AtlasKV: Augmenting LLMs with Billion-Scale Knowledge Graphs in 20GB VRAM
作者: Haoyu Huang, Hong Ting Tsang, Jiaxin Bai, Xi Peng, Gong Zhang, Yangqiu Song
分类: cs.CL, cs.AI
发布日期: 2025-10-20
💡 一句话要点
AtlasKV:利用20GB VRAM,通过十亿级知识图谱增强大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 大型语言模型 检索增强生成 参数化知识集成 低资源计算
📋 核心要点
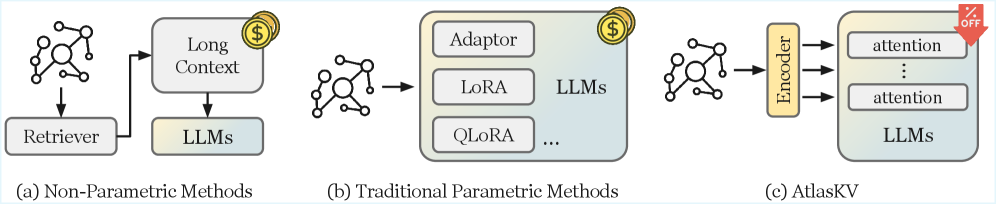
- RAG方法在知识增强方面依赖外部检索,导致大规模知识集成时推理延迟高,成本大。
- AtlasKV提出一种参数知识集成方法,通过KG2KV和HiKVP将知识图谱高效融入LLM,无需外部检索。
- AtlasKV在极低GPU内存消耗下,保持了LLM的知识基础和泛化能力,且易于适应新知识。
📝 摘要(中文)
检索增强生成(RAG)在利用外部知识增强大型语言模型(LLM)方面取得了一些成功。然而,作为LLM的一种非参数知识集成范式,RAG方法严重依赖于外部检索模块和检索到的文本上下文先验。特别是对于非常大规模的知识增强,由于昂贵的搜索和更长的相关上下文,它们会引入大量的推理延迟。本文提出了一种参数知识集成方法,称为AtlasKV,这是一种可扩展、有效且通用的方法,可以使用极少的GPU内存成本(例如,小于20GB VRAM)利用十亿级知识图谱(KG)(例如,10亿三元组)来增强LLM。在AtlasKV中,我们引入了KG2KV和HiKVP,以亚线性的时间和内存复杂度将KG三元组大规模地集成到LLM中。它利用LLM固有的注意力机制保持了强大的知识基础和泛化性能,并且在适应新知识时不需要外部检索器、长上下文先验或重新训练。
🔬 方法详解
问题定义:现有RAG方法在利用大规模知识图谱增强LLM时,面临着推理延迟高、计算成本大的问题。RAG依赖外部检索器和长文本上下文,导致搜索开销巨大,且难以有效利用知识图谱的结构化信息。
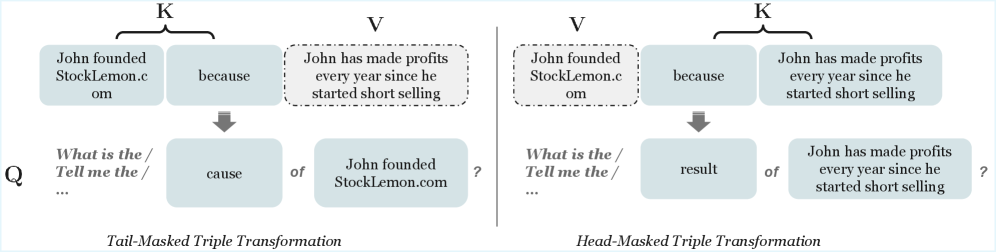
核心思路:AtlasKV的核心思路是将知识图谱的信息参数化地融入到LLM中,避免了对外部检索器的依赖。通过将知识图谱的三元组转换为键值对(KV),并利用LLM的注意力机制来学习这些KV表示,从而实现知识的集成。
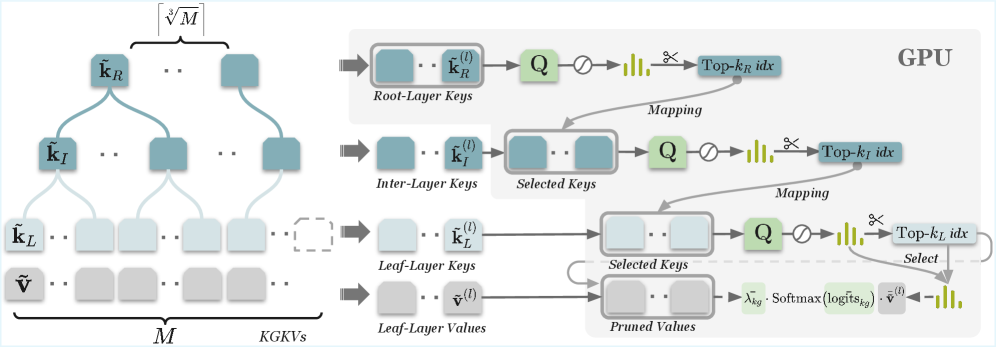
技术框架:AtlasKV主要包含两个关键模块:KG2KV和HiKVP。KG2KV负责将知识图谱的三元组转换为键值对表示。HiKVP则负责将这些键值对高效地集成到LLM中。整个过程无需外部检索器,也无需对LLM进行重新训练。
关键创新:AtlasKV的关键创新在于其参数化的知识集成方法。与RAG方法不同,AtlasKV不需要依赖外部检索器和长文本上下文,而是直接将知识图谱的信息融入到LLM的参数中。这种方法可以显著降低推理延迟,并提高知识利用的效率。
关键设计:KG2KV模块将知识图谱的三元组(头实体,关系,尾实体)转换为键值对,其中头实体和关系作为键,尾实体作为值。HiKVP模块则采用了一种分层的键值对存储结构,以降低内存消耗。具体的技术细节包括键值对的编码方式、注意力机制的实现方式以及分层存储结构的具体参数设置等。论文中可能还涉及损失函数的设计,用于指导LLM学习知识图谱的信息。
🖼️ 关键图片
📊 实验亮点
AtlasKV能够在20GB VRAM的条件下,利用十亿级别的知识图谱增强LLM,而无需外部检索器和重新训练。实验结果表明,AtlasKV在知识问答等任务上取得了显著的性能提升,并且在适应新知识时具有很强的灵活性。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
AtlasKV可应用于各种需要利用大规模知识图谱的场景,例如问答系统、知识图谱补全、推荐系统等。它能够帮助LLM更好地理解和利用知识,从而提高其在这些任务中的性能。该研究的实际价值在于降低了LLM知识增强的成本,使其能够更容易地应用于资源受限的环境中。未来,AtlasKV有望成为LLM知识增强的一种重要范式。
📄 摘要(原文)
Retrieval-augmented generation (RAG) has shown some success in augmenting large language models (LLMs) with external knowledge. However, as a non-parametric knowledge integration paradigm for LLMs, RAG methods heavily rely on external retrieval modules and the retrieved textual context prior. Especially for very large scale knowledge augmentation, they would introduce substantial inference latency due to expensive searches and much longer relevant context. In this paper, we propose a parametric knowledge integration method, called \textbf{AtlasKV}, a scalable, effective, and general way to augment LLMs with billion-scale knowledge graphs (KGs) (e.g. 1B triples) using very little GPU memory cost (e.g. less than 20GB VRAM). In AtlasKV, we introduce KG2KV and HiKVP to integrate KG triples into LLMs at scale with sub-linear time and memory complexity. It maintains strong knowledge grounding and generalization performance using the LLMs' inherent attention mechanism, and requires no external retrievers, long context priors, or retraining when adapting to new knowledge.