Chain-of-Thought Reasoning Improves Context-Aware Translation with Large Language Models
作者: Shabnam Ataee, Andrei Popescu-Belis
分类: cs.CL
发布日期: 2025-10-20
💡 一句话要点
思维链推理提升大语言模型上下文感知翻译能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器翻译 大语言模型 思维链推理 上下文感知 提示工程
📋 核心要点
- 现有机器翻译模型在处理需要上下文信息的句子(如代词照应)时表现不足。
- 论文提出利用思维链(Chain-of-Thought)推理提示,引导LLM更好地理解上下文依赖关系。
- 实验表明,采用思维链推理的LLM在上下文翻译任务上显著提升,特别是GPT-4等模型。
📝 摘要(中文)
本文评估了大语言模型(LLMs)翻译包含句子间依赖关系的文本的能力。我们使用了English-French DiscEvalMT基准测试(Bawden et al., 2018),该基准包含成对的句子,这些句子在代词照应或词汇衔接方面存在翻译挑战。我们评估了来自DeepSeek-R1、GPT、Llama、Mistral和Phi系列的12个LLM在两个任务上的表现:(1)区分正确的翻译和错误的但看似合理的翻译;(2)生成正确的翻译。我们比较了鼓励思维链推理的提示与不鼓励思维链推理的提示。最好的模型利用了推理,在第一个任务上达到了约90%的准确率,在第二个任务上COMET得分约为92%,其中GPT-4、GPT-4o和Phi表现突出。此外,我们观察到一种“智者更智”效应:通过推理获得的改进与没有推理的模型的分数呈正相关。
🔬 方法详解
问题定义:论文旨在解决机器翻译中上下文依赖关系处理不佳的问题,尤其是在代词指代和词汇衔接方面。现有方法难以充分利用句子间的语义关联,导致翻译质量下降。DiscEvalMT基准测试专门用于评估模型在这些方面的能力,揭示了现有模型的痛点。
核心思路:论文的核心思路是利用思维链(Chain-of-Thought, CoT)推理,引导大语言模型逐步分析上下文信息,从而更准确地理解句子间的依赖关系。通过提示模型解释其翻译决策过程,可以提高翻译的准确性和一致性。
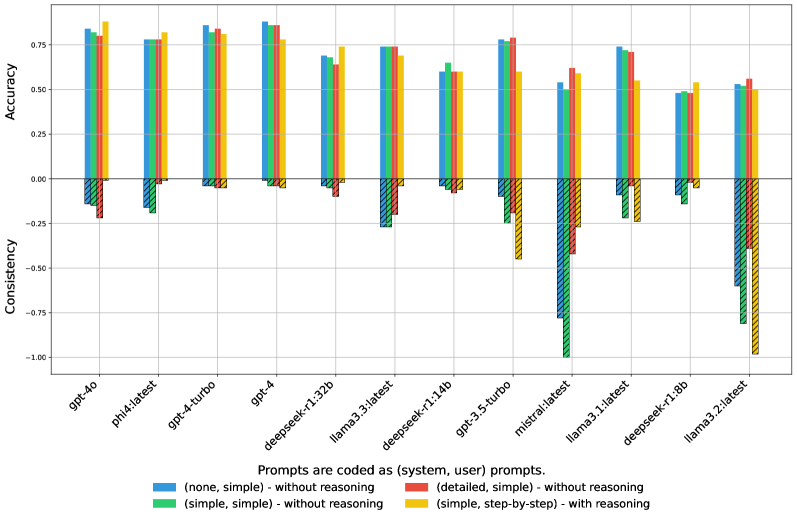
技术框架:论文采用了一种基于提示(Prompting)的框架。首先,构建包含上下文信息的输入文本(来自DiscEvalMT基准)。然后,设计两种类型的提示:一种是标准提示,直接要求模型进行翻译;另一种是CoT提示,引导模型逐步推理并解释其翻译决策。最后,比较两种提示下模型的翻译质量。
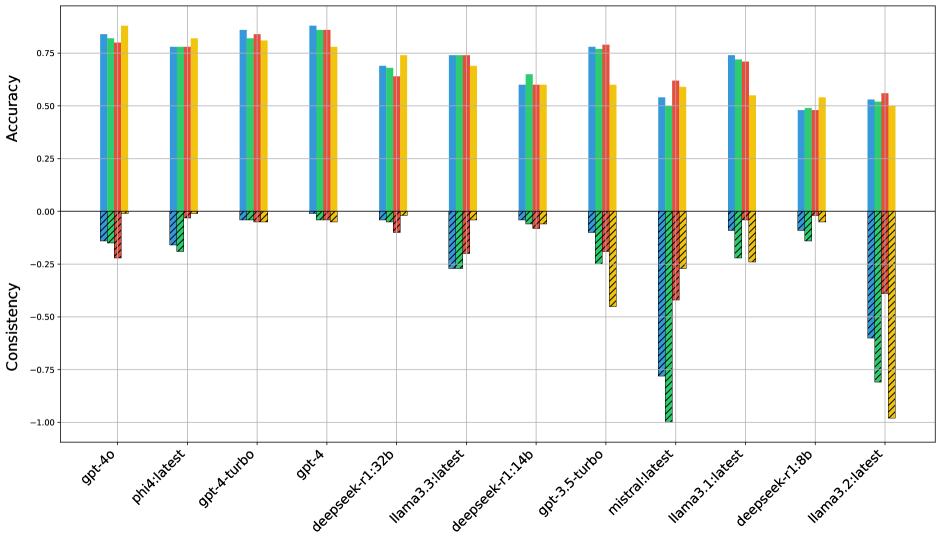
关键创新:关键创新在于将思维链推理引入到上下文感知的机器翻译任务中。与传统的端到端翻译模型相比,CoT提示能够促使模型显式地考虑上下文信息,从而提高翻译的准确性和一致性。此外,论文还观察到“智者更智”效应,即CoT推理对性能较好的模型提升更明显。
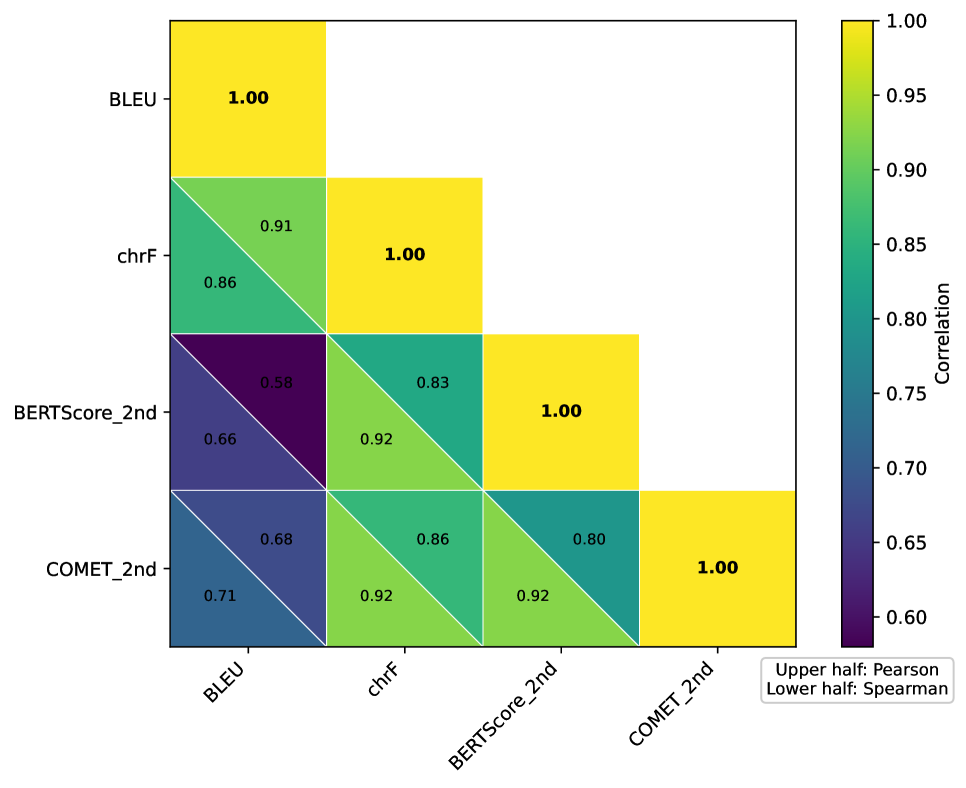
关键设计:论文的关键设计包括:(1) 精心设计的CoT提示,引导模型进行逐步推理;(2) 使用DiscEvalMT基准测试,该基准专门用于评估上下文翻译能力;(3) 采用COMET评分指标,该指标能够更好地评估翻译的语义质量。具体提示工程细节和超参数设置在论文中可能未详细说明,属于实现细节。
🖼️ 关键图片
📊 实验亮点
实验结果表明,采用思维链推理的LLM在DiscEvalMT基准测试中取得了显著提升。在区分正确翻译的任务中,最佳模型达到了约90%的准确率。在生成翻译的任务中,COMET得分约为92%,其中GPT-4、GPT-4o和Phi等模型表现突出。此外,研究还发现CoT推理对性能较好的模型提升更明显,验证了“智者更智”效应。
🎯 应用场景
该研究成果可应用于各种需要高质量机器翻译的场景,例如跨语言交流、文档翻译、多语言信息检索等。通过提升机器翻译的上下文感知能力,可以减少翻译错误和歧义,提高沟通效率和准确性。未来,该方法有望应用于更复杂的跨语言理解和生成任务。
📄 摘要(原文)
This paper assesses the capacity of large language models (LLMs) to translate texts that include inter-sentential dependencies. We use the English-French DiscEvalMT benchmark (Bawden et al., 2018) with pairs of sentences containing translation challenges either for pronominal anaphora or for lexical cohesion. We evaluate 12 LLMs from the DeepSeek-R1, GPT, Llama, Mistral and Phi families on two tasks: (1) distinguishing a correct translation from a wrong but plausible one; (2) generating a correct translation. We compare prompts that encourage chain-of-thought reasoning with those that do not. The best models take advantage of reasoning and reach about 90% accuracy on the first task, and COMET scores of about 92% on the second task, with GPT-4, GPT-4o and Phi standing out. Moreover, we observe a "wise get wiser" effect: the improvements through reasoning are positively correlated with the scores of the models without reasoning.