AcademicEval: Live Long-Context LLM Benchmark
作者: Haozhen Zhang, Tao Feng, Pengrui Han, Jiaxuan You
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-20
备注: Accepted by TMLR. Code is available at https://github.com/ulab-uiuc/AcademicEval
🔗 代码/项目: GITHUB
💡 一句话要点
提出AcademicEval,一个长文本LLM的实时评测基准,解决现有基准的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 大型语言模型 实时评估 学术写作 Few-shot学习
📋 核心要点
- 现有长文本LLM基准存在上下文长度固定、标注成本高昂以及训练时标签泄露等问题。
- AcademicEval利用arXiv论文,构建无需人工标注的学术写作任务,并集成合作者图谱提供高质量的few-shot示例。
- 实验表明,LLM在处理分层抽象任务和长篇few-shot示例时表现不佳,揭示了长文本建模的挑战。
📝 摘要(中文)
大型语言模型(LLMs)最近在长文本理解方面取得了显著的性能。然而,当前的长文本LLM基准测试受到固定上下文长度、劳动密集型标注以及LLM训练期间标签泄露问题的限制。因此,我们提出了 extsc{AcademicEval},这是一个用于评估LLM在长文本生成任务上的实时基准。 extsc{AcademicEval} 采用 arXiv 上的论文,引入了几个具有长文本输入的学术写作任务,即 extsc{Title}、 extsc{Abstract}、 extsc{Introduction} 和 extsc{Related Work},涵盖了广泛的抽象级别,并且不需要手动标注。此外, extsc{AcademicEval} 集成了来自收集的合作者图的高质量和专家策划的少量样本演示,以实现灵活的上下文长度。 特别是, extsc{AcademicEval} 具有高效的实时评估,确保没有标签泄露。 我们对 extsc{AcademicEval} 进行了整体评估,结果表明 LLM 在具有分层抽象级别的任务中表现不佳,并且往往难以处理长篇少量样本演示,突出了我们基准测试的挑战。 通过实验分析,我们还揭示了一些增强 LLM 长文本建模能力的见解。
🔬 方法详解
问题定义:现有长文本语言模型评测基准存在三个主要痛点:一是上下文长度受限,无法充分评估模型处理超长文本的能力;二是需要大量人工标注,成本高昂且效率低下;三是在模型训练过程中容易出现标签泄露,导致评测结果失真。
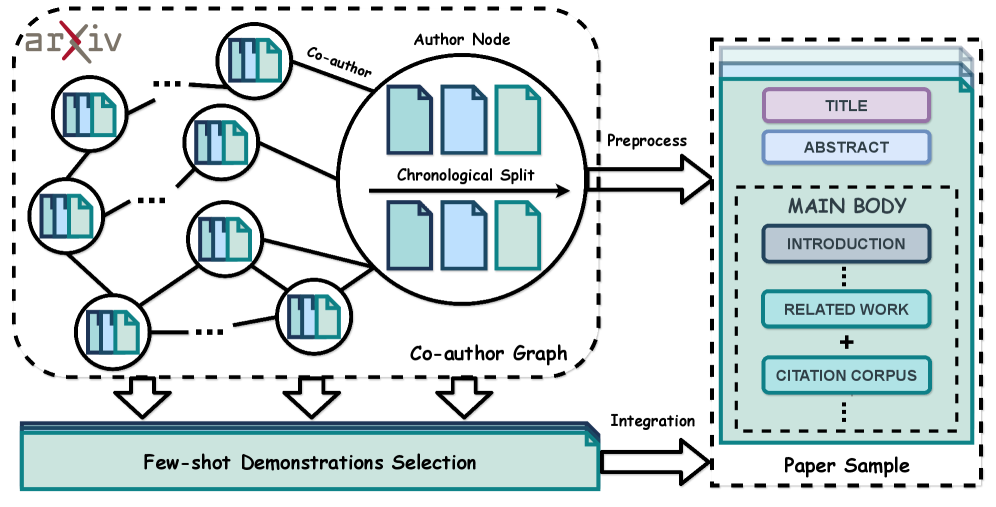
核心思路:AcademicEval的核心思路是利用arXiv上的学术论文作为数据来源,构建一系列长文本生成任务,包括标题生成、摘要生成、引言生成和相关工作生成。这些任务具有天然的长文本上下文,并且无需人工标注,从而避免了上述痛点。此外,该基准还引入了合作者图谱,用于提供高质量的few-shot示例,以支持不同长度的上下文输入。
技术框架:AcademicEval的整体框架包括数据收集、任务构建、模型评估和结果分析四个主要阶段。首先,从arXiv上收集大量的学术论文,并将其划分为不同的任务类型。然后,利用合作者图谱构建few-shot示例,并根据任务类型和上下文长度生成不同的评测样本。接着,使用不同的长文本语言模型对评测样本进行生成,并采用ROUGE等指标进行评估。最后,对评估结果进行分析,以揭示模型的优缺点和潜在的改进方向。
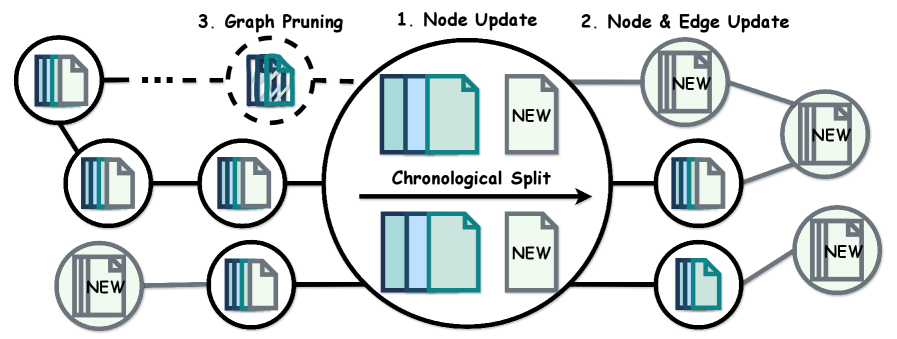
关键创新:AcademicEval最重要的技术创新点在于其采用了实时评估机制,可以有效避免标签泄露问题。具体来说,该基准会定期更新arXiv上的论文数据,并对模型进行重新评估,从而确保评测结果的公正性和客观性。此外,该基准还引入了合作者图谱,可以提供更加丰富和高质量的few-shot示例,从而提高模型的生成效果。
关键设计:AcademicEval的关键设计包括以下几个方面:一是任务类型的选择,选择了标题、摘要、引言和相关工作等具有代表性的学术写作任务;二是上下文长度的设置,支持不同长度的上下文输入,以评估模型处理超长文本的能力;三是评估指标的选择,采用了ROUGE等常用的文本生成评估指标;四是实时评估机制的实现,定期更新数据并重新评估模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在处理具有分层抽象级别的任务时表现不佳,尤其是在生成引言和相关工作等需要较高抽象概括的任务时。此外,LLM在处理长篇few-shot示例时也面临挑战,表明模型难以有效利用长上下文信息。这些结果突出了AcademicEval基准的挑战性,并为未来的研究提供了方向。
🎯 应用场景
AcademicEval可用于评估和提升大型语言模型在学术写作、报告生成、文档总结等领域的应用能力。通过该基准,研究人员可以更好地了解模型的长文本处理能力,并针对性地进行优化,从而推动LLM在科研和工程领域的广泛应用。
📄 摘要(原文)
Large Language Models (LLMs) have recently achieved remarkable performance in long-context understanding. However, current long-context LLM benchmarks are limited by rigid context length, labor-intensive annotation, and the pressing challenge of label leakage issues during LLM training. Therefore, we propose \textsc{AcademicEval}, a live benchmark for evaluating LLMs over long-context generation tasks. \textsc{AcademicEval} adopts papers on arXiv to introduce several academic writing tasks with long-context inputs, \textit{i.e.}, \textsc{Title}, \textsc{Abstract}, \textsc{Introduction}, and \textsc{Related Work}, which cover a wide range of abstraction levels and require no manual labeling. Moreover, \textsc{AcademicEval} integrates high-quality and expert-curated few-shot demonstrations from a collected co-author graph to enable flexible context length. Especially, \textsc{AcademicEval} features an efficient live evaluation, ensuring no label leakage. We conduct a holistic evaluation on \textsc{AcademicEval}, and the results illustrate that LLMs perform poorly on tasks with hierarchical abstraction levels and tend to struggle with long few-shot demonstrations, highlighting the challenge of our benchmark. Through experimental analysis, we also reveal some insights for enhancing LLMs' long-context modeling capabilities. Code is available at https://github.com/ulab-uiuc/AcademicEval