VERA-V: Variational Inference Framework for Jailbreaking Vision-Language Models
作者: Qilin Liao, Anamika Lochab, Ruqi Zhang
分类: cs.CR, cs.CL, cs.CV, cs.LG, stat.ML
发布日期: 2025-10-20
备注: 18 pages, 7 Figures,
💡 一句话要点
VERA-V:基于变分推断的框架,用于破解视觉-语言模型的防御机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 越狱攻击 变分推断 对抗样本 多模态安全
📋 核心要点
- 现有VLM破解方法依赖脆弱模板,仅关注单一攻击,未能充分挖掘模型漏洞。
- VERA-V将破解视为学习文本-图像提示的联合后验分布,生成隐蔽对抗样本。
- 实验表明,VERA-V在多个VLM上显著提升攻击成功率,超越现有方法。
📝 摘要(中文)
视觉-语言模型(VLMs)通过视觉推理扩展了大型语言模型,但其多模态设计也引入了新的、未被充分探索的漏洞。现有的多模态红队测试方法主要依赖于脆弱的模板,侧重于单次攻击设置,并且仅暴露了一小部分漏洞。为了解决这些限制,我们引入了VERA-V,这是一个变分推断框架,它将多模态越狱发现重新定义为学习配对文本-图像提示上的联合后验分布。这种概率视角能够生成隐蔽的、耦合的对抗性输入,绕过模型的保护措施。我们训练了一个轻量级的攻击者来近似后验分布,从而能够高效地采样各种越狱方法,并提供对漏洞的分布洞察。VERA-V进一步集成了三种互补策略:(i)基于排版的文本提示,嵌入有害线索,(ii)基于扩散的图像合成,引入对抗性信号,以及(iii)结构化的干扰物,以分散VLM的注意力。在HarmBench和HADES基准测试上的实验表明,VERA-V在开源和前沿VLM上始终优于最先进的基线,在GPT-4o上实现了高达53.75%的攻击成功率(ASR),超过了最佳基线。
🔬 方法详解
问题定义:现有的视觉-语言模型(VLM)红队测试方法存在局限性,主要依赖于预定义的模板,这些模板容易被防御机制识别。此外,这些方法通常只关注单一类型的攻击,无法全面地暴露VLM的潜在漏洞。因此,需要一种更有效、更通用的方法来发现和利用VLM的弱点。
核心思路:VERA-V的核心思路是将多模态越狱攻击问题转化为一个概率推断问题。具体来说,它通过学习一个联合后验分布来生成配对的文本-图像提示,这些提示能够有效地绕过VLM的防御机制。这种概率视角允许生成更多样化和隐蔽的对抗性输入,从而提高攻击的成功率。
技术框架:VERA-V框架包含以下几个主要组成部分:1) 一个轻量级的攻击者模型,用于近似文本-图像提示的联合后验分布。2) 三种互补的攻击策略:基于排版的文本提示、基于扩散模型的图像合成和结构化干扰物。3) 一个评估模块,用于评估生成的对抗性输入的有效性。整个流程包括训练攻击者模型,生成对抗性提示,以及评估攻击成功率。
关键创新:VERA-V的关键创新在于其将越狱攻击问题建模为一个变分推断问题。这种方法允许生成更多样化和隐蔽的对抗性输入,从而更有效地绕过VLM的防御机制。此外,VERA-V还集成了多种攻击策略,进一步提高了攻击的成功率。与现有方法相比,VERA-V不需要依赖预定义的模板,能够更全面地探索VLM的漏洞。
关键设计:VERA-V的关键设计包括:1) 使用变分自编码器(VAE)来近似文本-图像提示的联合后验分布。2) 设计了基于排版的文本提示,通过嵌入有害线索来引导VLM产生不期望的输出。3) 利用扩散模型生成对抗性图像,这些图像包含难以察觉的对抗性信号。4) 引入结构化干扰物来分散VLM的注意力,使其更容易受到攻击。
🖼️ 关键图片

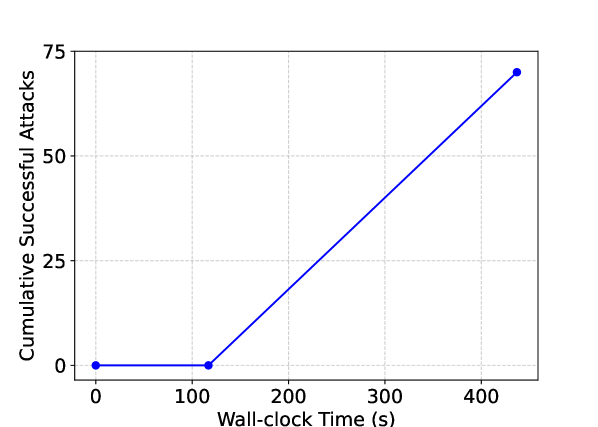
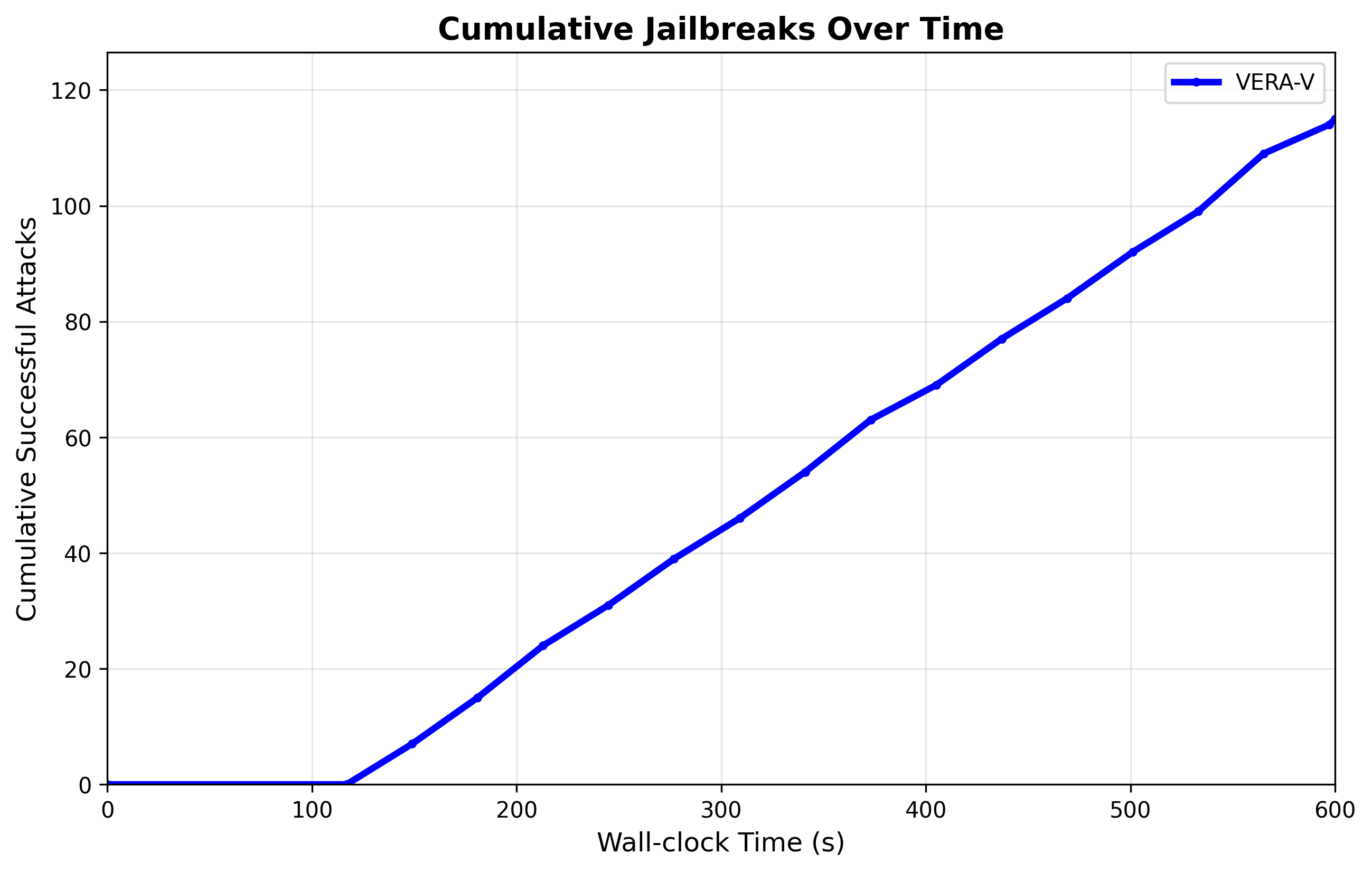
📊 实验亮点
VERA-V在HarmBench和HADES基准测试中显著优于现有方法,在GPT-4o上实现了高达53.75%的攻击成功率提升。实验结果表明,VERA-V能够有效地绕过各种VLM的防御机制,并发现新的、未知的漏洞。
🎯 应用场景
VERA-V可用于评估和提高视觉-语言模型的安全性,帮助开发者发现和修复潜在漏洞。该研究成果对于构建更安全可靠的多模态人工智能系统具有重要意义,尤其是在涉及敏感信息处理或决策的场景中,例如医疗诊断、金融风控等。
📄 摘要(原文)
Vision-Language Models (VLMs) extend large language models with visual reasoning, but their multimodal design also introduces new, underexplored vulnerabilities. Existing multimodal red-teaming methods largely rely on brittle templates, focus on single-attack settings, and expose only a narrow subset of vulnerabilities. To address these limitations, we introduce VERA-V, a variational inference framework that recasts multimodal jailbreak discovery as learning a joint posterior distribution over paired text-image prompts. This probabilistic view enables the generation of stealthy, coupled adversarial inputs that bypass model guardrails. We train a lightweight attacker to approximate the posterior, allowing efficient sampling of diverse jailbreaks and providing distributional insights into vulnerabilities. VERA-V further integrates three complementary strategies: (i) typography-based text prompts that embed harmful cues, (ii) diffusion-based image synthesis that introduces adversarial signals, and (iii) structured distractors to fragment VLM attention. Experiments on HarmBench and HADES benchmarks show that VERA-V consistently outperforms state-of-the-art baselines on both open-source and frontier VLMs, achieving up to 53.75% higher attack success rate (ASR) over the best baseline on GPT-4o.