CLAWS:Creativity detection for LLM-generated solutions using Attention Window of Sections
作者: Keuntae Kim, Eunhye Jeong, Sehyeon Lee, Seohee Yoon, Yong Suk Choi
分类: cs.CL, cs.AI
发布日期: 2025-10-20
备注: NeurIPS 2025
💡 一句话要点
CLAWS:利用注意力窗口检测LLM生成数学解题方案的创造力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 创造力评估 注意力机制 数学解题 强化学习
📋 核心要点
- 现有方法在评估LLM推理任务中的创造力方面存在不足,主要挑战在于创造力范围难以界定且依赖人工评估。
- CLAWS方法通过分析提示部分和输出之间的注意力权重,自动将数学解题方案分类为典型、创造性和幻觉。
- 实验结果表明,CLAWS在多个数学RL模型上优于现有的白盒检测方法,并在大量数学问题上进行了验证。
📝 摘要(中文)
大型语言模型(LLM)在推理能力方面的最新进展非常显著。通过强化学习(RL)训练的LLM在数学和编码等具有挑战性的任务中表现出强大的性能,即使模型尺寸相对较小。然而,尽管任务准确性有所提高,但与写作任务相比,LLM生成内容的创造力评估在推理任务中在很大程度上被忽视。推理中创造力评估研究的缺乏主要源于两个挑战:(1)难以定义创造力的范围,以及(2)评估过程中需要人工评估。为了应对这些挑战,我们提出了一种名为CLAWS的方法,该方法通过利用提示部分和输出之间的注意力权重,将数学解决方案定义并分类为典型、创造性和幻觉,而无需人工评估。CLAWS在五个7-8B数学RL模型(DeepSeek、Qwen、Mathstral、OpenMath2和Oreal)上优于五种现有的白盒检测方法(Perplexity、Logit Entropy、Window Entropy、Hidden Score和Attention Score)。我们在从181个数学竞赛(AJHSME、AMC、AIME)收集的4545个数学问题上验证了CLAWS。
🔬 方法详解
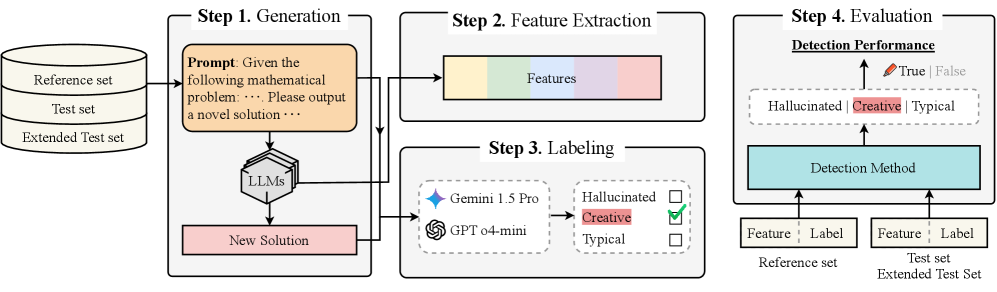
问题定义:论文旨在解决LLM生成的数学解题方案的创造力评估问题。现有方法主要依赖人工评估,成本高昂且主观性强。此外,缺乏对创造力范围的明确定义,使得自动化评估变得困难。现有白盒检测方法(如困惑度、熵等)无法有效区分创造性解法和错误解法(幻觉)。
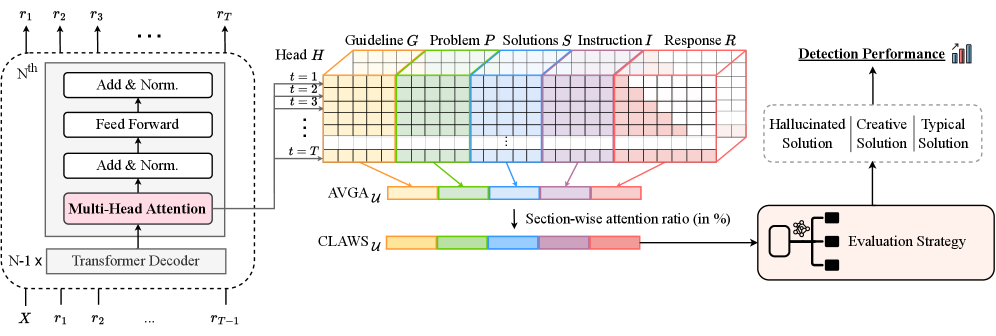
核心思路:论文的核心思路是利用LLM在生成解题方案时,不同部分之间的注意力权重来推断解题方案的创造力。创造性解法往往会关注到提示中不寻常的部分,并将其与输出进行关联。通过分析注意力分布,可以区分典型解法、创造性解法和幻觉。
技术框架:CLAWS方法主要包含以下几个步骤:1) 输入数学问题和LLM生成的解题方案;2) 计算提示各部分和输出之间的注意力权重;3) 基于注意力权重,将解题方案分类为典型、创造性和幻觉。该方法无需人工标注数据,属于无监督方法。
关键创新:CLAWS的关键创新在于利用注意力权重来定义和检测LLM生成内容的创造力。与现有方法相比,CLAWS不需要人工评估,可以自动区分不同类型的解题方案。此外,CLAWS方法具有通用性,可以应用于不同的LLM模型和数学问题。
关键设计:CLAWS方法的关键设计在于如何量化注意力权重并将其用于分类。具体而言,论文可能使用了以下技术细节:1) 定义注意力窗口,关注提示中与输出相关的特定部分;2) 计算注意力权重的统计特征,例如均值、方差等;3) 使用阈值或聚类算法将解题方案分类为典型、创造性和幻觉。具体的参数设置和阈值选择可能需要根据实验数据进行调整。
🖼️ 关键图片

📊 实验亮点
CLAWS在五个7-8B数学RL模型(DeepSeek、Qwen、Mathstral、OpenMath2和Oreal)上进行了评估,并在4545个数学问题上进行了验证。实验结果表明,CLAWS优于五种现有的白盒检测方法(Perplexity、Logit Entropy、Window Entropy、Hidden Score和Attention Score),能够更准确地识别LLM生成的创造性解题方案。
🎯 应用场景
CLAWS方法可应用于自动评估LLM在数学、编程等领域的解题能力,并识别具有创造性的解决方案。该技术有助于提高LLM的教学和学习效率,并促进LLM在创新领域的应用。此外,该方法还可以用于检测LLM生成的错误信息(幻觉),提高LLM的可靠性。
📄 摘要(原文)
Recent advances in enhancing the reasoning ability of large language models (LLMs) have been remarkably successful. LLMs trained with reinforcement learning (RL) for reasoning demonstrate strong performance in challenging tasks such as mathematics and coding, even with relatively small model sizes. However, despite these improvements in task accuracy, the assessment of creativity in LLM generations has been largely overlooked in reasoning tasks, in contrast to writing tasks. The lack of research on creativity assessment in reasoning primarily stems from two challenges: (1) the difficulty of defining the range of creativity, and (2) the necessity of human evaluation in the assessment process. To address these challenges, we propose CLAWS, a method that defines and classifies mathematical solutions into typical, creative, and hallucinated categories without human evaluation, by leveraging attention weights across prompt sections and output. CLAWS outperforms five existing white-box detection methods (Perplexity, Logit Entropy, Window Entropy, Hidden Score, and Attention Score) on five 7-8B math RL models (DeepSeek, Qwen, Mathstral, OpenMath2, and Oreal). We validate CLAWS on 4545 math problems collected from 181 math contests (AJHSME, AMC, AIME).