Deep Self-Evolving Reasoning
作者: Zihan Liu, Shun Zheng, Xumeng Wen, Yang Wang, Jiang Bian, Mao Yang
分类: cs.CL
发布日期: 2025-10-20
💡 一句话要点
提出深度自进化推理(DSER),提升小规模开放权重模型在复杂推理任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度自进化推理 长链式思维 开放权重模型 复杂推理 马尔可夫链
📋 核心要点
- 现有验证-改进框架依赖于强大的验证和纠正能力,但在小规模开放权重模型中表现不佳。
- DSER将迭代推理视为马尔可夫链,通过并行运行多个自进化过程,放大改进的概率,逼近正确答案。
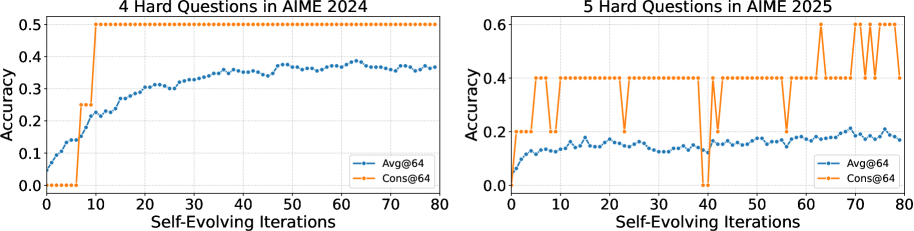
- DSER使DeepSeek-R1-0528-Qwen3-8B模型在AIME 2024-2025基准测试中解决了更多问题,超越了其600B参数教师模型的单轮准确率。
📝 摘要(中文)
长链式思维推理已成为大型语言模型高级推理的基石。虽然最近的验证-改进框架使专有模型能够解决奥林匹克级别的问题,但其有效性取决于强大、可靠的验证和纠正能力,而这些能力在开放权重、小规模模型中仍然脆弱。本文证明,即使在困难任务上验证和改进能力较弱,通过一种称为深度自进化推理(DSER)的概率范式,此类模型的推理限制也可以得到显著扩展。我们将迭代推理概念化为一个马尔可夫链,其中每个步骤代表解空间中的随机转换。关键的见解是,只要改进的概率略高于退化的概率,就能保证收敛到正确的解。通过并行运行多个长时程、自进化的过程,DSER放大了这些小的积极趋势,使模型能够渐近地接近正确的答案。在实验中,我们将DSER应用于DeepSeek-R1-0528-Qwen3-8B模型。在具有挑战性的AIME 2024-2025基准测试中,DSER解决了9个先前无法解决的问题中的5个,并提高了整体性能,使这个紧凑的模型通过多数投票超过了其600B参数教师模型的单轮准确率。除了其在测试时扩展的直接效用外,DSER框架还有助于诊断当前开放权重推理器的根本局限性。通过清楚地描绘它们在自我验证、改进和稳定性方面的缺点,我们的发现为开发具有强大内在自进化能力的下一代模型建立了一个明确的研究议程。
🔬 方法详解
问题定义:论文旨在解决小规模开放权重语言模型在复杂推理任务中表现不佳的问题。现有验证-改进框架依赖于模型自身强大的验证和纠正能力,而这些能力在小规模模型中往往不足,导致推理过程容易出错且难以纠正。因此,如何提升小规模模型在复杂推理任务中的性能,使其能够解决更具挑战性的问题,是本文要解决的核心问题。
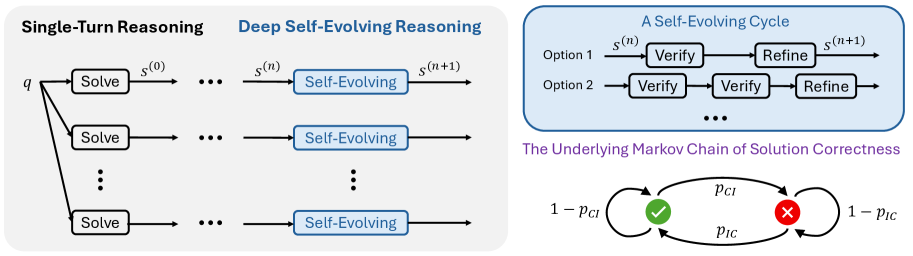
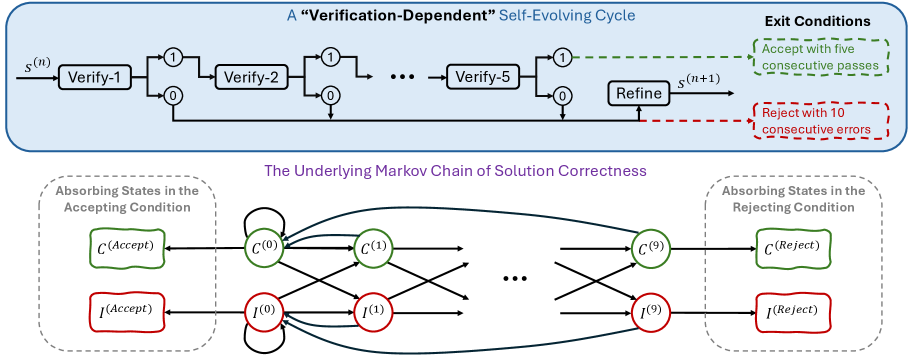
核心思路:论文的核心思路是将迭代推理过程建模为一个马尔可夫链,其中每一步推理都是解空间中的一次随机转移。关键在于,只要模型在推理过程中改进的概率略大于退化的概率,通过多次迭代,模型就能逐渐逼近正确的答案。DSER通过并行运行多个独立的、长时程的自进化推理过程,来放大这种微小的改进概率,从而提高模型最终得到正确答案的可能性。
技术框架:DSER框架主要包含以下几个阶段:1) 问题输入:将待解决的推理问题输入到语言模型中。2) 并行推理:同时启动多个独立的推理过程,每个过程都基于相同的输入问题,但由于模型的随机性,每个过程的推理路径可能不同。3) 自验证与改进:在每个推理步骤中,模型尝试验证当前推理结果的正确性,并根据验证结果进行改进。由于小规模模型的验证能力有限,这一步的改进可能并不总是有效。4) 多数投票:在所有推理过程完成后,对所有推理结果进行多数投票,选择出现次数最多的答案作为最终答案。
关键创新:DSER的关键创新在于其概率性的推理视角和并行自进化机制。与传统的确定性推理方法不同,DSER允许模型在推理过程中存在一定的错误,并通过多次迭代和多数投票来纠正这些错误。这种方法能够有效地利用小规模模型的计算资源,使其在复杂推理任务中获得更好的性能。
关键设计:DSER的关键设计包括:1) 推理过程的长度:推理过程的长度决定了模型能够探索解空间的范围。2) 并行推理过程的数量:并行推理过程的数量决定了模型能够利用的计算资源。3) 自验证与改进的策略:自验证与改进的策略决定了模型在每个推理步骤中能够纠正错误的程度。论文中具体使用的参数设置和策略未知。
🖼️ 关键图片
📊 实验亮点
DSER在AIME 2024-2025基准测试中,解决了9个先前无法解决的问题中的5个,显著提升了模型在该基准测试上的整体性能。更重要的是,DSER使DeepSeek-R1-0528-Qwen3-8B模型通过多数投票,超越了其600B参数教师模型的单轮准确率,证明了DSER在提升小规模模型推理能力方面的有效性。
🎯 应用场景
DSER框架可应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。该研究的实际价值在于,它提供了一种有效的方法来提升小规模开放权重模型在复杂推理任务中的性能,降低了对模型规模和计算资源的需求。未来,DSER有望成为一种通用的推理增强技术,应用于更广泛的领域。
📄 摘要(原文)
Long-form chain-of-thought reasoning has become a cornerstone of advanced reasoning in large language models. While recent verification-refinement frameworks have enabled proprietary models to solve Olympiad-level problems, their effectiveness hinges on strong, reliable verification and correction capabilities, which remain fragile in open-weight, smaller-scale models. This work demonstrates that even with weak verification and refinement capabilities on hard tasks, the reasoning limits of such models can be substantially extended through a probabilistic paradigm we call Deep Self-Evolving Reasoning (DSER). We conceptualize iterative reasoning as a Markov chain, where each step represents a stochastic transition in the solution space. The key insight is that convergence to a correct solution is guaranteed as long as the probability of improvement marginally exceeds that of degradation. By running multiple long-horizon, self-evolving processes in parallel, DSER amplifies these small positive tendencies, enabling the model to asymptotically approach correct answers. Empirically, we apply DSER to the DeepSeek-R1-0528-Qwen3-8B model. On the challenging AIME 2024-2025 benchmark, DSER solves 5 out of 9 previously unsolvable problems and boosts overall performance, enabling this compact model to surpass the single-turn accuracy of its 600B-parameter teacher through majority voting. Beyond its immediate utility for test-time scaling, the DSER framework serves to diagnose the fundamental limitations of current open-weight reasoners. By clearly delineating their shortcomings in self-verification, refinement, and stability, our findings establish a clear research agenda for developing next-generation models with powerful, intrinsic self-evolving capabilities.