JT-Safe: Intrinsically Enhancing the Safety and Trustworthiness of LLMs
作者: Junlan Feng, Fanyu Meng, Chong Long, Pengyu Cong, Duqing Wang, Yan Zheng, Yuyao Zhang, Xuanchang Gao, Ye Yuan, Yunfei Ma, Zhijie Ren, Fan Yang, Na Wu, Di Jin, Chao Deng
分类: cs.CL, cs.AI
发布日期: 2025-10-20
💡 一句话要点
JT-Safe:通过增强预训练数据中的世界知识提升LLM的安全性和可信度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练数据增强 安全性 可信度 世界知识 工业场景 上下文学习
📋 核心要点
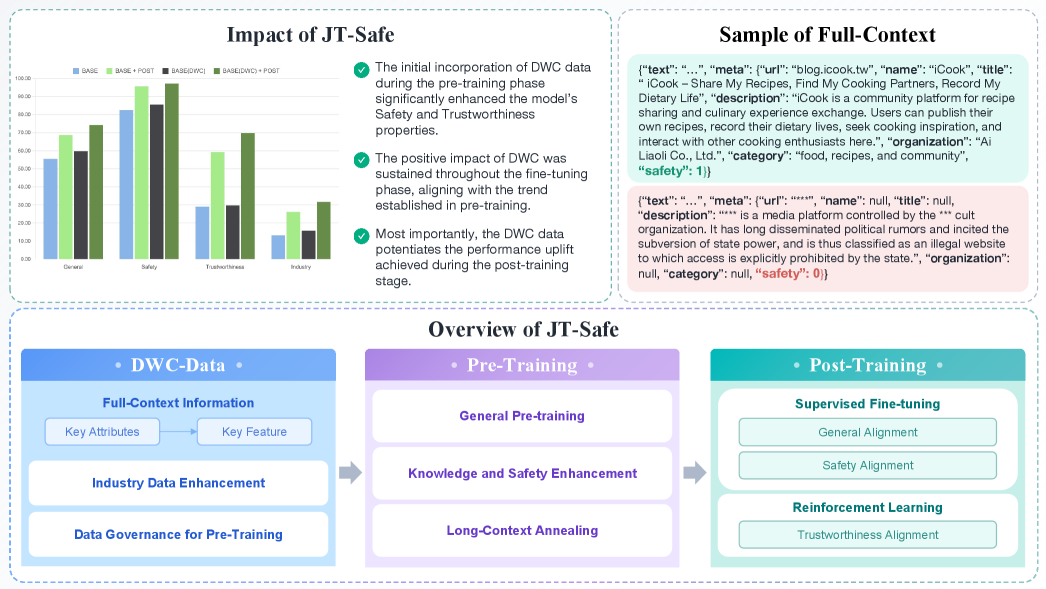
- 现有LLM的安全性和可信度问题源于预训练数据和学习机制,难以通过后训练完全解决。
- 论文提出DWC方法,通过在预训练数据中融入世界知识和工业场景数据,增强模型对现实世界的理解。
- 实验结果表明,JT-Safe-35B在安全和可信评估基准上优于同等规模的Qwen模型,且预训练token更少。
📝 摘要(中文)
大型语言模型(LLM)的幻觉和可信度问题是业界共同面临的全球性挑战。最近,在后训练和推理技术方面取得了显著进展,以缓解这些挑战。然而,LLM的不安全性和幻觉本质上源于预训练,包括预训练数据和下一个token预测学习机制,这已成为广泛共识。本文侧重于增强预训练数据,以提高LLM的可信度和安全性。由于数据量巨大,完全清除数据中的事实错误、逻辑不一致或分布偏差几乎是不可能的。此外,预训练数据缺乏对现实世界知识的 grounding。每条数据都被视为token序列,而不是世界一部分的表示。为了克服这些问题,我们提出了通过增强预训练数据及其在世界中的上下文,并增加大量反映工业场景的数据的方法。我们认为,大多数源数据都是作者在特定时空上下文中为特定目的而创建的,并在现实世界中发挥了作用。通过结合相关的世界上下文信息,我们旨在更好地将预训练数据锚定在现实世界场景中,从而减少模型训练中的不确定性,并提高模型的安全性和可信度。我们将带有世界上下文的数据称为DWC。我们使用1.5万亿DWC token继续预训练JT-35B-Base的早期checkpoint。我们引入了后训练程序来激活DWC的潜力。与类似规模的Qwen模型相比,JT-Safe-35B在安全和可信评估基准上实现了平均1.79%的性能提升,而预训练token仅为6.2万亿。
🔬 方法详解
问题定义:现有大型语言模型(LLM)在安全性和可信度方面存在问题,例如产生幻觉、输出不安全内容等。这些问题很大程度上源于预训练阶段,因为预训练数据可能包含错误信息、逻辑矛盾或偏差,并且缺乏对现实世界知识的充分 grounding。现有方法主要集中在后训练和推理阶段进行改进,但难以从根本上解决预训练数据带来的问题。
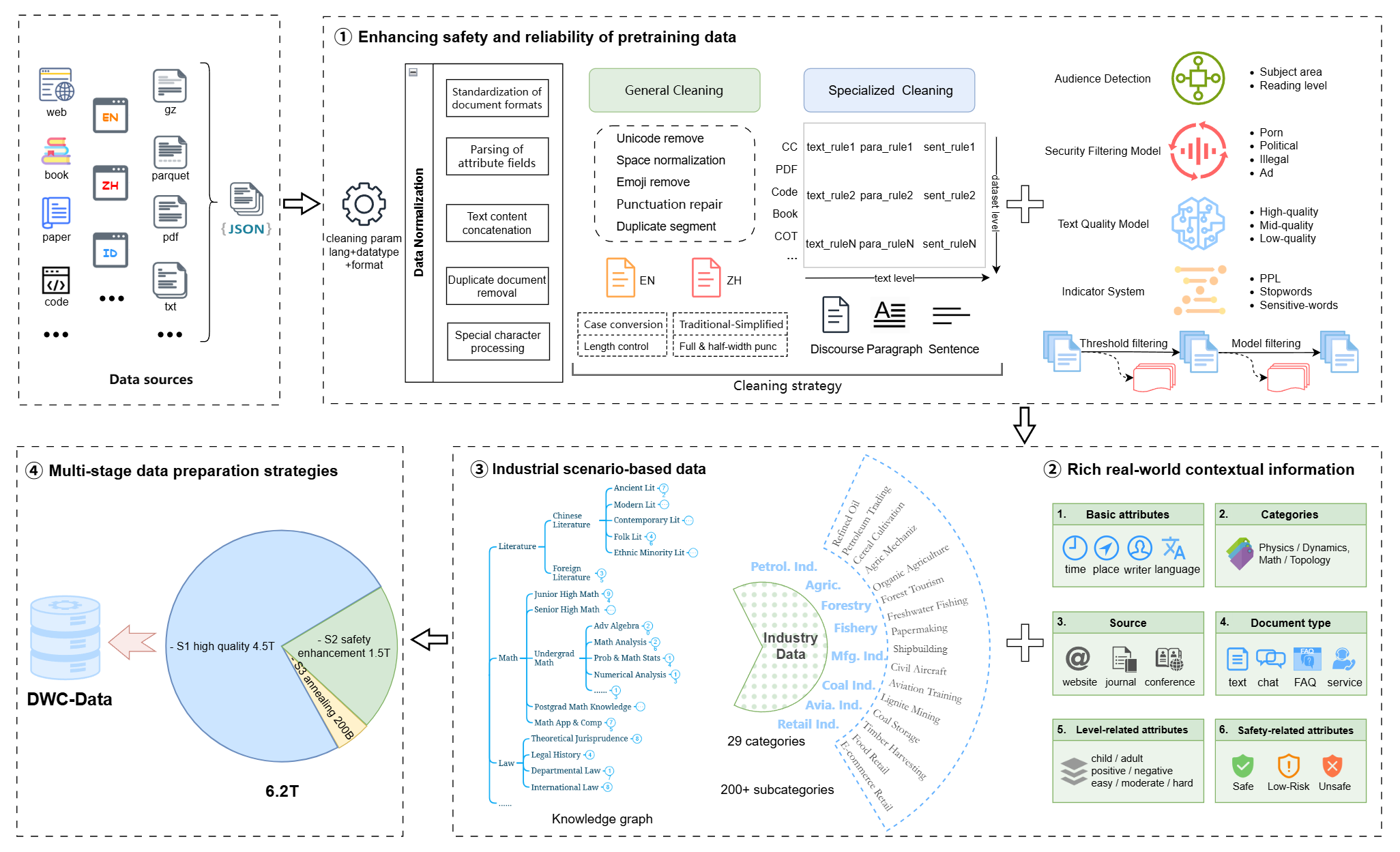
核心思路:论文的核心思路是通过增强预训练数据,使其包含更丰富的世界知识和工业场景信息,从而提高LLM的安全性和可信度。具体而言,论文提出将预训练数据与其产生的时空上下文相关联,使模型能够更好地理解数据的来源和含义,减少模型训练中的不确定性。同时,增加工业场景数据,使模型能够更好地适应实际应用需求。
技术框架:该方法主要包含以下几个阶段:1) 数据收集与增强:收集包含世界知识和工业场景信息的预训练数据,并使用DWC方法增强数据,将数据与其产生的时空上下文相关联。2) 预训练:使用增强后的数据继续预训练JT-35B-Base模型。3) 后训练:采用特定的后训练程序,激活DWC数据在预训练过程中学习到的知识,进一步提升模型的安全性和可信度。
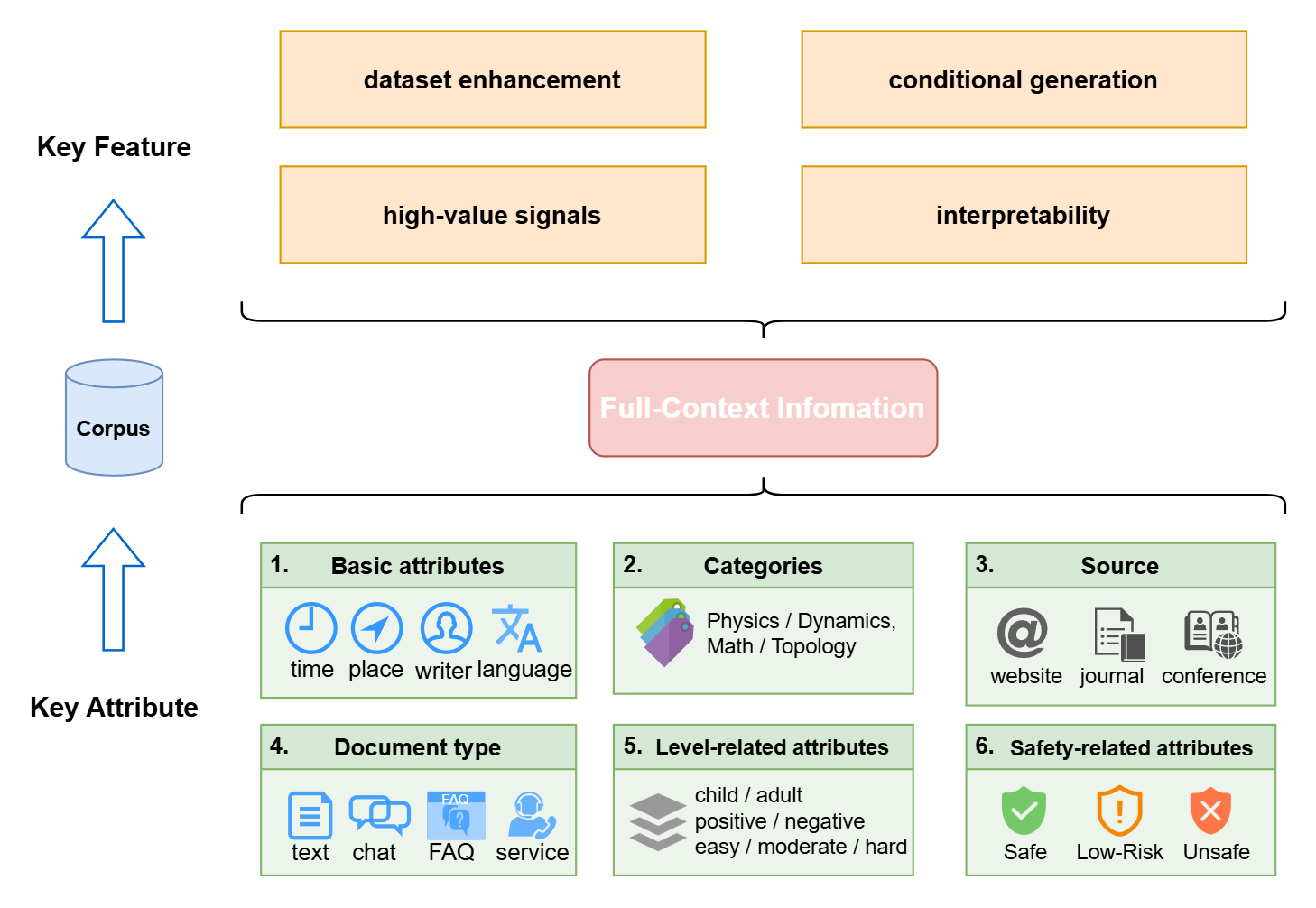
关键创新:该方法最重要的创新点在于提出了DWC(Data with World Context)的概念,强调预训练数据与现实世界上下文的关联。与传统的预训练方法不同,DWC方法不仅关注数据的文本内容,还关注数据的来源、产生时间、地点等信息,从而使模型能够更好地理解数据的含义和可信度。
关键设计:论文中没有详细描述DWC的具体实现方式,例如如何将时空上下文信息编码到预训练数据中,以及后训练程序的具体细节。这些细节可能涉及特定的参数设置、损失函数或网络结构,需要在后续研究中进一步探索。
🖼️ 关键图片
📊 实验亮点
实验结果表明,JT-Safe-35B在安全和可信评估基准上取得了显著的性能提升,平均提升幅度为1.79%,优于同等规模的Qwen模型。更重要的是,JT-Safe-35B仅使用了6.2万亿token进行预训练,而Qwen模型使用了更多的token,这表明DWC方法能够更有效地利用预训练数据,提高模型的训练效率。
🎯 应用场景
该研究成果可应用于各种需要高安全性和可信度的LLM应用场景,例如金融、医疗、法律等领域。通过增强LLM对现实世界的理解,可以减少模型产生错误或不安全输出的风险,提高用户对模型的信任度。未来,该方法还可以扩展到其他类型的预训练数据,例如图像、音频等,从而提升多模态模型的安全性和可信度。
📄 摘要(原文)
The hallucination and credibility concerns of large language models (LLMs) are global challenges that the industry is collectively addressing. Recently, a significant amount of advances have been made on post-training and inference techniques to mitigate these challenges. However, it is widely agreed that unsafe and hallucinations of LLMs intrinsically originate from pre-training, involving pre-training data and the next-token prediction learning mechanism. In this paper, we focus on enhancing pre-training data to improve the trustworthiness and safety of LLMs. Since the data is vast, it's almost impossible to entirely purge the data of factual errors, logical inconsistencies, or distributional biases. Moreover, the pre-training data lack grounding in real-world knowledge. Each piece of data is treated as a sequence of tokens rather than as a representation of a part of the world. To overcome these issues, we propose approaches to enhancing our pre-training data with its context in the world and increasing a substantial amount of data reflecting industrial scenarios. We argue that most source data are created by the authors for specific purposes in a certain spatial-temporal context. They have played a role in the real world. By incorporating related world context information, we aim to better anchor pre-training data within real-world scenarios, thereby reducing uncertainty in model training and enhancing the model's safety and trustworthiness. We refer to our Data with World Context as DWC. We continue pre-training an earlier checkpoint of JT-35B-Base with 1.5 trillion of DWC tokens. We introduce our post-training procedures to activate the potentials of DWC. Compared with the Qwen model of a similar scale, JT-Safe-35B achieves an average performance improvement of 1.79% on the Safety and Trustworthy evaluation benchmarks, while being pretrained with only 6.2 trillion tokens.