Contrastive Decoding Mitigates Score Range Bias in LLM-as-a-Judge
作者: Yoshinari Fujinuma
分类: cs.CL, cs.AI
发布日期: 2025-10-21
💡 一句话要点
对比解码缓解LLM评分中的范围偏差,提升LLM作为裁判的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对比解码 评分范围偏差 LLM裁判 直接评估
📋 核心要点
- LLM作为裁判在直接评估中存在评分范围偏差,导致其对预定义评分范围过于敏感,影响评估的准确性和可靠性。
- 论文提出使用对比解码来缓解LLM裁判的评分范围偏差,通过对比不同解码策略的输出,减少模型对特定评分范围的依赖。
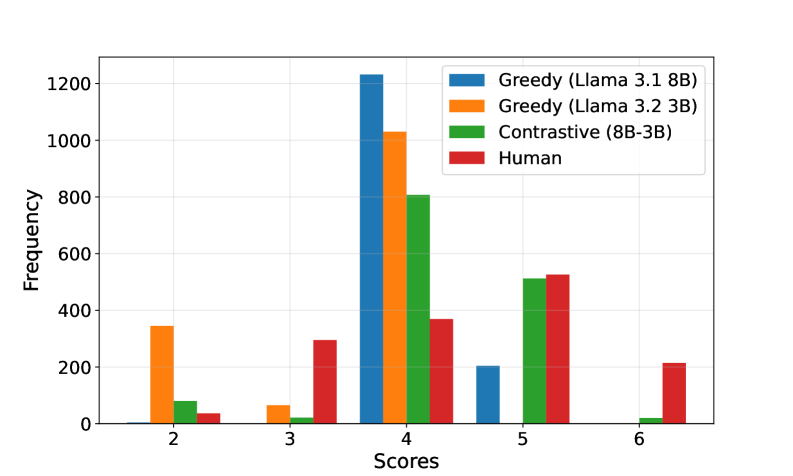
- 实验结果表明,对比解码能够有效降低评分范围偏差,在与人类判断的Spearman相关性上平均提升高达11.3%。
📝 摘要(中文)
大型语言模型(LLM)常被用作各种应用中的评估器,但结果的可靠性仍然是一个挑战。其中一个挑战是将LLM用作裁判进行直接评估,即在没有任何参考的情况下,从指定的范围内分配分数。本文首先表明,这一挑战源于LLM裁判输出与评分范围偏差相关,即LLM裁判输出对预定义的评分范围高度敏感,从而阻碍了最佳评分范围的搜索。本文还表明,来自同一模型的不同变体之间也存在类似的偏差。然后,通过对比解码来缓解这种偏差,在不同评分范围内,与人类判断的Spearman相关性平均提高了高达11.3%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)作为裁判进行直接评估时存在的评分范围偏差问题。现有方法中,LLM的评分结果高度依赖于预定义的评分范围,导致无法找到最优的评分范围,并且同一模型家族的不同变体也存在相似的偏差。这种偏差降低了LLM作为裁判的可靠性。
核心思路:论文的核心思路是利用对比解码来缓解LLM的评分范围偏差。对比解码通过比较不同解码策略(例如,使用不同的温度系数或采样方法)生成的输出,并选择与“基础”解码策略输出差异最大的结果。这种方法旨在减少模型对特定评分范围的过度依赖,从而提高评分的客观性和准确性。
技术框架:论文的技术框架主要包括以下几个步骤:1) 使用LLM作为裁判,对给定的文本生成评分;2) 使用不同的解码策略生成多个候选评分;3) 通过对比解码,选择与基础解码策略输出差异最大的评分;4) 将对比解码后的评分与人类判断进行比较,评估其性能。
关键创新:论文的关键创新在于将对比解码应用于缓解LLM评分中的范围偏差。与传统的解码方法相比,对比解码能够更好地探索模型的输出空间,减少模型对预定义评分范围的依赖,从而提高评分的准确性和可靠性。此外,论文还揭示了同一模型家族的不同变体之间也存在相似的偏差,为后续研究提供了新的视角。
关键设计:论文的关键设计包括:1) 选择合适的对比解码策略,例如,使用不同的温度系数或采样方法;2) 定义合适的差异度量函数,用于衡量不同解码策略输出之间的差异;3) 实验中使用了多种不同的评分范围,以评估对比解码的泛化能力。具体的参数设置和损失函数细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过对比解码,LLM评分与人类判断的Spearman相关性平均提高了高达11.3%。这一结果表明,对比解码能够有效缓解LLM评分中的范围偏差,提高LLM作为裁判的可靠性。此外,实验还验证了对比解码在不同评分范围下的泛化能力,进一步证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要使用LLM进行评估的场景,例如自动摘要评估、机器翻译质量评估、对话系统评估等。通过缓解LLM评分中的范围偏差,可以提高评估结果的准确性和可靠性,从而为相关应用提供更可靠的反馈和指导。未来,该方法还可以扩展到其他类型的LLM评估任务中,例如生成文本的流畅性和连贯性评估。
📄 摘要(原文)
Large Language Models (LLMs) are commonly used as evaluators in various applications, but the reliability of the outcomes remains a challenge. One such challenge is using LLMs-as-judges for direct assessment, i.e., assigning scores from a specified range without any references. We first show that this challenge stems from LLM judge outputs being associated with score range bias, i.e., LLM judge outputs are highly sensitive to pre-defined score ranges, preventing the search for optimal score ranges. We also show that similar biases exist among models from the same family. We then mitigate this bias through contrastive decoding, achieving up to 11.3% relative improvement on average in Spearman correlation with human judgments across different score ranges.