Select-Then-Decompose: From Empirical Analysis to Adaptive Selection Strategy for Task Decomposition in Large Language Models
作者: Shuodi Liu, Yingzhuo Liu, Zi Wang, Yusheng Wang, Huijia Wu, Liuyu Xiang, Zhaofeng He
分类: cs.CL, cs.AI
发布日期: 2025-10-20
备注: Accepted to the Main Conference of EMNLP 2025 (Oral)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Select-Then-Decompose策略,自适应选择任务分解方法,优化大语言模型性能与成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 任务分解 自适应策略 性能优化 成本控制
📋 核心要点
- 现有任务分解方法侧重记忆、工具和反馈,忽略了性能与成本的平衡。
- 提出Select-Then-Decompose策略,根据任务特征自适应选择分解方法。
- 实验表明,该策略在多个基准测试中实现了性能与成本的最佳平衡。
📝 摘要(中文)
大型语言模型(LLMs)展现了卓越的推理和规划能力,推动了任务分解的广泛研究。现有的任务分解方法主要关注记忆、工具使用和反馈机制,在特定领域取得了显著成功,但常常忽略了性能和成本之间的权衡。本研究首先对任务分解进行了全面的调查,确定了六种分类方案。然后,我们对影响任务分解性能和成本的三个因素进行了实证分析:方法的类别、任务的特征以及分解和执行模型的配置,揭示了三个关键见解,并总结了一套实用的原则。在此分析的基础上,我们提出了Select-Then-Decompose策略,该策略建立了一个由选择、执行和验证三个阶段组成的闭环问题解决过程。该策略基于任务特征动态选择最合适的分解方法,并通过验证模块提高结果的可靠性。在多个基准上的综合评估表明,Select-Then-Decompose始终位于帕累托前沿,证明了性能和成本之间的最佳平衡。我们的代码已在https://github.com/summervvind/Select-Then-Decompose公开。
🔬 方法详解
问题定义:现有的大语言模型任务分解方法通常只关注如何提升性能,例如通过引入外部工具、增加记忆容量或利用反馈机制,而忽略了计算成本。在实际应用中,不同的任务适合不同的分解策略,固定策略无法兼顾所有场景,导致资源浪费或性能瓶颈。因此,需要一种能够根据任务特性自适应选择分解策略的方法,以在性能和成本之间取得平衡。
核心思路:Select-Then-Decompose的核心思路是首先根据任务的特征选择合适的分解方法,然后再执行分解和求解。这种“先选择,后分解”的策略允许模型根据任务的难易程度和资源限制,动态地调整分解策略,从而在保证性能的同时,降低计算成本。通过引入验证模块,进一步提升结果的可靠性。
技术框架:Select-Then-Decompose包含三个主要阶段:选择(Selection)、执行(Execution)和验证(Verification)。
-
选择阶段:分析任务特征,选择最合适的分解方法。这一阶段可能涉及对任务进行分类、评估其复杂度,并根据预定义的规则或学习到的模型,选择相应的分解策略。
-
执行阶段:利用选择的分解方法,将原始任务分解为多个子任务,并依次执行这些子任务。这一阶段可能涉及调用外部工具、利用大语言模型的推理能力等。
-
验证阶段:对执行结果进行验证,以确保其正确性和可靠性。如果验证失败,则可能需要重新选择分解方法或调整执行过程。
关键创新:该方法最重要的创新点在于其自适应性。不同于以往固定使用某种分解策略的方法,Select-Then-Decompose能够根据任务的特性动态选择最合适的策略。这种自适应性使得模型能够在不同的任务场景下,都能够取得较好的性能和成本平衡。此外,验证模块的引入也提高了结果的可靠性。
关键设计:选择阶段的关键在于如何准确地评估任务的特征,并将其映射到合适的分解策略。这可能需要设计合适的特征提取器,以及训练一个能够根据特征进行策略选择的模型。验证阶段的关键在于如何设计有效的验证方法,以检测执行结果的错误。这可能需要利用领域知识、引入外部工具或设计专门的验证模型。
🖼️ 关键图片

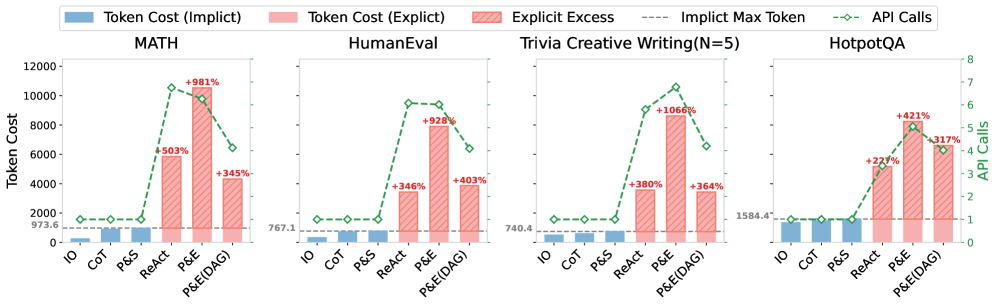

📊 实验亮点
实验结果表明,Select-Then-Decompose策略在多个基准测试中均表现出色,始终位于帕累托前沿,实现了性能和成本之间的最佳平衡。具体而言,该策略在保证性能不下降的前提下,显著降低了计算成本,或者在相同成本下,提升了任务完成的准确率。与固定分解策略相比,Select-Then-Decompose能够更好地适应不同的任务场景,展现出更强的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要利用大语言模型进行复杂任务求解的场景,例如智能客服、自动化报告生成、代码生成、科学研究等。通过自适应地选择任务分解策略,可以显著降低计算成本,提高任务完成效率,并提升结果的可靠性。未来,该方法有望推广到更多领域,并与其他技术相结合,实现更强大的智能应用。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable reasoning and planning capabilities, driving extensive research into task decomposition. Existing task decomposition methods focus primarily on memory, tool usage, and feedback mechanisms, achieving notable success in specific domains, but they often overlook the trade-off between performance and cost. In this study, we first conduct a comprehensive investigation on task decomposition, identifying six categorization schemes. Then, we perform an empirical analysis of three factors that influence the performance and cost of task decomposition: categories of approaches, characteristics of tasks, and configuration of decomposition and execution models, uncovering three critical insights and summarizing a set of practical principles. Building on this analysis, we propose the Select-Then-Decompose strategy, which establishes a closed-loop problem-solving process composed of three stages: selection, execution, and verification. This strategy dynamically selects the most suitable decomposition approach based on task characteristics and enhances the reliability of the results through a verification module. Comprehensive evaluations across multiple benchmarks show that the Select-Then-Decompose consistently lies on the Pareto frontier, demonstrating an optimal balance between performance and cost. Our code is publicly available at https://github.com/summervvind/Select-Then-Decompose.