Language Confusion Gate: Language-Aware Decoding Through Model Self-Distillation
作者: Collin Zhang, Fei Huang, Chenhan Yuan, Junyang Lin
分类: cs.CL
发布日期: 2025-10-20
🔗 代码/项目: GITHUB
💡 一句话要点
提出语言混淆门以解决语言混淆问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 语言混淆 自蒸馏 文本生成 多语言处理
📋 核心要点
- 核心问题:现有方法无法有效区分有害的语言混淆与可接受的代码切换,且往往需要重新训练模型。
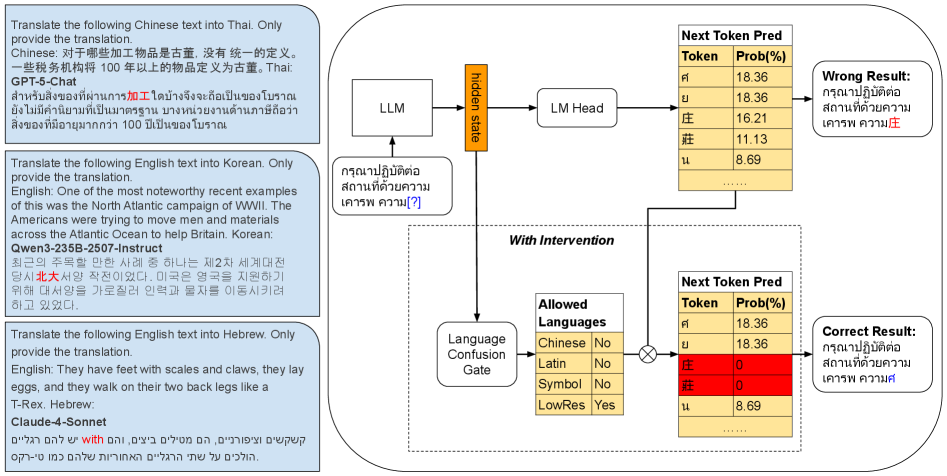
- 方法要点:提出语言混淆门(LCG),通过自蒸馏训练预测语言家族,仅在必要时进行令牌掩蔽。
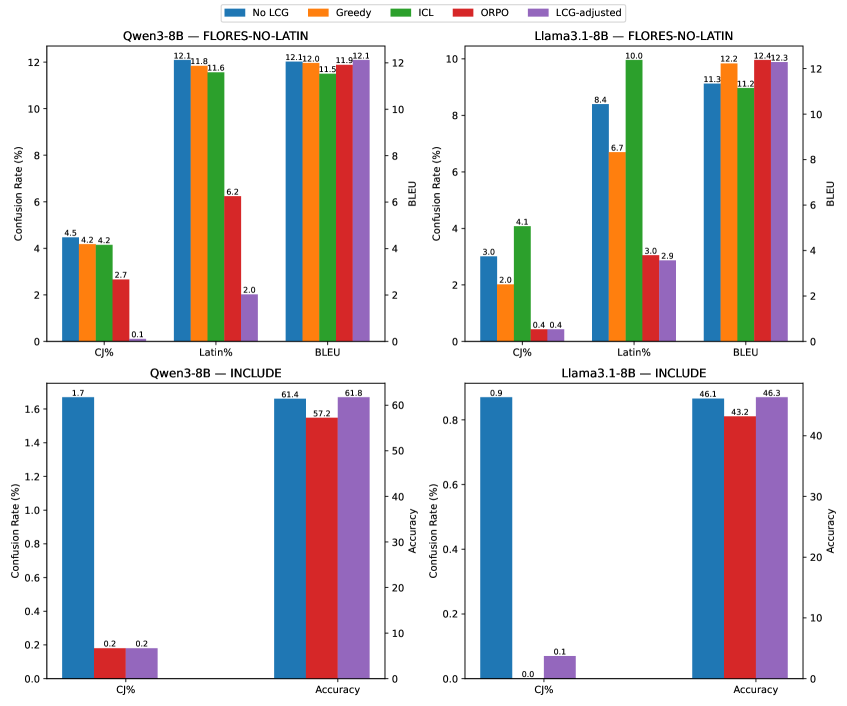
- 实验或效果:在多种模型上评估,LCG显著降低语言混淆,通常减少一个数量级,且不影响任务性能。
📝 摘要(中文)
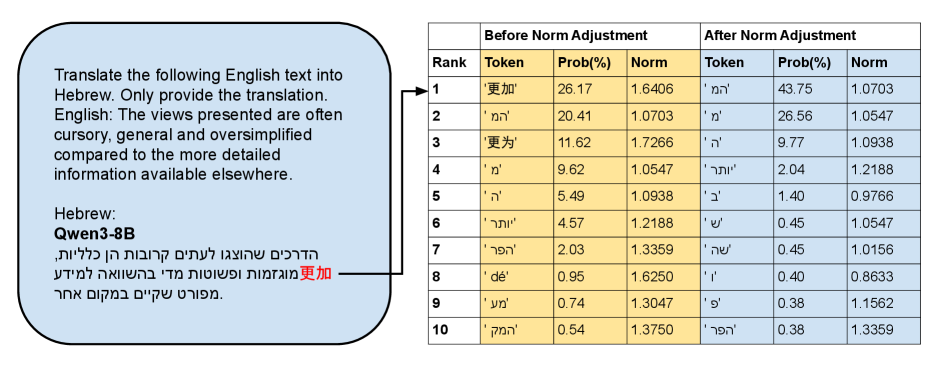
大型语言模型(LLMs)在文本生成过程中常常出现语言混淆,即在生成文本时无意中混合多种语言。现有解决方案要么需要重新训练模型,要么无法区分有害的混淆与可接受的代码切换。本文提出了一种轻量级的插件解决方案——语言混淆门(LCG),该方法在解码过程中过滤令牌,而不改变基础LLM。LCG通过规范调整的自蒸馏训练来预测合适的语言家族,仅在必要时应用掩蔽。研究表明,语言混淆发生频率较低,正确语言的令牌通常位于预测的前列,且高资源语言的输出令牌嵌入范数较大,导致采样偏差。经过多种模型的评估,包括Qwen3、GPT-OSS、Gemma3和Llama3.1,LCG显著降低了语言混淆,通常减少一个数量级,同时不影响任务性能。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在文本生成中出现的语言混淆问题。现有方法往往需要重新训练模型,且无法有效区分有害混淆与可接受的代码切换,导致生成质量下降。
核心思路:论文提出的语言混淆门(LCG)是一种轻量级的插件解决方案,通过自蒸馏训练来预测合适的语言家族,并在必要时对生成的令牌进行掩蔽,从而减少语言混淆。
技术框架:LCG的整体架构包括输入令牌的处理、语言家族的预测和掩蔽机制。首先,输入令牌被送入模型进行处理,随后通过自蒸馏训练预测语言家族,最后根据预测结果对令牌进行掩蔽。
关键创新:LCG的主要创新在于其轻量级设计和自蒸馏训练方法,使其能够在不改变基础LLM的情况下有效减少语言混淆。这与现有方法的重训练需求形成鲜明对比。
关键设计:在设计中,LCG使用了规范调整的自蒸馏训练,重点关注语言家族的预测准确性。模型的损失函数经过调整,以优化语言混淆的减少效果,同时保持生成任务的性能。具体的参数设置和网络结构细节在实验部分进行了详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LCG在多个模型上显著降低了语言混淆,通常减少一个数量级。与基线模型相比,LCG在保持任务性能的同时,成功减少了不必要的语言混淆,展示了其有效性和实用性。
🎯 应用场景
该研究的潜在应用领域包括多语言文本生成、机器翻译和跨语言信息检索等。通过有效减少语言混淆,LCG能够提升多语言模型的生成质量,促进不同语言之间的流畅交互,具有重要的实际价值和未来影响。
📄 摘要(原文)
Large language models (LLMs) often experience language confusion, which is the unintended mixing of languages during text generation. Current solutions to this problem either necessitate model retraining or cannot differentiate between harmful confusion and acceptable code-switching. This paper introduces the Language Confusion Gate (LCG), a lightweight, plug-in solution that filters tokens during decoding without altering the base LLM. The LCG is trained using norm-adjusted self-distillation to predict appropriate language families and apply masking only when needed. Our method is based on the findings that language confusion is infrequent, correct-language tokens are usually among the top predictions, and output token embedding norms are larger for high-resource languages, which biases sampling. When evaluated across various models, including Qwen3, GPT-OSS, Gemma3, Llama3.1, LCG decreases language confusion significantly, often by an order of magnitude, without negatively impacting task performance. Code is available at https://github.com/collinzrj/language_confusion_gate.