Disparities in Multilingual LLM-Based Healthcare Q&A
作者: Ipek Baris Schlicht, Burcu Sayin, Zhixue Zhao, Frederik M. Labonté, Cesare Barbera, Marco Viviani, Paolo Rosso, Lucie Flek
分类: cs.CL
发布日期: 2025-10-20
备注: Under review
💡 一句话要点
揭示多语言LLM在医疗问答中存在的语言差异,并提出缓解策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 医疗问答 事实对齐 跨语言差异 检索增强生成
📋 核心要点
- 现有方法在多语言医疗问答中,LLM的可靠性和一致性存在问题,不同语言的信息质量差异显著。
- 论文核心在于分析LLM在不同语言医疗问答中的事实对齐差异,并利用RAG方法进行优化。
- 实验结果表明,LLM的响应更倾向于与英语维基百科对齐,而RAG能有效提升非英语语种的事实对齐。
📝 摘要(中文)
将人工智能整合到医疗保健中,公平地获取可靠的健康信息至关重要。然而,不同语言的信息质量各不相同,这引发了人们对多语言大型语言模型(LLM)的可靠性和一致性的担忧。本文系统地研究了英语、德语、土耳其语、中文(普通话)和意大利语的医疗问答中,LLM预训练来源和事实对齐方面的跨语言差异。我们(i)构建了来自维基百科的多语言数据集Multilingual Wiki Health Care(MultiWikiHealthCare);(ii)分析了跨语言的医疗保健覆盖率;(iii)评估了LLM响应与这些参考文献的对齐情况;(iv)通过使用上下文信息和检索增强生成(RAG)对事实对齐进行了案例研究。我们的研究结果表明,维基百科的覆盖范围和LLM的事实对齐都存在显著的跨语言差异。在所有LLM中,即使提示是非英语的,响应也更符合英语维基百科。在推理时提供来自非英语维基百科的上下文摘录,可以有效地将事实对齐转移到与文化相关的知识。这些结果突出了为医疗保健构建更公平、多语言人工智能系统的实际途径。
🔬 方法详解
问题定义:论文旨在解决多语言大型语言模型(LLM)在医疗问答应用中,由于预训练数据和知识来源的偏差,导致不同语言之间信息质量和事实一致性存在显著差异的问题。现有方法未能充分考虑和解决这种跨语言差异,可能导致非英语用户获取的医疗信息不准确或不完整,从而加剧医疗信息获取的不公平性。
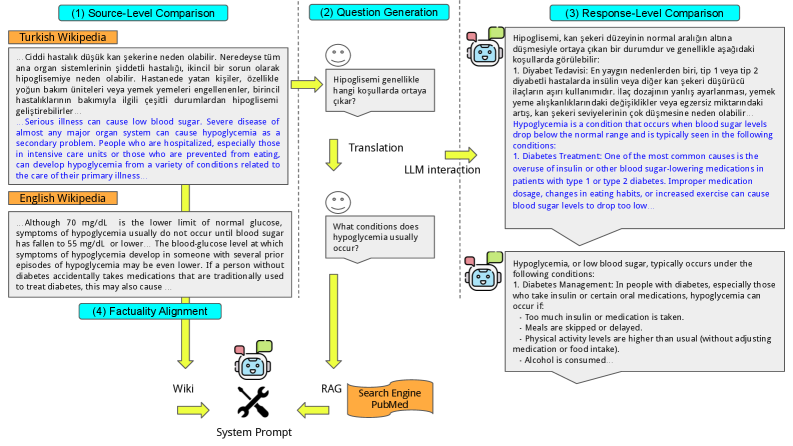
核心思路:论文的核心思路是通过系统性的跨语言分析,揭示LLM在不同语言医疗问答中的事实对齐差异,并利用检索增强生成(RAG)方法,在推理阶段引入与目标语言相关的上下文信息,从而引导LLM生成更符合当地文化和知识背景的答案。这种方法旨在弥合LLM在不同语言之间的知识差距,提高其在多语言医疗问答中的可靠性和公平性。
技术框架:整体框架包括以下几个主要阶段:1) 构建多语言医疗数据集MultiWikiHealthCare,该数据集来源于维基百科,包含英语、德语、土耳其语、中文和意大利语等多种语言的医疗信息;2) 分析不同语言维基百科的医疗信息覆盖率,评估不同语言之间的知识差距;3) 使用LLM对医疗问题进行回答,并评估其答案与维基百科参考资料的事实对齐程度;4) 通过RAG方法,在推理阶段向LLM提供来自非英语维基百科的上下文摘录,观察其对LLM答案事实对齐的影响。
关键创新:论文的关键创新在于:1) 系统性地揭示了多语言LLM在医疗问答中存在的跨语言事实对齐差异,并量化了这种差异的程度;2) 提出了利用RAG方法,在推理阶段引入与目标语言相关的上下文信息,从而改善LLM在非英语语种中的事实对齐效果;3) 构建了多语言医疗数据集MultiWikiHealthCare,为后续研究提供了数据基础。
关键设计:在RAG方法中,关键设计包括:1) 如何从维基百科中检索与问题相关的上下文信息;2) 如何将检索到的上下文信息有效地融入到LLM的输入中;3) 如何评估LLM生成答案的事实对齐程度。论文可能采用了诸如余弦相似度等方法来衡量问题与维基百科文章之间的相关性,并使用诸如BLEU或ROUGE等指标来评估生成答案与参考答案之间的相似度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM的响应更倾向于与英语维基百科对齐,即使问题是用非英语提出的。通过RAG方法,提供非英语维基百科的上下文信息,可以有效提升LLM在非英语语种中的事实对齐程度,使其答案更符合当地文化和知识背景。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于构建更公平、可靠的多语言医疗问答系统,帮助不同语言背景的用户获取准确、及时的医疗信息。通过优化LLM在不同语言中的事实对齐,可以减少医疗信息获取的语言障碍,提升医疗服务的可及性和公平性。未来,该研究思路可以推广到其他领域,例如法律、教育等,构建更普惠的多语言AI系统。
📄 摘要(原文)
Equitable access to reliable health information is vital when integrating AI into healthcare. Yet, information quality varies across languages, raising concerns about the reliability and consistency of multilingual Large Language Models (LLMs). We systematically examine cross-lingual disparities in pre-training source and factuality alignment in LLM answers for multilingual healthcare Q&A across English, German, Turkish, Chinese (Mandarin), and Italian. We (i) constructed Multilingual Wiki Health Care (MultiWikiHealthCare), a multilingual dataset from Wikipedia; (ii) analyzed cross-lingual healthcare coverage; (iii) assessed LLM response alignment with these references; and (iv) conducted a case study on factual alignment through the use of contextual information and Retrieval-Augmented Generation (RAG). Our findings reveal substantial cross-lingual disparities in both Wikipedia coverage and LLM factual alignment. Across LLMs, responses align more with English Wikipedia, even when the prompts are non-English. Providing contextual excerpts from non-English Wikipedia at inference time effectively shifts factual alignment toward culturally relevant knowledge. These results highlight practical pathways for building more equitable, multilingual AI systems for healthcare.