需要对模型进行微调,以使其更好地适应文本图像输入。此外,论文还需要设计合适的损失函数,以保证模型能够从文本图像中准确地提取出文本信息。具体的参数设置、损失函数和网络结构等技术细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
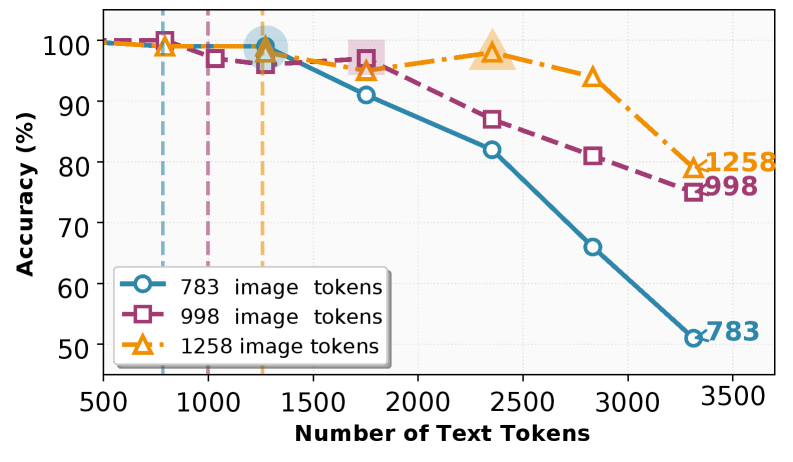
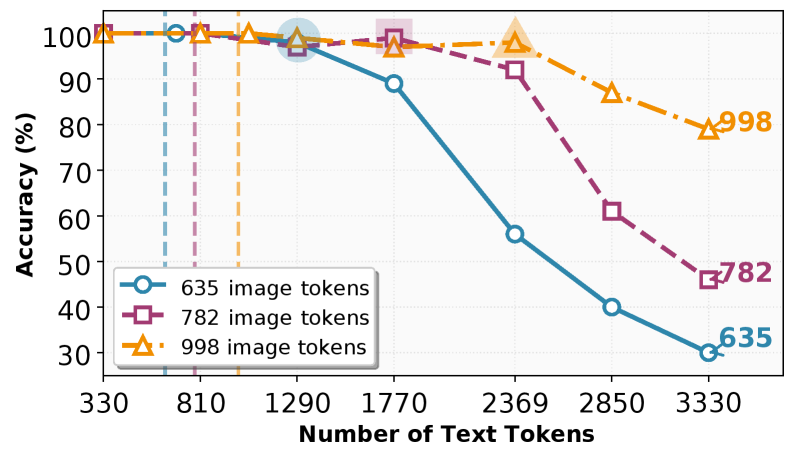
实验结果表明,该方法在RULER(长上下文检索)和CNN/DailyMail(文档摘要)两个基准测试上,能够节省接近一半的token,同时保持甚至提升任务性能。这证明了文本图像化压缩方法的有效性和实用性,为多模态LLM的输入压缩提供了一种新的解决方案。
🎯 应用场景
该研究成果可广泛应用于需要处理长文本的多模态LLM应用场景,例如文档摘要、信息检索、问答系统等。通过减少token使用量,可以降低计算成本,提高处理效率,并支持更大规模的文本处理任务。未来,该方法还可以扩展到其他类型的文本输入,例如代码、表格等,进一步提升多模态LLM的性能和应用范围。
📄 摘要(原文)
Large language models (LLMs) and their multimodal variants can now process visual inputs, including images of text. This raises an intriguing question: can we compress textual inputs by feeding them as images to reduce token usage while preserving performance? In this paper, we show that visual text representations are a practical and surprisingly effective form of input compression for decoder LLMs. We exploit the idea of rendering long text inputs as a single image and provide it directly to the model. This leads to dramatically reduced number of decoder tokens required, offering a new form of input compression. Through experiments on two distinct benchmarks RULER (long-context retrieval) and CNN/DailyMail (document summarization) we demonstrate that this text-as-image method yields substantial token savings (often nearly half) without degrading task performance.