Qomhra: A Bilingual Irish and English Large Language Model
作者: Joseph McInerney, Khanh-Tung Tran, Liam Lonergan, Ailbhe Ní Chasaide, Neasa Ní Chiaráin, Barry Devereux
分类: cs.CL
发布日期: 2025-10-20 (更新: 2026-01-08)
💡 一句话要点
Qomhrá:一种爱尔兰语-英语双语大语言模型,解决低资源语言LLM的构建问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源语言 大语言模型 爱尔兰语 双语模型 指令微调 人类偏好 知识迁移
📋 核心要点
- 现有大语言模型主要集中在世界主要语言上,导致爱尔兰语等低资源语言的代表性不足,缺乏有效的LLM。
- 论文提出Qomhrá,一种爱尔兰语-英语双语LLM,通过双语预训练、指令微调和合成人类偏好数据进行构建。
- 实验结果表明,Qomhrá在爱尔兰语和英语上的性能分别提升高达29%和44%,优于现有开源爱尔兰语LLM基线。
📝 摘要(中文)
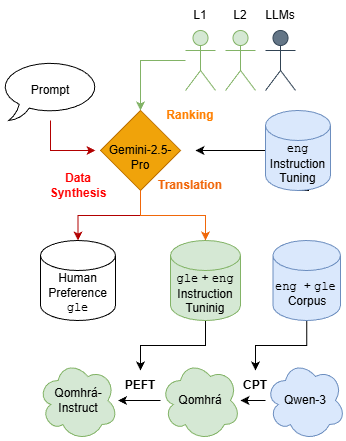
本文介绍了Qomhrá,一个在极低资源约束下开发的爱尔兰语-英语双语大语言模型(LLM)。文章概述了一个完整的流程,包括双语持续预训练、指令微调以及合成人类偏好数据以供未来对齐训练。由于缺乏可扩展的方法来创建人类偏好数据,本文提出了一种新颖的方法,即提示一个LLM生成“接受”和“拒绝”的响应,并验证其与母语为爱尔兰语的人的偏好对齐。为了选择用于合成的LLM,本文评估了顶级闭源LLM的爱尔兰语生成性能。母语和第二语言为爱尔兰语的人都将Gemini-2.5-Pro评为最高,这与LLM作为评判者的评分不同,表明当前LLM与爱尔兰语社区之间存在不一致。随后,本文利用Gemini-2.5-Pro将大规模英语指令微调数据集翻译成爱尔兰语,并合成了一个首创的爱尔兰语人类偏好数据集。本文在多个基准上全面评估了Qomhrá,测试了翻译、性别理解、主题识别和世界知识;这些评估表明,与现有的开源爱尔兰语LLM基线UCCIX相比,爱尔兰语的性能提升高达29%,英语的性能提升高达44%。本文的结果为开发爱尔兰语和其他低资源语言的LLM提供了见解和指导。
🔬 方法详解
问题定义:论文旨在解决低资源语言(如爱尔兰语)的大语言模型构建问题。现有方法主要集中在高资源语言上,导致低资源语言缺乏高质量的LLM。此外,缺乏可扩展的方法来创建低资源语言的人类偏好数据,阻碍了LLM的对齐训练。
核心思路:论文的核心思路是利用现有的高性能LLM(如Gemini-2.5-Pro)作为知识迁移的桥梁,通过翻译和合成数据的方式,为低资源语言构建训练数据。同时,通过人工评估来验证合成数据的质量,确保与目标语言社区的偏好对齐。
技术框架:整体框架包括以下几个阶段:1) 选择合适的LLM作为知识迁移的源模型;2) 将大规模英语指令微调数据集翻译成爱尔兰语;3) 利用源模型合成爱尔兰语人类偏好数据集;4) 使用合成的数据集对目标LLM进行训练和微调;5) 在多个基准上评估目标LLM的性能。
关键创新:最重要的技术创新点是提出了一种新颖的合成人类偏好数据的方法。该方法通过提示LLM生成“接受”和“拒绝”的响应,从而模拟人类的偏好。这种方法可以有效地解决低资源语言缺乏人工标注数据的问题。
关键设计:论文的关键设计包括:1) 使用Gemini-2.5-Pro作为知识迁移的源模型,因为它在爱尔兰语生成方面表现最佳;2) 通过人工评估来验证合成数据的质量,确保与爱尔兰语社区的偏好对齐;3) 在多个基准上全面评估Qomhrá的性能,包括翻译、性别理解、主题识别和世界知识。
🖼️ 关键图片
📊 实验亮点
Qomhrá在多个基准测试中表现出色,与现有的开源爱尔兰语LLM基线UCCIX相比,在爱尔兰语的性能提升高达29%,英语的性能提升高达44%。人工评估表明,Gemini-2.5-Pro在爱尔兰语生成方面表现最佳,但LLM作为评判者的评分与人工评估结果存在差异,揭示了现有LLM与爱尔兰语社区之间的不一致。
🎯 应用场景
该研究成果可应用于爱尔兰语相关的自然语言处理任务,如机器翻译、文本生成、对话系统等。同时,该方法也为其他低资源语言的LLM开发提供了借鉴,有助于推动多语言自然语言处理的发展,促进文化多样性。
📄 摘要(原文)
Large language model (LLM) research and development has overwhelmingly focused on the world's major languages, leading to under-representation of low-resource languages such as Irish. This paper introduces \textbf{Qomhrá}, a bilingual Irish and English LLM, developed under extremely low-resource constraints. A complete pipeline is outlined spanning bilingual continued pre-training, instruction tuning, and the synthesis of human preference data for future alignment training. We focus on the lack of scalable methods to create human preference data by proposing a novel method to synthesise such data by prompting an LLM to generate
accepted'' andrejected'' responses, which we validate as aligning with L1 Irish speakers. To select an LLM for synthesis, we evaluate the top closed-weight LLMs for Irish language generation performance. Gemini-2.5-Pro is ranked highest by L1 and L2 Irish-speakers, diverging from LLM-as-a-judge ratings, indicating a misalignment between current LLMs and the Irish-language community. Subsequently, we leverage Gemini-2.5-Pro to translate a large scale English-language instruction tuning dataset to Irish and to synthesise a first-of-its-kind Irish-language human preference dataset. We comprehensively evaluate Qomhrá across several benchmarks, testing translation, gender understanding, topic identification, and world knowledge; these evaluations show gains of up to 29\% in Irish and 44\% in English compared to the existing open-source Irish LLM baseline, UCCIX. The results of our framework provide insight and guidance to developing LLMs for both Irish and other low-resource languages.