QueST: Incentivizing LLMs to Generate Difficult Problems
作者: Hanxu Hu, Xingxing Zhang, Jannis Vamvas, Rico Sennrich, Furu Wei
分类: cs.CL
发布日期: 2025-10-20
备注: 20 pages, 7 figures
💡 一句话要点
QueST:通过激励LLM生成高难度问题,提升代码能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 难题生成 语言模型 知识蒸馏 图采样
📋 核心要点
- 现有代码数据集规模有限,且人工标注成本高昂,阻碍了LLM在代码能力上的进一步提升。
- QueST框架通过难度感知的图采样和拒绝微调,优化生成器直接生成高难度代码问题。
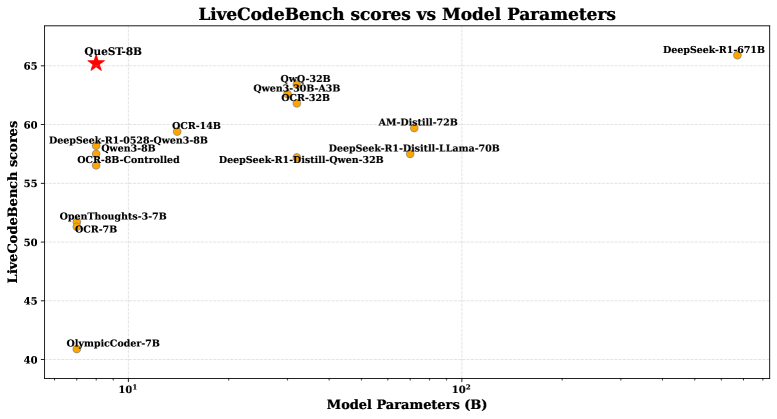
- 实验表明,QueST生成的难题能有效提升下游模型性能,甚至使8B模型媲美671B模型。
📝 摘要(中文)
大型语言模型在推理任务上表现出色,能够解决竞赛级别的代码和数学问题。然而,其可扩展性受到人工标注数据集和缺乏大规模、具有挑战性的代码问题训练数据的限制。现有的竞赛性编码数据集仅包含数千到数万个问题。以往的合成数据生成方法依赖于扩充现有的指令数据集或从人工标注数据中选择具有挑战性的问题。本文提出了一种新颖的框架QueST,它结合了难度感知的图采样和难度感知的拒绝微调,直接优化专门的生成器来创建具有挑战性的编码问题。我们训练的生成器在创建具有挑战性的问题方面表现出优于GPT-4o的能力,这些问题有利于下游性能。我们利用QueST生成大规模的合成编码问题,然后使用这些问题从具有长链思维的强大教师模型中进行知识蒸馏,或者对较小的模型进行强化学习,证明这两种方法都是有效的。我们的蒸馏实验表明了显著的性能提升。具体来说,在QueST生成的10万个难题上对Qwen3-8B-base进行微调后,我们超越了原始Qwen3-8B在LiveCodeBench上的性能。通过额外的11.2万个例子(即2.8万个人工编写的问题与多个合成解决方案配对),我们的8B模型与更大的DeepSeek-R1-671B的性能相匹配。这些发现表明,通过QueST生成复杂问题为推进大型语言模型的竞争性编码和推理领域提供了一种有效且可扩展的方法。
🔬 方法详解
问题定义:论文旨在解决缺乏大规模、具有挑战性的代码问题训练数据的问题,现有方法依赖人工标注或简单扩充,无法有效生成高难度问题,限制了LLM在代码能力上的提升。
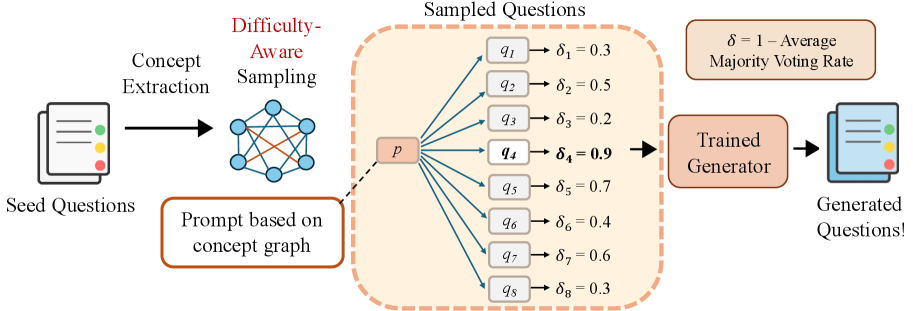
核心思路:论文的核心思路是训练专门的生成器,使其能够直接生成具有挑战性的代码问题。通过难度感知的图采样和拒绝微调,引导生成器生成更复杂、更需要推理的问题。
技术框架:QueST框架包含两个主要阶段:难度感知的图采样和难度感知的拒绝微调。首先,利用图采样策略从代码问题的潜在空间中选择具有挑战性的问题。然后,通过拒绝微调,训练生成器生成与采样问题难度相匹配的问题。整个流程旨在优化生成器,使其能够生成高质量、高难度的代码问题。
关键创新:最重要的技术创新点在于难度感知的图采样和拒绝微调机制。传统方法通常依赖于人工标注或简单的数据增强,而QueST能够自动探索问题空间,并根据难度进行优化,从而生成更具挑战性的问题。
关键设计:难度感知的图采样可能涉及到构建代码问题之间的关系图,并设计采样策略以选择图中更难到达或连接更稀疏的节点。拒绝微调可能涉及到设计奖励函数,鼓励生成器生成难度更高的样本,并惩罚生成难度较低的样本。具体的参数设置和损失函数细节可能在论文中有更详细的描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在QueST生成的10万个难题上微调Qwen3-8B-base后,模型在LiveCodeBench上的性能超越了原始Qwen3-8B。更令人瞩目的是,通过结合人工编写的问题和QueST生成的合成解决方案,一个8B模型能够达到与DeepSeek-R1-671B相媲美的性能。
🎯 应用场景
QueST框架可应用于各种需要代码能力的场景,例如自动代码生成、代码调试、智能编程助手等。通过生成高质量的训练数据,可以提升LLM在这些领域的性能,加速相关应用的落地。此外,该方法也可推广到其他需要复杂推理的任务中,例如数学问题生成、逻辑推理问题生成等。
📄 摘要(原文)
Large Language Models have achieved strong performance on reasoning tasks, solving competition-level coding and math problems. However, their scalability is limited by human-labeled datasets and the lack of large-scale, challenging coding problem training data. Existing competitive coding datasets contain only thousands to tens of thousands of problems. Previous synthetic data generation methods rely on either augmenting existing instruction datasets or selecting challenging problems from human-labeled data. In this paper, we propose QueST, a novel framework which combines difficulty-aware graph sampling and difficulty-aware rejection fine-tuning that directly optimizes specialized generators to create challenging coding problems. Our trained generators demonstrate superior capability compared to even GPT-4o at creating challenging problems that benefit downstream performance. We leverage QueST to generate large-scale synthetic coding problems, which we then use to distill from strong teacher models with long chain-of-thought or to conduct reinforcement learning for smaller models, proving effective in both scenarios. Our distillation experiments demonstrate significant performance gains. Specifically, after fine-tuning Qwen3-8B-base on 100K difficult problems generated by QueST, we surpass the performance of the original Qwen3-8B on LiveCodeBench. With an additional 112K examples (i.e., 28K human-written problems paired with multiple synthetic solutions), our 8B model matches the performance of the much larger DeepSeek-R1-671B. These findings indicate that generating complex problems via QueST offers an effective and scalable approach to advancing the frontiers of competitive coding and reasoning for large language models.