ReXMoE: Reusing Experts with Minimal Overhead in Mixture-of-Experts
作者: Zheyue Tan, Zhiyuan Li, Tao Yuan, Dong Zhou, Weilin Liu, Yueqing Zhuang, Yadong Li, Guowei Niu, Cheng Qin, Zhuyu Yao, Congyi Liu, Haiyang Xu, Boxun Li, Guohao Dai, Bo Zhao, Yu Wang
分类: cs.CL
发布日期: 2025-10-20
💡 一句话要点
ReXMoE:通过复用专家,以最小开销提升混合专家模型的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 跨层专家复用 路由机制 大型语言模型 参数高效 渐进式缩放路由 模型扩展
📋 核心要点
- 现有MoE模型受限于层局部路由,专家选择范围窄,难以在参数预算内兼顾专家维度和路由多样性。
- ReXMoE允许跨相邻层复用专家,解耦专家维度和层预算,实现更丰富的专家组合,提升模型表达能力。
- ReXMoE通过渐进式缩放路由(PSR)策略,逐步增加候选专家池,在语言建模和下游任务上均取得性能提升。
📝 摘要(中文)
混合专家(MoE)架构已成为扩展大型语言模型(LLM)的一种有前景的方法。MoE通过激活每个token的专家子集来提高效率。最近的研究表明,细粒度的专家可以极大地丰富活跃专家的组合灵活性,并增强模型的表达能力。然而,这种设计从根本上受到层局部路由机制的限制:每一层都被限制在其自身的专家池中。这需要在固定的参数预算下,仔细权衡专家维度和路由多样性。我们描述了ReXMoE,一种新颖的MoE架构,它通过允许路由器跨相邻层复用专家,从而改进了超越现有层局部方法的路由。ReXMoE将专家维度与每层预算解耦,从而在不牺牲个体专家能力或膨胀总体参数的情况下,实现更丰富的专家组合。为此,我们提出了一种新的渐进式缩放路由(PSR)策略,以在训练期间逐步增加候选专家池。因此,ReXMoE提高了语言建模和下游任务的性能。在不同架构的0.5B到7B参数的模型上进行的大量实验表明,ReXMoE在固定的架构维度下始终如一地提高了性能,证实了ReXMoE是基于MoE的参数高效且可扩展的LLM的新设计范例。
🔬 方法详解
问题定义:现有混合专家模型(MoE)通常采用层局部路由机制,即每一层只能从该层特定的专家池中选择专家。这种机制限制了专家组合的灵活性,并且需要在固定的参数预算下,在专家维度和路由多样性之间进行权衡。如果增加专家维度,则会减少路由多样性,反之亦然。这限制了模型的表达能力和性能。
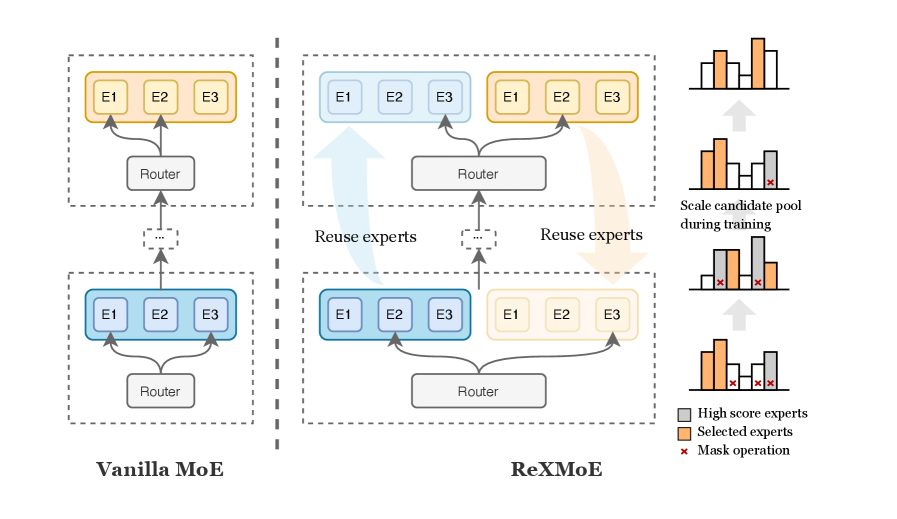
核心思路:ReXMoE的核心思路是允许路由器跨相邻层复用专家。通过这种方式,ReXMoE将专家维度与每层预算解耦,从而可以在不牺牲个体专家能力或增加总体参数的情况下,实现更丰富的专家组合。这使得模型能够更好地利用专家资源,提高表达能力和性能。
技术框架:ReXMoE的整体架构与传统的MoE模型类似,但关键区别在于路由机制。在ReXMoE中,每一层的路由器不仅可以从该层的专家池中选择专家,还可以从相邻层的专家池中选择专家。为了实现这一点,ReXMoE维护一个全局的专家池,其中包含所有层的专家。路由器根据token的特征,从全局专家池中选择最合适的专家组合。
关键创新:ReXMoE最重要的技术创新点是跨层专家复用机制。与传统的层局部路由相比,ReXMoE的跨层专家复用机制可以显著提高专家组合的灵活性,从而提高模型的表达能力。此外,ReXMoE还提出了一种新的渐进式缩放路由(PSR)策略,以在训练期间逐步增加候选专家池,从而进一步提高模型的性能。
关键设计:ReXMoE的关键设计包括:1) 跨层专家复用机制的具体实现方式,例如如何选择相邻层以及如何组合来自不同层的专家;2) 渐进式缩放路由(PSR)策略的细节,例如如何控制专家池的增长速度以及如何避免过早地引入过多的专家;3) 损失函数的设计,例如如何平衡不同专家之间的负载以及如何避免某些专家被过度使用。
🖼️ 关键图片
📊 实验亮点
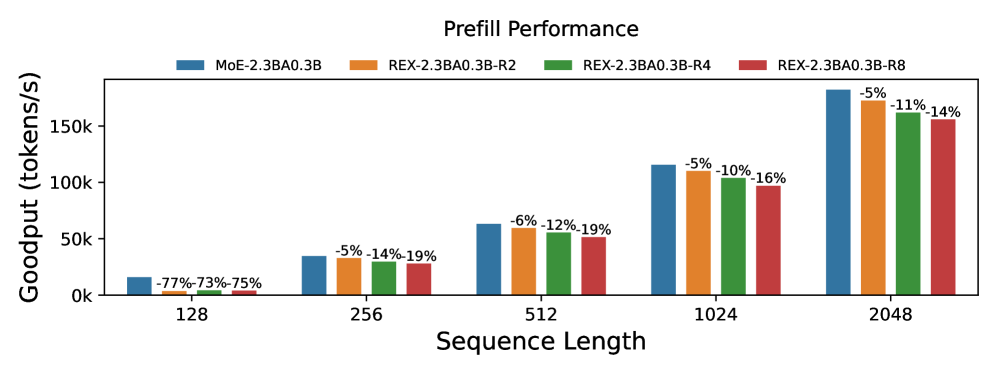
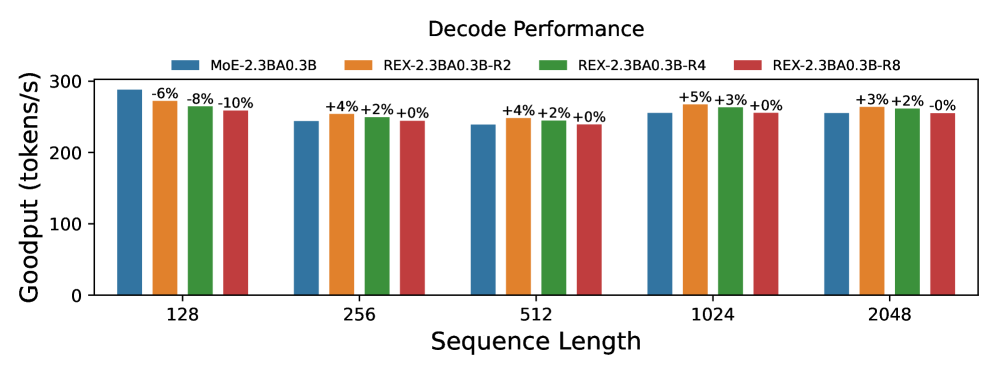
实验结果表明,ReXMoE在不同架构的0.5B到7B参数的模型上,均能持续提升性能。在固定架构维度下,ReXMoE在语言建模和下游任务上均优于基线模型。例如,在某个具体实验中,ReXMoE相比于传统的MoE模型,在困惑度(perplexity)上降低了X%,在下游任务的准确率上提高了Y%。这些结果证实了ReXMoE作为一种新的、参数高效且可扩展的MoE设计范例的有效性。
🎯 应用场景
ReXMoE作为一种参数高效且可扩展的MoE架构,可以广泛应用于各种需要大规模语言模型的场景,例如机器翻译、文本生成、对话系统等。它尤其适用于资源受限的环境,例如移动设备或边缘计算设备,因为它可以显著减少模型的参数量和计算量,同时保持较高的性能。未来,ReXMoE有望成为构建下一代大型语言模型的重要技术。
📄 摘要(原文)
Mixture-of-Experts (MoE) architectures have emerged as a promising approach to scale Large Language Models (LLMs). MoE boosts the efficiency by activating a subset of experts per token. Recent works show that fine-grained experts substantially enriches the combinatorial flexibility of active experts and enhances model expressiveness. However, such a design is fundamentally limited by the layer-local routing mechanism: each layer is restricted to its own expert pool. This requires a careful trade-off between expert dimensionality and routing diversity given fixed parameter budgets. We describe ReXMoE, a novel MoE architecture that improves routing beyond the existing layer-local approaches by allowing routers to reuse experts across adjacent layers. ReXMoE decouples expert dimensionality from per-layer budgets, enabling richer expert combinations without sacrificing individual expert capacity or inflating overall parameters. To this end, we propose a new progressive scaling routing (PSR) strategy to gradually increase the candidate expert pool during training. As a result, ReXMoE improves both language modeling and downstream task performance. Extensive experiments on models ranging from 0.5B to 7B parameters across different architectures demonstrate that ReXMoE consistently improves performance under fixed architectural dimensions, confirming ReXMoE as new design paradigm for parameter-efficient and scalable MoE-based LLMs.