LLMs Encode How Difficult Problems Are
作者: William Lugoloobi, Chris Russell
分类: cs.CL
发布日期: 2025-10-20
💡 一句话要点
探讨LLMs如何编码问题难度以提升解决能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 问题难度编码 强化学习 线性探测器 人类标注
📋 核心要点
- 现有大型语言模型在处理简单问题时表现不佳,且难度编码与人类判断不一致,影响模型的可靠性。
- 本文通过训练线性探测器,探索LLMs如何编码问题难度,并验证人类标注的难度信号在强化学习中的有效性。
- 实验结果显示,人类标注的难度信号与模型性能正相关,而LLM推导的难度信号则与性能负相关,揭示了两者的本质差异。
📝 摘要(中文)
大型语言模型(LLMs)在解决复杂问题时表现出色,但在简单问题上却常常失败。本文研究了LLMs是否以与人类判断一致的方式内部编码问题难度,并考察这种表示在强化学习后训练中的泛化能力。通过对60个模型进行线性探测,评估数学和编程子集,发现人类标注的难度具有较强的线性可解性,并且随着模型规模的增大而明显增强。相较之下,LLM自身推导的难度表现较弱且扩展性差。研究表明,推动模型朝“更简单”表示的方向发展可以减少幻觉现象并提高准确性。我们发布了探测代码和评估脚本,以便于后续研究的复制。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在简单问题上表现不佳的现象,探讨其内部如何编码问题难度,以及这种编码是否与人类的判断一致。现有方法未能有效利用人类标注的难度信号,导致模型在简单任务上频繁失败。
核心思路:通过训练线性探测器,分析不同层和标记位置的难度编码,评估人类标注的难度与模型自我推导的难度之间的关系,进而优化模型的表现。
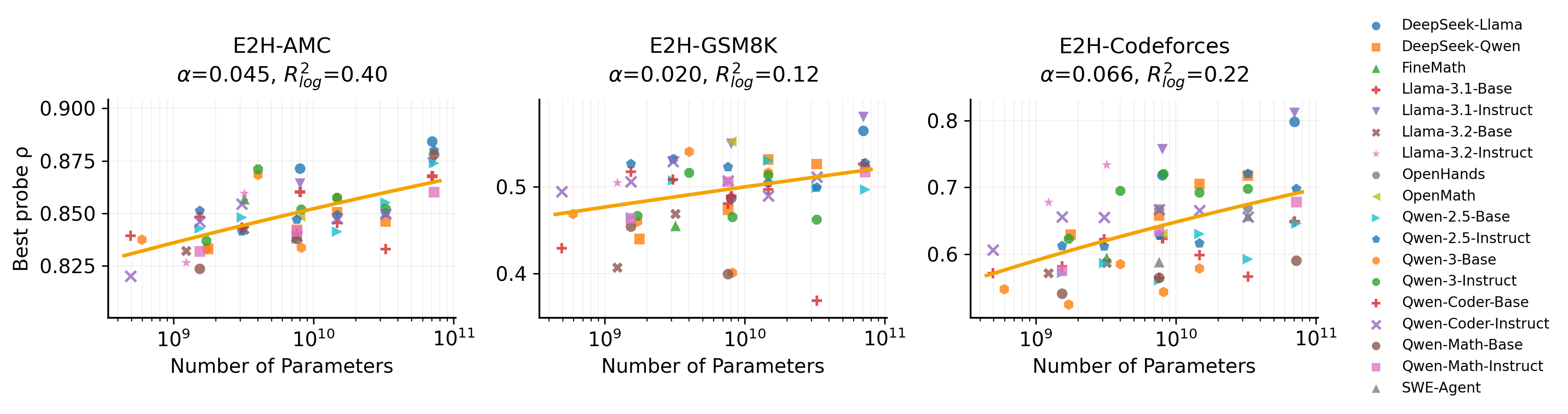
技术框架:研究使用了60个不同的LLM模型,针对数学和编程任务的Easy2HardBench数据集进行评估。通过线性探测器在模型的不同层次上进行训练,分析难度信号的可解性和模型规模的影响。
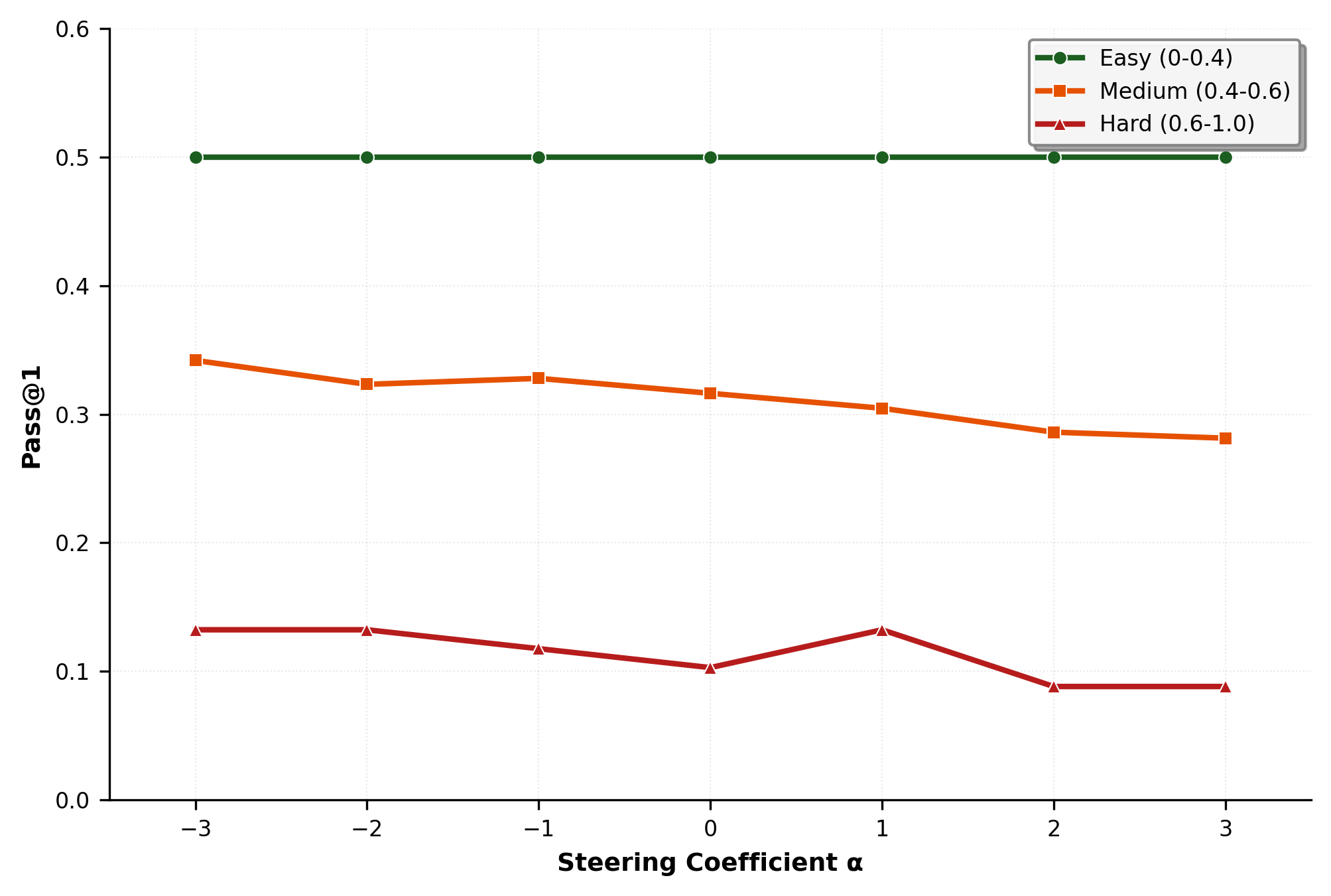
关键创新:本文的主要创新在于揭示了人类标注的难度信号在强化学习中的稳定性,以及与LLM推导的难度信号之间的显著差异。人类标注的难度信号能够有效提升模型的准确性,而LLM推导的信号则在模型性能提升时变得不可靠。
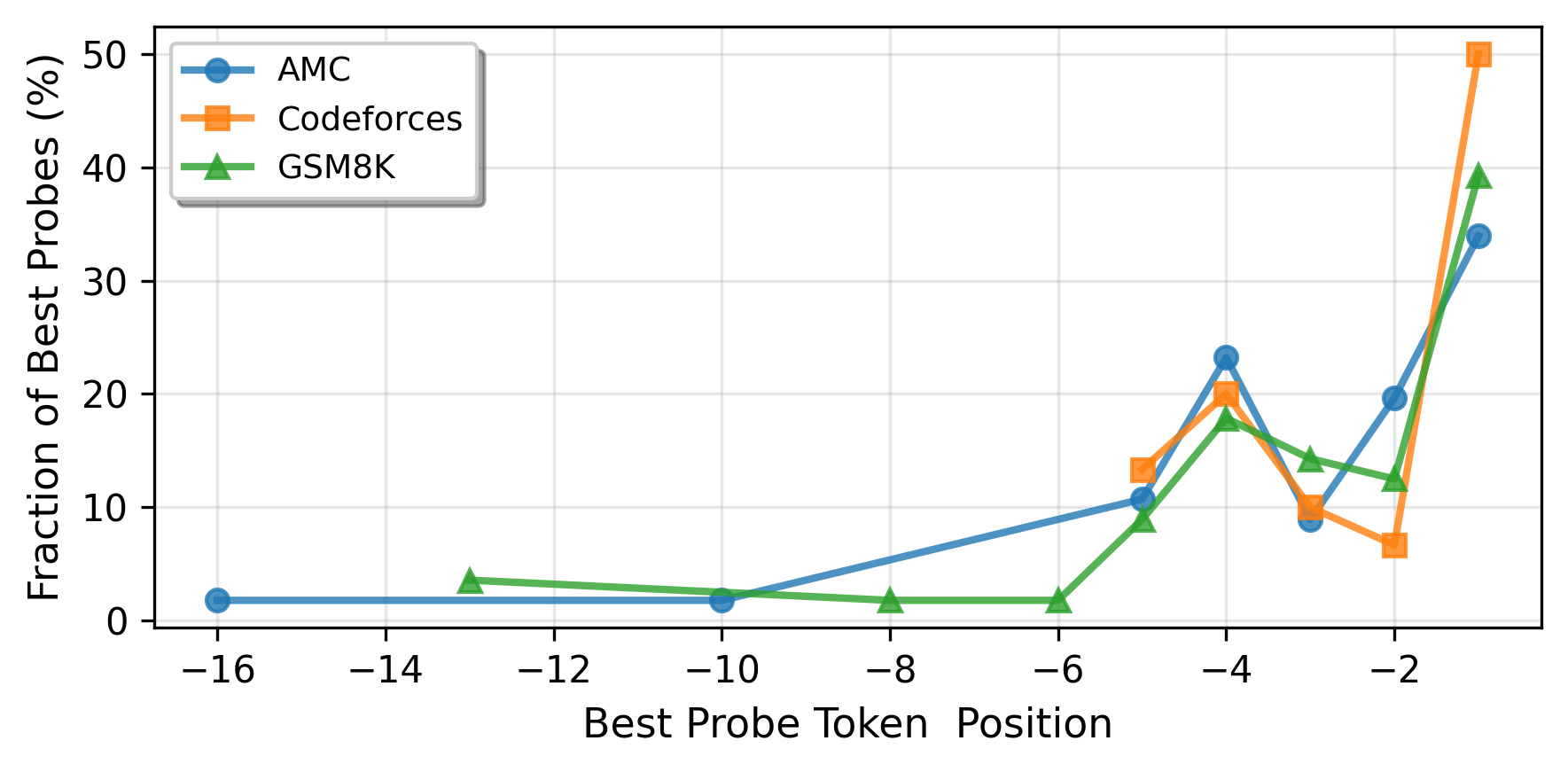
关键设计:研究中使用了线性探测器对模型的不同层进行训练,设置了特定的损失函数以优化难度信号的解码能力,并通过实验验证了不同模型规模对难度信号的影响。
🖼️ 关键图片
📊 实验亮点
实验结果显示,人类标注的难度信号与模型性能之间存在强正相关(AMC: $ρ ext{≈}0.88$),而LLM推导的难度信号则表现较弱,且在模型训练过程中呈现负相关。这表明人类标注的难度信号在强化学习中具有重要的稳定性和有效性。
🎯 应用场景
该研究的潜在应用领域包括教育技术、自动化编程助手和智能问答系统等。通过更准确地理解和编码问题难度,模型可以在多种任务中提供更可靠的解决方案,提升用户体验和系统的整体性能。
📄 摘要(原文)
Large language models exhibit a puzzling inconsistency: they solve complex problems yet frequently fail on seemingly simpler ones. We investigate whether LLMs internally encode problem difficulty in a way that aligns with human judgment, and whether this representation tracks generalization during reinforcement learning post-training. We train linear probes across layers and token positions on 60 models, evaluating on mathematical and coding subsets of Easy2HardBench. We find that human-labeled difficulty is strongly linearly decodable (AMC: $ρ\approx 0.88$) and exhibits clear model-size scaling, whereas LLM-derived difficulty is substantially weaker and scales poorly. Steering along the difficulty direction reveals that pushing models toward "easier" representations reduces hallucination and improves accuracy. During GRPO training on Qwen2.5-Math-1.5B, the human-difficulty probe strengthens and positively correlates with test accuracy across training steps, while the LLM-difficulty probe degrades and negatively correlates with performance. These results suggest that human annotations provide a stable difficulty signal that RL amplifies, while automated difficulty estimates derived from model performance become misaligned precisely as models improve. We release probe code and evaluation scripts to facilitate replication.