Explainability of Large Language Models: Opportunities and Challenges toward Generating Trustworthy Explanations
作者: Shahin Atakishiyev, Housam K. B. Babiker, Jiayi Dai, Nawshad Farruque, Teruaki Hayashi, Nafisa Sadaf Hriti, Md Abed Rahman, Iain Smith, Mi-Young Kim, Osmar R. Zaïane, Randy Goebel
分类: cs.CL
发布日期: 2025-10-20
💡 一句话要点
综述Transformer大语言模型可解释性,探讨医疗和自动驾驶领域应用及挑战。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 Transformer 医疗保健 自动驾驶 信任 机制可解释性 局部可解释性
📋 核心要点
- 现有大语言模型在预测和推理中存在幻觉问题,其内部工作机制对人类而言通常是不可理解的,这降低了人们对模型的信任。
- 本文旨在通过研究Transformer大语言模型的局部可解释性和机制可解释性,来提升模型的可信度,并促进对模型行为的理解。
- 论文回顾了相关可解释性方法,并在医疗和自动驾驶领域进行了实验研究,分析了解释对信任的影响,并探讨了未来发展方向。
📝 摘要(中文)
大型语言模型(LLM)在自然语言处理的各种下游任务中表现出令人印象深刻的性能。然而,人类通常无法理解语言模型如何预测下一个token并生成内容。此外,这些模型经常在预测和推理中出错,即产生幻觉。这些错误突显了迫切需要更好地理解和解释语言模型复杂的内部工作原理以及它们如何生成预测输出。为了弥补这一差距,本文研究了基于Transformer的大型语言模型中的局部可解释性和机制可解释性,以提高对此类模型的信任。为此,本文旨在做出三个关键贡献。首先,我们回顾了文献中相关的局部可解释性和机制可解释性方法和见解。其次,我们描述了在医疗保健和自动驾驶这两个关键领域中,使用大型语言模型进行可解释性和推理的实验研究,并分析了解释对解释接收者的信任影响。最后,我们总结了LLM可解释性发展过程中当前尚未解决的问题,并概述了生成与人类对齐的、值得信赖的LLM解释的机会、关键挑战和未来方向。
🔬 方法详解
问题定义:当前大型语言模型虽然在各种NLP任务中表现出色,但其内部运作机制复杂,人类难以理解模型做出特定预测的原因。模型还存在“幻觉”问题,即生成不真实或不合理的输出,这严重影响了用户对模型的信任。现有方法缺乏对模型决策过程的透明解释,难以调试和改进模型。
核心思路:本文的核心思路是研究Transformer架构大语言模型的局部可解释性和机制可解释性。通过分析模型内部的激活、注意力机制等,试图揭示模型如何利用知识进行推理和预测。目标是提供人类可理解的解释,从而增强用户对模型的信任,并为模型改进提供指导。
技术框架:本文主要采用综述和实验研究相结合的方式。首先,对现有的局部可解释性和机制可解释性方法进行回顾和总结。然后,在医疗保健和自动驾驶两个关键领域,设计实验来评估大语言模型的可解释性和推理能力。最后,分析实验结果,探讨解释对用户信任的影响,并展望未来研究方向。
关键创新:本文的创新之处在于结合了综述和实验研究,系统地探讨了大语言模型的可解释性问题。特别关注了医疗保健和自动驾驶这两个高风险领域,分析了可解释性对用户信任的影响。此外,论文还指出了当前LLM可解释性研究中存在的未解决问题,并提出了未来的研究方向。
关键设计:论文侧重于对现有可解释性方法的分析和应用,并没有提出新的模型或算法。实验设计主要围绕医疗和自动驾驶领域的具体任务展开,例如,利用LLM进行医疗诊断或自动驾驶决策,并分析模型给出的解释是否合理可信。具体的技术细节(如参数设置、损失函数等)取决于所使用的具体LLM和可解释性方法,论文中未详细说明。
🖼️ 关键图片
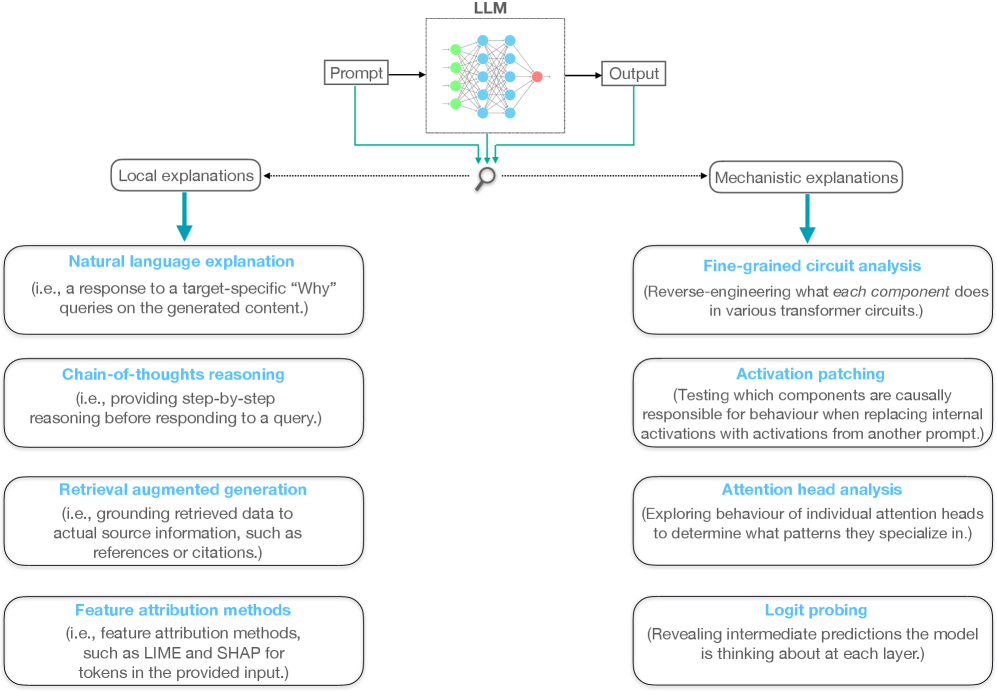

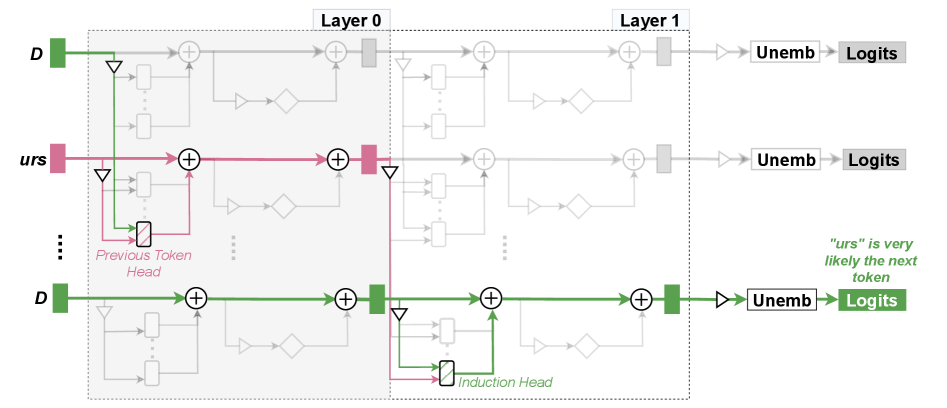
📊 实验亮点
论文通过在医疗和自动驾驶领域的实验,分析了LLM生成解释的可信度以及对用户信任的影响。研究结果表明,清晰、合理的解释能够显著提升用户对LLM的信任度,但同时也揭示了当前LLM在生成可信解释方面仍存在挑战,例如,模型可能会给出看似合理但实际上错误的解释。
🎯 应用场景
该研究成果可应用于提升大型语言模型在医疗、自动驾驶等高风险领域的可靠性和可信度。通过提供可解释的决策过程,有助于医生和工程师更好地理解和信任AI系统,从而促进AI技术在这些领域的应用和推广。同时,也有助于发现和纠正模型中的偏差和错误,提高模型的公平性和安全性。
📄 摘要(原文)
Large language models have exhibited impressive performance across a broad range of downstream tasks in natural language processing. However, how a language model predicts the next token and generates content is not generally understandable by humans. Furthermore, these models often make errors in prediction and reasoning, known as hallucinations. These errors underscore the urgent need to better understand and interpret the intricate inner workings of language models and how they generate predictive outputs. Motivated by this gap, this paper investigates local explainability and mechanistic interpretability within Transformer-based large language models to foster trust in such models. In this regard, our paper aims to make three key contributions. First, we present a review of local explainability and mechanistic interpretability approaches and insights from relevant studies in the literature. Furthermore, we describe experimental studies on explainability and reasoning with large language models in two critical domains -- healthcare and autonomous driving -- and analyze the trust implications of such explanations for explanation receivers. Finally, we summarize current unaddressed issues in the evolving landscape of LLM explainability and outline the opportunities, critical challenges, and future directions toward generating human-aligned, trustworthy LLM explanations.