From Local to Global: Revisiting Structured Pruning Paradigms for Large Language Models
作者: Ziyan Wang, Enmao Diao, Qi Le, Pu Wang, Minwoo Lee, Shu-ping Yeh, Evgeny Stupachenko, Hao Feng, Li Yang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-20
备注: 16 pages, 4 figures
💡 一句话要点
提出全局迭代结构化剪枝GISP,提升大语言模型下游任务性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 结构化剪枝 全局剪枝 任务感知 模型压缩
📋 核心要点
- 现有局部结构化剪枝方法忽略任务目标,导致下游任务性能提升有限。
- GISP通过全局迭代剪枝,利用任务损失指导重要性评估,提升剪枝效果。
- 实验表明,GISP在多种LLM上显著降低困惑度,提高下游任务准确率。
📝 摘要(中文)
结构化剪枝是高效部署大型语言模型(LLMs)的实用方法,因为它能产生紧凑且硬件友好的架构。然而,目前主流的局部剪枝范式是任务无关的:它优化的是逐层重建而非任务目标,倾向于保持困惑度或通用的零样本行为,但未能充分利用适度的任务特定校准信号,导致下游任务增益有限。本文重新审视全局结构化剪枝,并提出GISP(全局迭代结构化剪枝),这是一种后训练方法,它使用基于一阶损失的重要权重(在结构级别上聚合,并进行块状归一化)来移除注意力头和MLP通道。迭代式调度而非一次性剪枝,稳定了高稀疏度下的准确性,并缓解了困惑度崩溃,而无需中间微调;剪枝轨迹也形成了嵌套子网络,支持“一次剪枝,多次部署”的工作流程。此外,由于重要性由模型级别的损失定义,GISP自然支持任务特定的目标;本文实例化了用于语言建模的困惑度和用于决策风格任务的基于边距的目标。大量实验表明,在Llama2-7B/13B、Llama3-8B和Mistral-0.3-7B上,GISP始终降低WikiText-2困惑度并提高下游准确性,尤其是在40-50%稀疏度下增益显著;在DeepSeek-R1-Distill-Llama-3-8B与GSM8K上,任务对齐的校准显著提高了精确匹配准确率。
🔬 方法详解
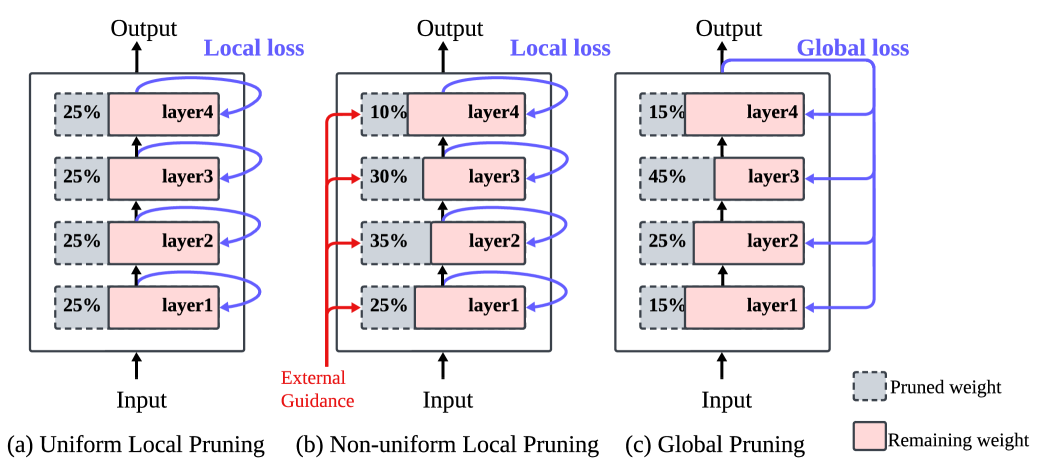
问题定义:现有的大语言模型结构化剪枝方法,特别是局部剪枝方法,通常是任务无关的。它们主要关注于保持模型的困惑度或通用的零样本能力,而忽略了特定任务的需求。这种做法导致剪枝后的模型在下游任务上的性能提升有限,无法充分利用任务相关的校准信号。因此,如何设计一种任务感知的结构化剪枝方法,以提升大语言模型在特定任务上的性能,是一个亟待解决的问题。
核心思路:GISP的核心思路是采用全局的视角进行结构化剪枝,并利用任务相关的损失函数来指导剪枝过程。与局部剪枝不同,GISP在模型层面聚合重要性权重,从而能够更好地识别对特定任务至关重要的结构(如注意力头和MLP通道)。此外,GISP采用迭代式的剪枝策略,逐步移除不重要的结构,并在每次迭代中评估模型的性能,从而避免了一次性剪枝可能导致的性能崩溃。
技术框架:GISP的整体框架包括以下几个主要步骤:1) 重要性评估:基于任务相关的损失函数,计算模型中每个结构(注意力头和MLP通道)的重要性权重。这些权重在模型层面进行聚合,并进行块状归一化。2) 结构剪枝:根据计算得到的重要性权重,移除模型中重要性较低的结构。剪枝的比例由预设的稀疏度目标决定。3) 性能评估:在剪枝后,评估模型在特定任务上的性能,如困惑度或准确率。4) 迭代优化:重复上述步骤,逐步提高模型的稀疏度,直到达到预设的目标。
关键创新:GISP的关键创新在于其全局视角和任务感知的剪枝策略。与传统的局部剪枝方法相比,GISP能够更好地识别对特定任务至关重要的结构,并保留这些结构,从而提升剪枝后模型在下游任务上的性能。此外,GISP的迭代式剪枝策略能够稳定模型的性能,避免性能崩溃,并支持“一次剪枝,多次部署”的工作流程。
关键设计:GISP的关键设计包括:1) 基于损失的重要性权重:使用任务相关的损失函数(如困惑度或基于边距的损失)来计算结构的重要性权重。2) 块状归一化:对重要性权重进行块状归一化,以平衡不同结构之间的重要性差异。3) 迭代式剪枝调度:采用迭代式的剪枝策略,逐步提高模型的稀疏度,并在每次迭代中评估模型的性能。4) 任务特定目标:支持任务特定的目标函数,如语言建模的困惑度和决策风格任务的基于边距的目标。
🖼️ 关键图片

📊 实验亮点
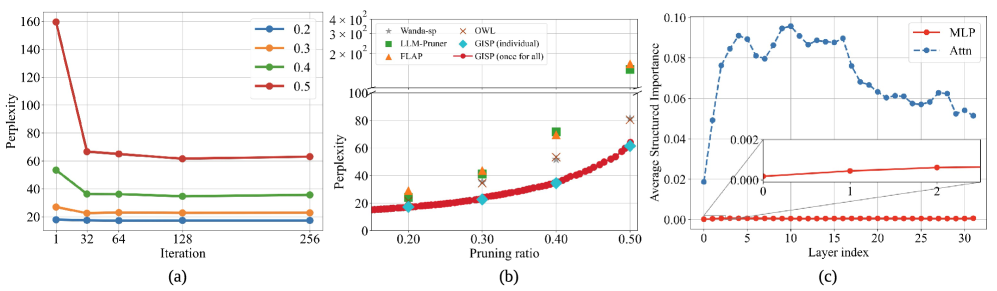
实验结果表明,GISP在Llama2-7B/13B、Llama3-8B和Mistral-0.3-7B等模型上,显著降低了WikiText-2的困惑度,并提高了下游任务的准确率,尤其是在40-50%的稀疏度下。在DeepSeek-R1-Distill-Llama-3-8B模型上,通过任务对齐的校准,GSM8K的精确匹配准确率得到了显著提升。
🎯 应用场景
GISP可应用于大语言模型的轻量化部署,尤其适用于资源受限的边缘设备。通过任务感知的剪枝,可以在保证模型性能的同时,显著降低模型大小和计算复杂度,从而加速推理速度并降低功耗。该方法在智能助手、自然语言处理等领域具有广泛的应用前景。
📄 摘要(原文)
Structured pruning is a practical approach to deploying large language models (LLMs) efficiently, as it yields compact, hardware-friendly architectures. However, the dominant local paradigm is task-agnostic: by optimizing layer-wise reconstruction rather than task objectives, it tends to preserve perplexity or generic zero-shot behavior but fails to capitalize on modest task-specific calibration signals, often yielding limited downstream gains. We revisit global structured pruning and present GISP-Global Iterative Structured Pruning-a post-training method that removes attention heads and MLP channels using first-order, loss-based important weights aggregated at the structure level with block-wise normalization. An iterative schedule, rather than one-shot pruning, stabilizes accuracy at higher sparsity and mitigates perplexity collapse without requiring intermediate fine-tuning; the pruning trajectory also forms nested subnetworks that support a "prune-once, deploy-many" workflow. Furthermore, because importance is defined by a model-level loss, GISP naturally supports task-specific objectives; we instantiate perplexity for language modeling and a margin-based objective for decision-style tasks. Extensive experiments show that across Llama2-7B/13B, Llama3-8B, and Mistral-0.3-7B, GISP consistently lowers WikiText-2 perplexity and improves downstream accuracy, with especially strong gains at 40-50% sparsity; on DeepSeek-R1-Distill-Llama-3-8B with GSM8K, task-aligned calibration substantially boosts exact-match accuracy.