OncoReason: Structuring Clinical Reasoning in LLMs for Robust and Interpretable Survival Prediction
作者: Raghu Vamshi Hemadri, Geetha Krishna Guruju, Kristi Topollai, Anna Ewa Choromanska
分类: cs.CL, cs.LG
发布日期: 2025-10-20
💡 一句话要点
OncoReason:利用LLM中的临床推理结构,实现稳健且可解释的生存预测
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 临床推理 生存预测 多任务学习 可解释性 强化学习 精准肿瘤学
📋 核心要点
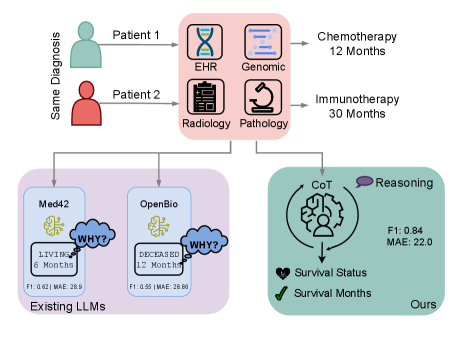
- 现有方法在异构临床数据下进行癌症治疗结果预测时,缺乏足够的准确性和可解释性,尤其是在高风险决策支持方面。
- 提出OncoReason框架,通过多任务学习将大型语言模型与临床推理对齐,联合执行生存分类、生存时间回归和理由生成。
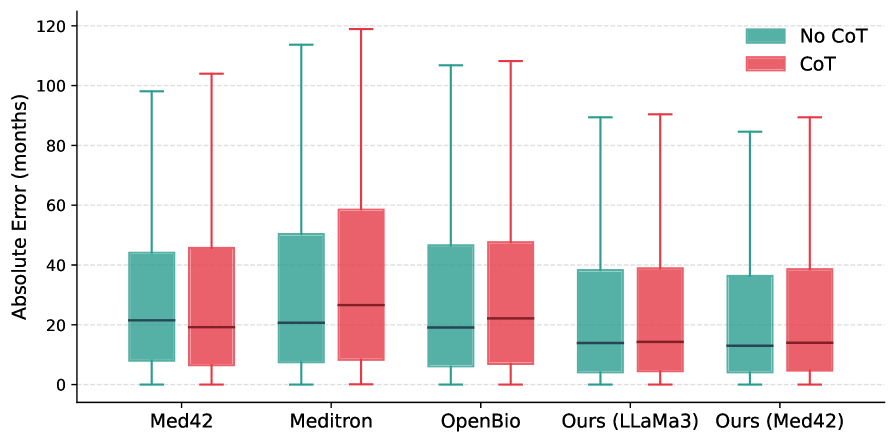
- 实验结果表明,思维链提示和组相对策略优化等对齐策略显著提升了模型的预测性能和可解释性,并设立了新的基准。
📝 摘要(中文)
预测癌症治疗结果需要准确且可解释的模型,尤其是在存在异构临床数据的情况下。大型语言模型(LLMs)在生物医学自然语言处理(NLP)中表现出色,但通常缺乏高风险决策支持所需的结构化推理能力。本文提出了一个统一的多任务学习框架,将自回归LLM与临床推理对齐,以预测MSK-CHORD数据集上的结果。模型经过训练,可以联合执行二元生存分类、连续生存时间回归和自然语言理由生成。评估了三种对齐策略:(1)标准监督微调(SFT),(2)使用思维链(CoT)提示的SFT以引出逐步推理,以及(3)组相对策略优化(GRPO),一种强化学习方法,可将模型输出与专家推导的推理轨迹对齐。使用LLaMa3-8B和Med42-8B主干的实验表明,CoT提示将F1提高了+6.0,并将MAE降低了12%,而GRPO在BLEU,ROUGE和BERTScore上实现了最先进的可解释性和预测性能。进一步表明,由于架构限制,现有的生物医学LLM通常无法产生有效的推理轨迹。研究结果强调了多任务临床建模中推理感知对齐的重要性,并为精准肿瘤学中可解释、可信赖的LLM设定了新的基准。
🔬 方法详解
问题定义:论文旨在解决癌症治疗结果预测中,现有模型在处理异构临床数据时准确性和可解释性不足的问题。现有方法,特别是直接应用大型语言模型,缺乏结构化的临床推理能力,难以提供可靠的决策支持。
核心思路:论文的核心思路是将大型语言模型与临床推理过程对齐,使其能够像医生一样逐步推理,并给出预测结果的理由。通过多任务学习,模型同时学习生存预测和理由生成,从而提高预测的准确性和可解释性。
技术框架:OncoReason框架是一个统一的多任务学习框架,包含以下几个主要模块:1) 数据输入模块:处理MSK-CHORD数据集中的异构临床数据。2) LLM主干网络:使用LLaMa3-8B或Med42-8B作为基础模型。3) 多任务学习模块:同时进行二元生存分类、连续生存时间回归和自然语言理由生成。4) 对齐策略模块:采用监督微调(SFT)、思维链提示(CoT)和组相对策略优化(GRPO)等方法,将LLM的输出与临床推理过程对齐。
关键创新:论文的关键创新在于提出了基于强化学习的组相对策略优化(GRPO)方法,能够有效地将模型输出与专家推导的推理轨迹对齐,从而显著提高模型的可解释性和预测性能。此外,论文还发现现有的生物医学LLM由于架构限制,难以产生有效的推理轨迹,强调了推理感知对齐的重要性。
关键设计:在CoT提示中,模型被要求逐步解释其推理过程,例如“首先,...然后,...最后,...”。GRPO方法使用专家提供的推理轨迹作为奖励信号,通过强化学习优化模型的策略,使其能够生成更符合临床推理逻辑的理由。损失函数包括分类损失、回归损失和理由生成损失,通过调整权重平衡不同任务之间的学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoT提示将F1提高了+6.0,并将MAE降低了12%。GRPO方法在BLEU、ROUGE和BERTScore等指标上实现了最先进的可解释性和预测性能。研究还发现,现有的生物医学LLM由于架构限制,难以产生有效的推理轨迹,强调了推理感知对齐的重要性。
🎯 应用场景
OncoReason框架可应用于精准肿瘤学领域,为医生提供更准确、可解释的癌症治疗决策支持。该研究有助于开发更值得信赖的AI辅助诊断工具,提高治疗效果,并减少不必要的医疗干预。未来,该方法可以扩展到其他疾病的诊断和治疗,促进医疗人工智能的发展。
📄 摘要(原文)
Predicting cancer treatment outcomes requires models that are both accurate and interpretable, particularly in the presence of heterogeneous clinical data. While large language models (LLMs) have shown strong performance in biomedical NLP, they often lack structured reasoning capabilities critical for high-stakes decision support. We present a unified, multi-task learning framework that aligns autoregressive LLMs with clinical reasoning for outcome prediction on the MSK-CHORD dataset. Our models are trained to jointly perform binary survival classification, continuous survival time regression, and natural language rationale generation. We evaluate three alignment strategies: (1) standard supervised fine-tuning (SFT), (2) SFT with Chain-of-Thought (CoT) prompting to elicit step-by-step reasoning, and (3) Group Relative Policy Optimization (GRPO), a reinforcement learning method that aligns model outputs to expert-derived reasoning trajectories. Experiments with LLaMa3-8B and Med42-8B backbones demonstrate that CoT prompting improves F1 by +6.0 and reduces MAE by 12%, while GRPO achieves state-of-the-art interpretability and predictive performance across BLEU, ROUGE, and BERTScore. We further show that existing biomedical LLMs often fail to produce valid reasoning traces due to architectural constraints. Our findings underscore the importance of reasoning-aware alignment in multi-task clinical modeling and set a new benchmark for interpretable, trustworthy LLMs in precision oncology.