Forget to Know, Remember to Use: Context-Aware Unlearning for Large Language Models
作者: Yuefeng Peng, Parnian Afshar, Megan Ganji, Thomas Butler, Amir Houmansadr, Mingxian Wang, Dezhi Hong
分类: cs.CL
发布日期: 2025-10-20
💡 一句话要点
提出上下文感知遗忘学习方法,提升大语言模型遗忘特定知识后的可用性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 遗忘学习 上下文感知 知识移除 模型可用性
📋 核心要点
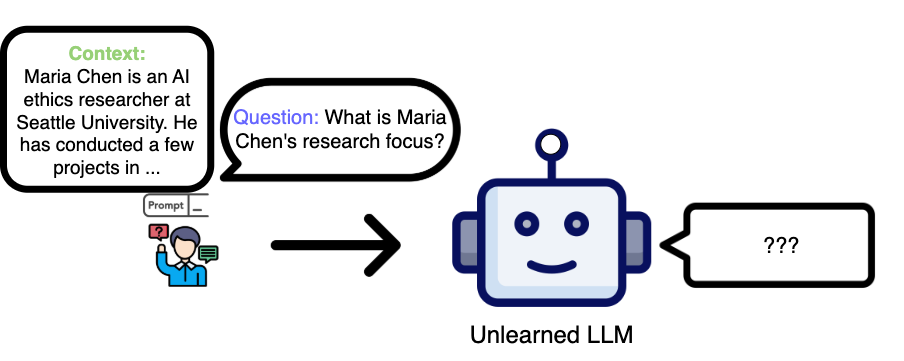
- 现有遗忘学习方法在移除知识的同时,会损害模型利用上下文中已删除信息的能力,降低了可用性。
- 论文提出上下文感知的遗忘学习方法,通过增加一个插件项,使模型在上下文中存在已遗忘知识时仍能利用。
- 实验表明,该方法在保持有效遗忘和保留集效用的同时,显著恢复了模型的上下文效用。
📝 摘要(中文)
大型语言模型可能编码敏感信息或过时知识,需要移除以确保模型负责任且合规的响应。遗忘学习作为一种高效的替代方案,旨在移除特定知识,同时保持模型的整体效用。现有遗忘学习方法的评估侧重于(1)目标知识的遗忘程度(遗忘集)和(2)保持在保留集上的性能(即效用)。然而,这些评估忽略了一个重要的可用性方面:如果用户在提示中重新引入已删除的信息,他们可能仍然希望模型能够利用这些信息。通过对六种最先进的遗忘学习方法进行系统评估,我们发现它们始终会损害这种上下文效用。为了解决这个问题,我们使用一个插件项来增强遗忘学习目标,该插件项保留了模型在上下文中存在已遗忘知识时使用这些知识的能力。大量的实验表明,我们的方法将上下文效用恢复到接近原始水平,同时仍然保持有效的遗忘和保留集效用。
🔬 方法详解
问题定义:现有的大语言模型遗忘学习方法,在移除特定知识后,虽然在遗忘集上表现良好,并且在保留集上保持了性能,但是当用户在prompt中重新引入已遗忘的知识时,模型无法像原始模型一样利用这些信息,即上下文利用能力下降。这限制了遗忘学习的实际应用,因为用户可能希望模型在特定上下文中仍然能够使用这些知识。
核心思路:论文的核心思路是在遗忘学习的过程中,加入一个额外的目标,即保持模型在特定上下文中利用已遗忘知识的能力。具体来说,就是在训练过程中,让模型在看到包含已遗忘知识的上下文时,仍然能够产生与原始模型相似的输出。这样,模型就既能遗忘不需要的知识,又能根据上下文灵活地利用这些知识。
技术框架:该方法是在现有的遗忘学习框架上进行改进的,属于一种插件式方法。整体框架包括:1) 现有的遗忘学习方法(例如,微调、梯度上升等);2) 一个上下文感知模块,用于判断当前输入是否包含已遗忘的知识;3) 一个损失函数,用于衡量模型在包含已遗忘知识的上下文中的输出与原始模型输出的差异。通过最小化这个损失函数,可以使模型在特定上下文中仍然能够利用已遗忘的知识。
关键创新:关键创新在于提出了“上下文效用”这一概念,并设计了一个插件式的损失函数来保持这种效用。与以往只关注遗忘集和保留集性能的遗忘学习方法不同,该方法更加关注模型的实际可用性,使得模型在遗忘特定知识的同时,仍然能够根据上下文灵活地利用这些知识。
关键设计:关键设计在于上下文感知模块和损失函数的设计。上下文感知模块需要能够准确地判断当前输入是否包含已遗忘的知识,可以使用关键词匹配、语义相似度计算等方法。损失函数需要能够有效地衡量模型在包含已遗忘知识的上下文中的输出与原始模型输出的差异,可以使用KL散度、余弦相似度等方法。论文中具体使用了何种设计未知。
🖼️ 关键图片
📊 实验亮点
论文对六种最先进的遗忘学习方法进行了系统评估,发现它们都会损害模型的上下文效用。通过引入提出的上下文感知遗忘学习方法,可以将上下文效用恢复到接近原始水平,同时保持有效的遗忘和保留集效用。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于各种需要对大语言模型进行知识移除的场景,例如:移除模型中存在的偏见信息、删除过时的知识、防止模型泄露敏感数据等。通过保持模型的上下文效用,可以提高遗忘学习的实用性,使得模型在移除不需要的知识的同时,仍然能够根据上下文灵活地利用这些知识,从而更好地服务于用户。
📄 摘要(原文)
Large language models may encode sensitive information or outdated knowledge that needs to be removed, to ensure responsible and compliant model responses. Unlearning has emerged as an efficient alternative to full retraining, aiming to remove specific knowledge while preserving overall model utility. Existing evaluations of unlearning methods focus on (1) the extent of forgetting of the target knowledge (forget set) and (2) maintaining performance on the retain set (i.e., utility). However, these evaluations overlook an important usability aspect: users may still want the model to leverage the removed information if it is re-introduced in the prompt. In a systematic evaluation of six state-of-the-art unlearning methods, we find that they consistently impair such contextual utility. To address this, we augment unlearning objectives with a plug-in term that preserves the model's ability to use forgotten knowledge when it is present in context. Extensive experiments demonstrate that our approach restores contextual utility to near original levels while still maintaining effective forgetting and retain-set utility.