DelvePO: Direction-Guided Self-Evolving Framework for Flexible Prompt Optimization
作者: Tao Tao, Guanghui Zhu, Lang Guo, Hongyi Chen, Chunfeng Yuan, Yihua Huang
分类: cs.CL, cs.AI
发布日期: 2025-10-21
💡 一句话要点
DelvePO:面向灵活提示优化的方向引导自进化框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示优化 大型语言模型 自进化学习 方向引导 任务无关 工作记忆 提示解耦
📋 核心要点
- 现有提示优化方法依赖LLM的随机性,易陷入局部最优,且优化后的提示泛化能力不足。
- DelvePO通过解耦提示成分,引入工作记忆,引导LLM自进化生成更优提示,提升优化稳定性和泛化性。
- 实验表明,DelvePO在多种任务和LLM上均优于现有SOTA方法,验证了其有效性和跨任务迁移能力。
📝 摘要(中文)
提示优化已成为一种关键方法,因为它能够引导大型语言模型解决各种任务。然而,目前的工作主要依赖于LLM的随机重写能力,并且优化过程通常侧重于特定的影响因素,这使得它很容易陷入局部最优。此外,优化后的提示的性能通常不稳定,这限制了其在不同任务中的可迁移性。为了解决上述挑战,我们提出了DelvePO(用于灵活提示优化的方向引导自进化框架),这是一个任务无关的框架,以自进化方式优化提示。在我们的框架中,我们将提示分解为不同的组件,这些组件可用于探索不同因素可能对各种任务产生的影响。在此基础上,我们引入了工作记忆,通过它可以减轻LLM自身不确定性造成的缺陷,并进一步获得关键见解,以指导新提示的生成。在包括DeepSeek-R1-Distill-Llama-8B、Qwen2.5-7B-Instruct和GPT-4o-mini在内的各种领域中,针对开源和闭源LLM的不同任务进行了广泛的实验。实验结果表明,在相同的实验设置下,DelvePO始终优于以前的SOTA方法,证明了其在不同任务中的有效性和可迁移性。
🔬 方法详解
问题定义:当前提示优化方法主要依赖大型语言模型的随机重写能力,优化过程往往只关注特定因素,容易陷入局部最优解。此外,优化后的提示在不同任务上的性能不稳定,限制了其通用性。因此,需要一种更稳定、更具泛化能力的提示优化方法。
核心思路:DelvePO的核心思路是构建一个自进化的提示优化框架,该框架通过解耦提示的不同组成部分,并利用工作记忆来指导LLM生成新的提示。这种方法旨在克服LLM自身的不确定性,并探索不同因素对任务性能的影响,从而找到更优的提示。
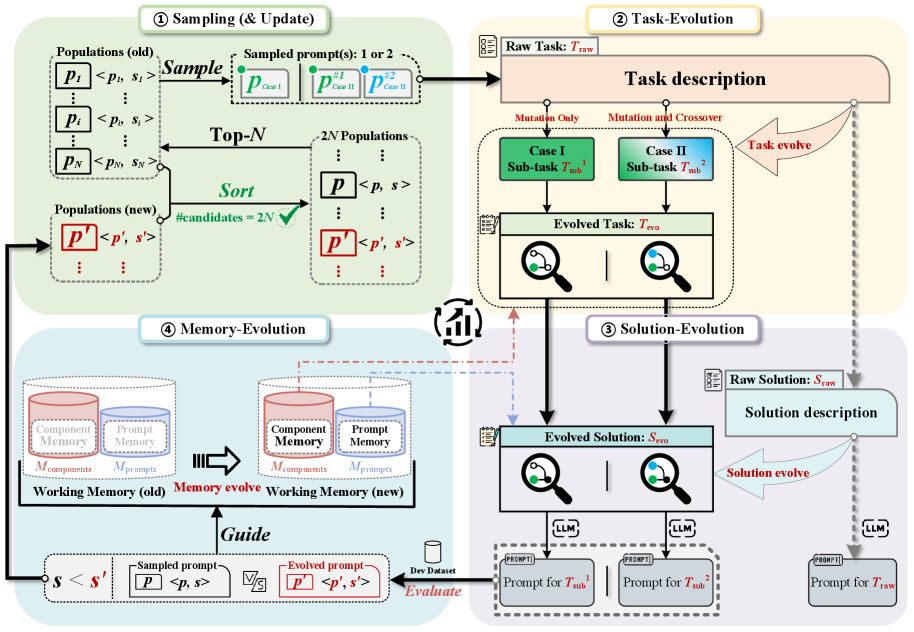
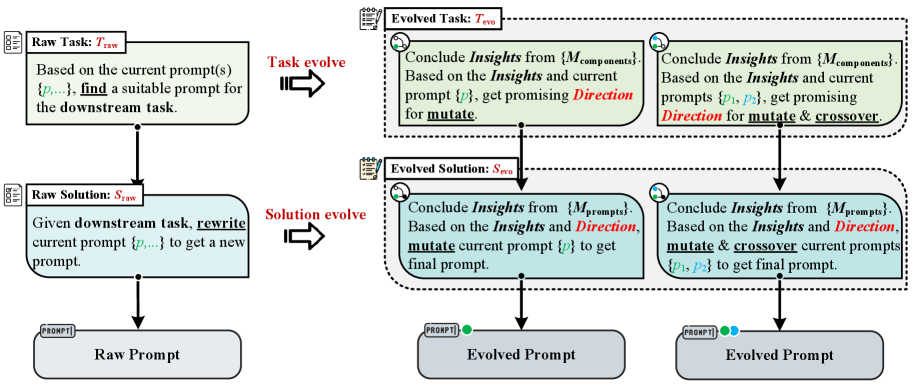
技术框架:DelvePO框架包含以下主要模块:1) 提示解耦:将提示分解为不同的组成部分,以便独立优化每个部分。2) 工作记忆:引入工作记忆机制,用于存储和利用LLM在优化过程中获得的知识和经验。3) 方向引导:利用工作记忆中的信息,引导LLM生成新的提示,避免陷入局部最优。4) 自进化:通过迭代优化过程,不断改进提示的性能。
关键创新:DelvePO的关键创新在于其方向引导的自进化优化机制。与传统的随机搜索方法不同,DelvePO利用工作记忆中的信息来指导提示的生成,从而更有效地探索提示空间。此外,DelvePO的提示解耦方法允许独立优化提示的不同组成部分,从而更好地理解不同因素对任务性能的影响。
关键设计:DelvePO的关键设计包括:1) 提示解耦策略:选择合适的提示解耦方法,将提示分解为有意义的组成部分。2) 工作记忆的实现:设计有效的工作记忆结构,用于存储和检索LLM在优化过程中获得的知识。3) 方向引导机制:设计合适的算法,利用工作记忆中的信息来引导LLM生成新的提示。4) 优化目标:选择合适的优化目标,例如任务的准确率或效率。
🖼️ 关键图片
📊 实验亮点
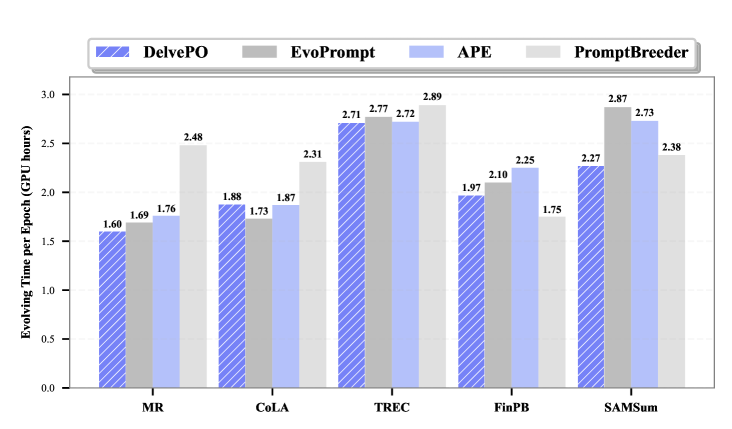
DelvePO在多个任务和LLM上进行了实验,包括DeepSeek-R1-Distill-Llama-8B、Qwen2.5-7B-Instruct和GPT-4o-mini。实验结果表明,在相同的实验设置下,DelvePO始终优于以前的SOTA方法,证明了其有效性和跨任务迁移能力。具体的性能提升幅度未知,但论文强调DelvePO在不同任务上均表现出一致的优越性。
🎯 应用场景
DelvePO可广泛应用于各种需要提示工程的场景,例如文本生成、问答系统、机器翻译等。通过自动优化提示,DelvePO可以显著提高LLM在这些任务上的性能,降低人工设计提示的成本,并促进LLM在更多领域的应用。未来,DelvePO有望成为一种通用的提示优化工具,帮助用户更好地利用LLM的能力。
📄 摘要(原文)
Prompt Optimization has emerged as a crucial approach due to its capabilities in steering Large Language Models to solve various tasks. However, current works mainly rely on the random rewriting ability of LLMs, and the optimization process generally focus on specific influencing factors, which makes it easy to fall into local optimum. Besides, the performance of the optimized prompt is often unstable, which limits its transferability in different tasks. To address the above challenges, we propose $\textbf{DelvePO}$ ($\textbf{D}$irection-Guid$\textbf{e}$d Se$\textbf{l}$f-E$\textbf{v}$olving Framework for Fl$\textbf{e}$xible $\textbf{P}$rompt $\textbf{O}$ptimization), a task-agnostic framework to optimize prompts in self-evolve manner. In our framework, we decouple prompts into different components that can be used to explore the impact that different factors may have on various tasks. On this basis, we introduce working memory, through which LLMs can alleviate the deficiencies caused by their own uncertainties and further obtain key insights to guide the generation of new prompts. Extensive experiments conducted on different tasks covering various domains for both open- and closed-source LLMs, including DeepSeek-R1-Distill-Llama-8B, Qwen2.5-7B-Instruct and GPT-4o-mini. Experimental results show that DelvePO consistently outperforms previous SOTA methods under identical experimental settings, demonstrating its effectiveness and transferability across different tasks.