Automatic Prompt Generation via Adaptive Selection of Prompting Techniques
作者: Yohei Ikenoue, Hitomi Tashiro, Shigeru Kuroyanagi
分类: cs.CL, cs.AI
发布日期: 2025-10-20
备注: 35 pages, 29 figures, 5 tables
💡 一句话要点
提出自适应提示技术选择方法,自动生成高质量提示,提升LLM性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示工程 大型语言模型 自动提示生成 自适应选择 任务聚类
📋 核心要点
- 现有提示工程依赖专家知识和任务理解,缺乏通用性和自动化。
- 提出一种自适应提示选择方法,通过任务聚类和知识库动态生成提示。
- 实验表明,该方法在BBEH基准测试中优于标准提示和现有自动生成工具。
📝 摘要(中文)
提示工程对于从大型语言模型(LLMs)获得可靠和有效的输出至关重要,但其设计需要提示技术的专业知识和对目标任务的深刻理解。为了解决这个挑战,我们提出了一种新颖的方法,该方法基于用户抽象的任务描述自适应地选择适合任务的提示技术,并自动生成高质量的提示,而无需依赖预先存在的模板或框架。所提出的方法构建了一个知识库,该知识库将任务集群(以跨不同任务的语义相似性为特征)与其相应的提示技术相关联。当用户输入任务描述时,系统将其分配到最相关的任务集群,并通过整合来自知识库的技术来动态生成提示。对来自BIG-Bench Extra Hard(BBEH)的23个任务进行的实验评估表明,与标准提示和现有的自动提示生成工具相比,该方法在算术平均分和调和平均分方面均表现出卓越的性能。这项研究为简化和标准化提示创建奠定了基础,使非专业人士能够有效地利用LLM。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)提示工程中存在的挑战,即提示的设计需要专业知识和对目标任务的深刻理解。现有方法,如手动设计提示或使用预定义模板,难以适应各种任务,且效率低下,泛化能力不足。非专业人士难以有效利用LLMs的能力。
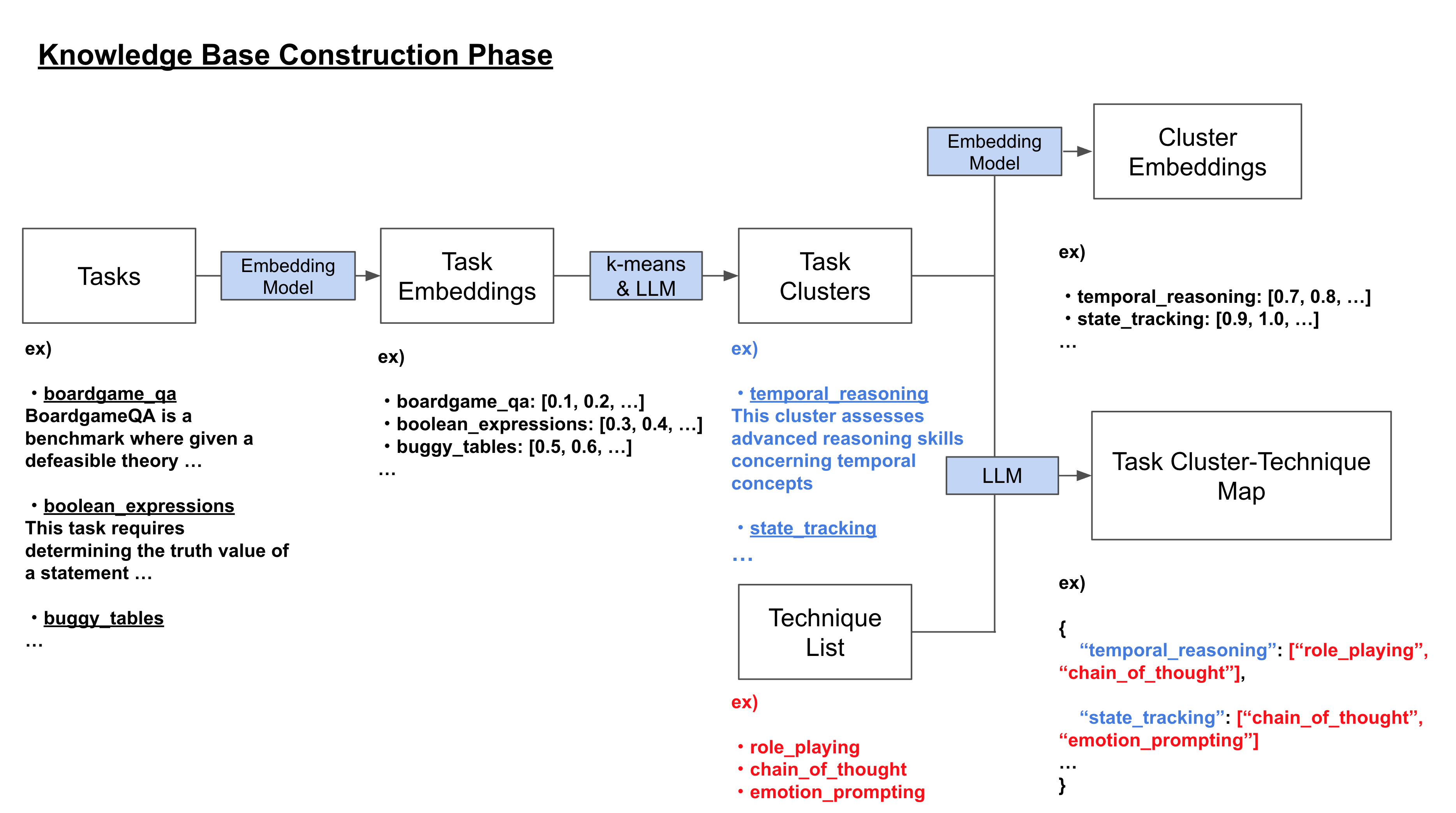
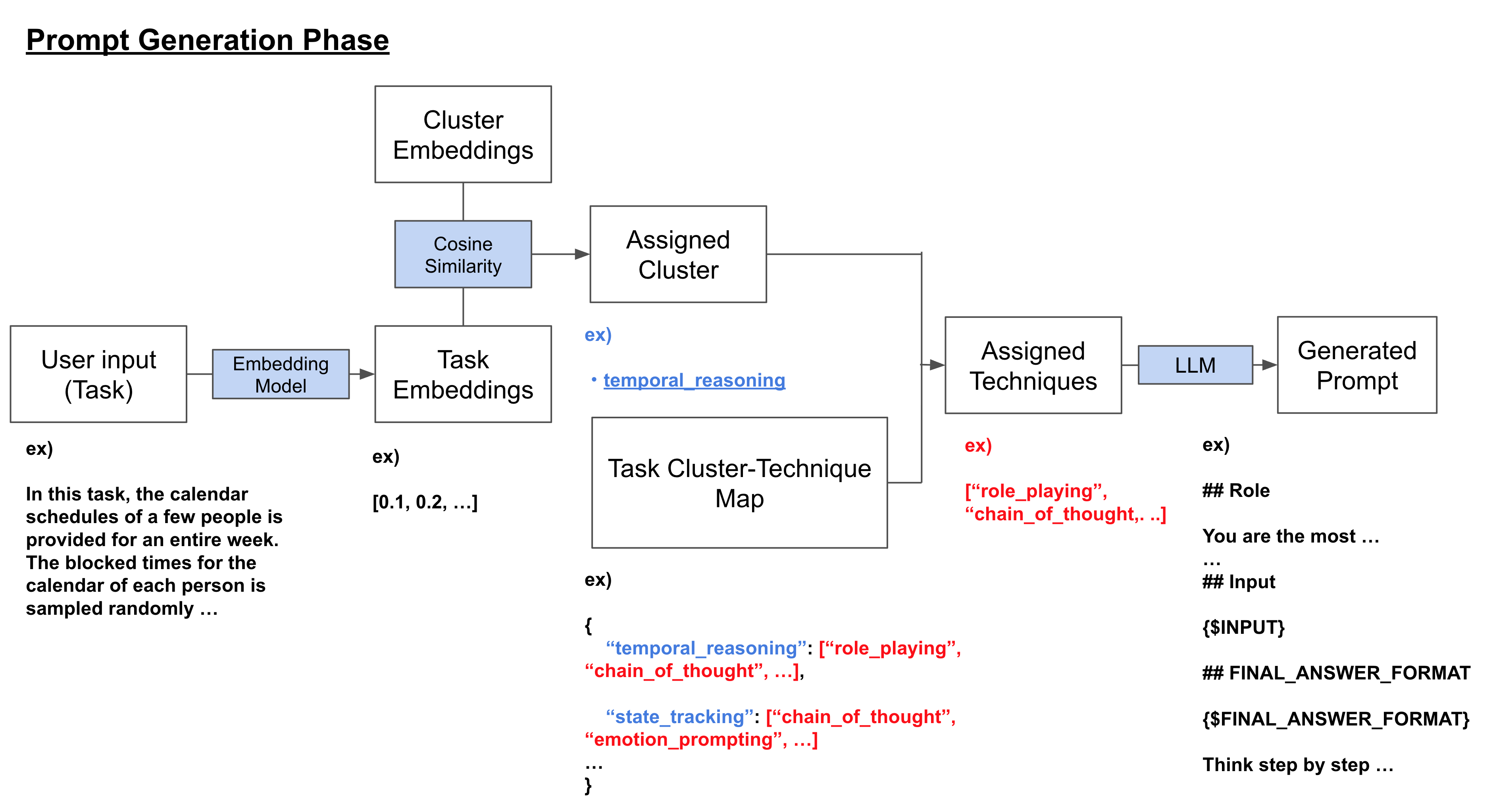
核心思路:论文的核心思路是构建一个知识库,将具有语义相似性的任务聚类与相应的提示技术关联起来。当用户输入任务描述时,系统将其映射到最相关的任务聚类,并从知识库中选择合适的提示技术组合,动态生成高质量的提示。这种方法避免了对预定义模板的依赖,实现了提示的自适应生成。
技术框架:该方法包含以下主要模块:1) 任务描述输入模块:接收用户输入的任务描述。2) 任务聚类模块:基于语义相似性将任务进行聚类。3) 知识库构建模块:将任务集群与相应的提示技术关联,构建知识库。4) 提示生成模块:根据输入的任务描述,将其分配到最相关的任务集群,并从知识库中选择合适的提示技术组合,动态生成提示。5) LLM推理模块:将生成的提示输入LLM,得到输出结果。
关键创新:该方法最重要的创新点在于自适应的提示技术选择机制。与传统的固定提示或基于模板的提示生成方法不同,该方法能够根据任务的语义信息动态选择最合适的提示技术,从而提高LLM的性能。此外,该方法无需人工干预,实现了提示的自动化生成。
关键设计:任务聚类可能使用诸如Sentence-BERT之类的模型来计算任务描述之间的语义相似性,并使用聚类算法(如K-means或层次聚类)将任务分组。知识库的构建可能涉及人工标注或自动挖掘,将任务集群与有效的提示技术关联起来。提示生成模块可能使用加权组合或规则引擎来整合不同的提示技术。具体的参数设置和损失函数(如果使用)在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
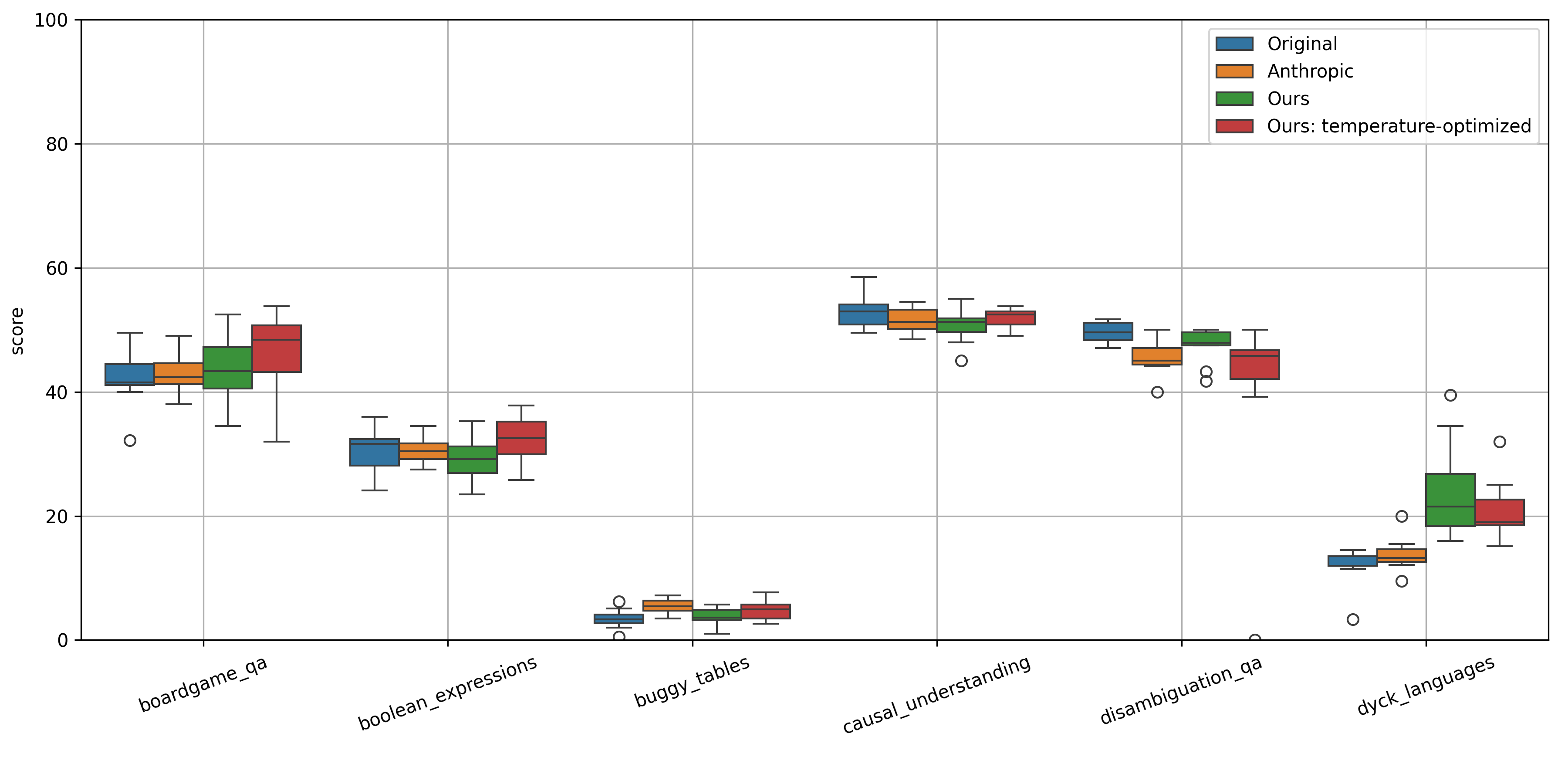
实验结果表明,该方法在BIG-Bench Extra Hard(BBEH)基准测试的23个任务上,与标准提示和现有的自动提示生成工具相比,在算术平均分和调和平均分方面均表现出卓越的性能。具体的性能提升幅度未在摘要中明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要利用大型语言模型的场景,例如智能客服、内容生成、代码生成等。通过自动生成高质量的提示,可以降低LLM的使用门槛,使非专业人士也能充分利用LLM的能力,提高工作效率和质量。未来,该方法可以进一步扩展到更多领域,并与其他技术相结合,实现更智能化的应用。
📄 摘要(原文)
Prompt engineering is crucial for achieving reliable and effective outputs from large language models (LLMs), but its design requires specialized knowledge of prompting techniques and a deep understanding of target tasks. To address this challenge, we propose a novel method that adaptively selects task-appropriate prompting techniques based on users' abstract task descriptions and automatically generates high-quality prompts without relying on pre-existing templates or frameworks. The proposed method constructs a knowledge base that associates task clusters, characterized by semantic similarity across diverse tasks, with their corresponding prompting techniques. When users input task descriptions, the system assigns them to the most relevant task cluster and dynamically generates prompts by integrating techniques drawn from the knowledge base. An experimental evaluation of the proposed method on 23 tasks from BIG-Bench Extra Hard (BBEH) demonstrates superior performance compared with standard prompts and existing automatic prompt-generation tools, as measured by both arithmetic and harmonic mean scores. This research establishes a foundation for streamlining and standardizing prompt creation, enabling non-experts to effectively leverage LLMs.