Annotation-Efficient Universal Honesty Alignment
作者: Shiyu Ni, Keping Bi, Jiafeng Guo, Minghao Tang, Jingtong Wu, Zengxin Han, Xueqi Cheng
分类: cs.CL
发布日期: 2025-10-20
💡 一句话要点
提出EliCal框架以实现高效的诚实对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 诚实对齐 自一致性监督 校准方法 高效标注
📋 核心要点
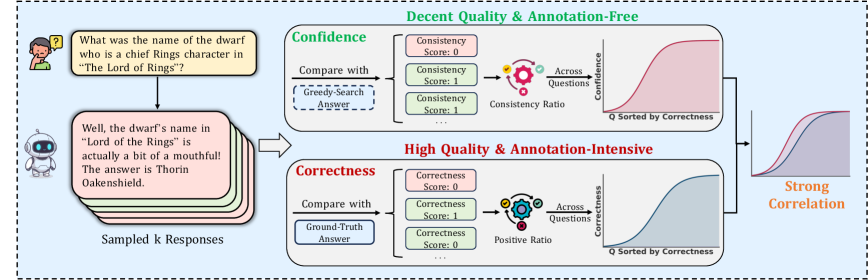
- 现有方法要么依赖无训练的信心估计,要么需要大量标注进行训练,导致成本高昂。
- 本文提出EliCal框架,通过自一致性监督引导信心,再用少量标注进行校准,从而实现高效的诚实对齐。
- 实验结果显示,EliCal在仅使用1k标注的情况下,达到了接近最佳的对齐效果,并在新任务上表现优于基线。
📝 摘要(中文)
诚实对齐是大型语言模型(LLMs)识别知识边界并表达校准信心的能力,对可信部署至关重要。现有方法依赖于无训练的信心估计或基于训练的校准,后者需要大量标注。为支持高效标注训练,本文提出了Elicitation-Then-Calibration(EliCal)框架,首先通过低成本的自一致性监督引导内部信心,然后用少量正确性标注进行校准。我们发布了HonestyBench基准,涵盖十个自由形式的问答数据集,包含560k训练和70k评估实例。实验表明,EliCal仅需1k正确性标注(占全监督的0.18%)即可实现近乎最佳的对齐,并在未见的MMLU任务上表现优于仅校准的基线,提供了可扩展的解决方案。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在可信部署中缺乏有效的诚实对齐问题。现有方法在信心估计和校准上存在高标注成本的痛点。
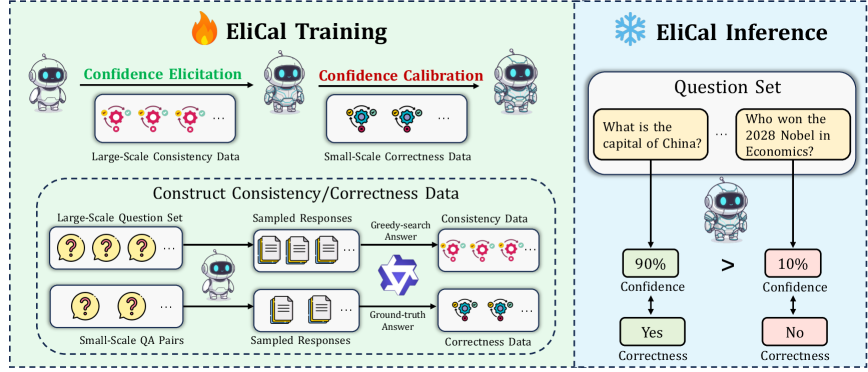
核心思路:EliCal框架的核心思路是通过自一致性监督低成本地引导模型的内部信心,然后利用少量的正确性标注进行校准,以实现高效的诚实对齐。
技术框架:EliCal框架分为两个主要阶段:第一阶段是通过自一致性监督引导信心,第二阶段是使用小规模的正确性标注进行校准。
关键创新:最重要的创新点在于通过自一致性监督引导信心,显著降低了对大量标注的依赖,从而实现了高效的诚实对齐。
关键设计:在设计中,EliCal使用了自一致性损失函数来引导信心,并通过少量的正确性标注进行校准,确保模型在不同任务上的一致性和准确性。
🖼️ 关键图片
📊 实验亮点
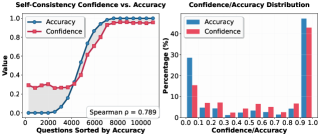
实验结果显示,EliCal在仅使用1k正确性标注的情况下,达到了接近最佳的对齐效果,并在未见的MMLU任务上表现优于仅校准的基线,提供了显著的性能提升,展示了其在大规模应用中的潜力。
🎯 应用场景
该研究的潜在应用领域包括智能问答系统、对话代理和其他需要高可信度的自然语言处理任务。通过提高模型的诚实对齐能力,能够增强用户对AI系统的信任,推动其在实际应用中的广泛采用。
📄 摘要(原文)
Honesty alignment-the ability of large language models (LLMs) to recognize their knowledge boundaries and express calibrated confidence-is essential for trustworthy deployment. Existing methods either rely on training-free confidence estimation (e.g., token probabilities, self-consistency) or training-based calibration with correctness annotations. While effective, achieving universal honesty alignment with training-based calibration requires costly, large-scale labeling. To support annotation-efficient training, we introduce Elicitation-Then-Calibration (EliCal), a two-stage framework that first elicits internal confidence using inexpensive self-consistency supervision, then calibrates this confidence with a small set of correctness annotations. To support a large-scale study, we release HonestyBench, a benchmark covering ten free-form QA datasets with 560k training and 70k evaluation instances annotated with correctness and self-consistency signals. Experiments show that EliCal achieves near-optimal alignment with only 1k correctness annotations (0.18% of full supervision) and better alignment performance on unseen MMLU tasks than the calibration-only baseline, offering a scalable solution toward universal honesty alignment in LLMs.