StreamingThinker: Large Language Models Can Think While Reading
作者: Junlong Tong, Yingqi Fan, Anhao Zhao, Yunpu Ma, Xiaoyu Shen
分类: cs.CL
发布日期: 2025-10-20 (更新: 2025-12-09)
🔗 代码/项目: GITHUB
💡 一句话要点
提出StreamingThinker,使LLM在阅读时同步推理,降低延迟并提升动态场景性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 流式推理 思维链 低延迟 动态场景
📋 核心要点
- 现有LLM推理方法需等待完整输入,导致延迟高,且对动态场景早期信息关注不足。
- StreamingThinker模拟人类阅读时思考,实现LLM在接收输入的同时进行推理。
- 实验表明,StreamingThinker在保持性能的同时,显著降低了推理延迟和token等待时间。
📝 摘要(中文)
大型语言模型(LLMs)在思维链(CoT)推理方面表现出卓越的能力。然而,当前LLM的推理范式仅在获得完整输入后才开始思考,这导致不必要的延迟,并削弱了对动态场景中早期信息的关注。受人类阅读时思考的认知启发,我们首先为LLM设计了一种 extbf{流式思考}范式,其中推理按照输入的顺序展开,并在阅读完成后进一步调整其深度。我们用 extit{StreamingThinker}实例化了这种范式,该框架通过集成流式CoT生成、流式约束训练和流式并行推理,使LLM能够在阅读时进行思考。具体来说,StreamingThinker采用具有质量控制的流式推理单元进行CoT生成,通过流式注意力掩码和位置编码来强制执行保序推理,并利用解耦输入编码和推理生成的并行KV缓存,从而确保对齐并实现真正的并发。我们在Qwen3模型系列上,针对数学推理、逻辑推理和基于上下文的QA推理任务评估了StreamingThinker。实验结果表明,StreamingThinker保持了与批量思考相当的性能,同时在推理开始前的token等待时间减少了80%,并且在生成最终答案的时间延迟上减少了60%以上,证明了流式范式对于LLM推理的有效性。
🔬 方法详解
问题定义:论文旨在解决现有大型语言模型(LLM)在推理过程中存在的延迟问题,尤其是在动态场景下,现有方法需要等待整个输入序列完成后才能开始推理,这导致了不必要的延迟,并且削弱了模型对早期信息的关注。现有方法的痛点在于无法实现实时推理,影响了用户体验和模型的应用范围。
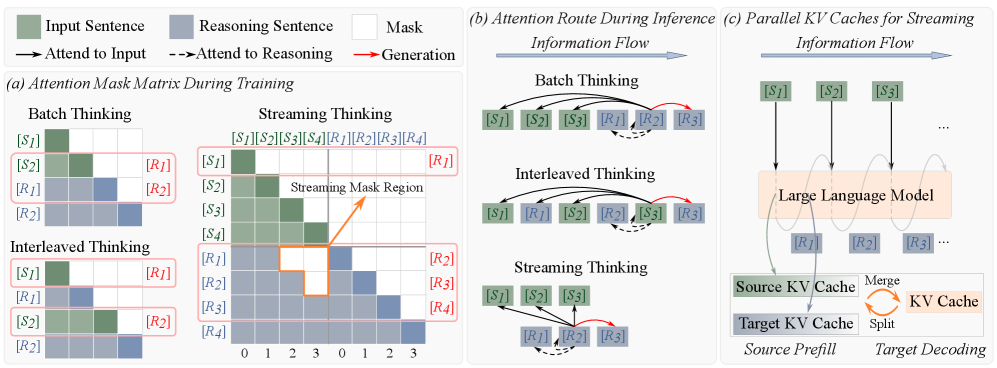
核心思路:论文的核心思路是模仿人类“阅读时思考”的认知过程,提出一种“流式思考”范式。该范式允许LLM在接收输入的同时进行推理,而不是等待整个输入完成后才开始。通过这种方式,可以显著降低推理延迟,并使模型能够更好地适应动态变化的环境。
技术框架:StreamingThinker框架主要包含三个核心模块:流式CoT生成、流式约束训练和流式并行推理。流式CoT生成负责在接收输入的同时生成思维链;流式约束训练通过流式注意力掩码和位置编码来保证推理的顺序性;流式并行推理则利用并行KV缓存来解耦输入编码和推理生成,从而实现真正的并发。整体流程是,模型接收到输入token后,立即进行推理,并逐步完善思维链,最终生成答案。
关键创新:最重要的技术创新点在于提出了“流式思考”的范式,并将其成功应用于LLM推理。与传统的“批量思考”范式相比,“流式思考”范式能够显著降低推理延迟,并提高模型在动态场景下的适应性。此外,流式约束训练和流式并行推理也是关键创新,它们保证了流式推理的正确性和效率。
关键设计:在流式CoT生成中,采用了具有质量控制的流式推理单元,以保证生成的思维链的质量。流式约束训练中,使用了流式注意力掩码和位置编码,以强制执行保序推理。流式并行推理中,采用了并行KV缓存,以解耦输入编码和推理生成。这些设计细节共同保证了StreamingThinker的性能和效率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,StreamingThinker在Qwen3模型系列上,针对数学推理、逻辑推理和基于上下文的QA推理任务,保持了与批量思考相当的性能,同时在推理开始前的token等待时间减少了80%,并且在生成最终答案的时间延迟上减少了60%以上。这些数据充分证明了StreamingThinker的有效性。
🎯 应用场景
StreamingThinker具有广泛的应用前景,例如实时对话系统、在线问答、金融风险评估等需要快速响应的场景。该研究可以提升LLM在动态环境下的应用能力,并为未来的LLM推理范式提供新的思路。未来,该技术有望应用于机器人控制、自动驾驶等领域,实现更智能、更高效的人机交互。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable capabilities in chain of thought (CoT) reasoning. However, the current LLM reasoning paradigm initiates thinking only after the entire input is available, which introduces unnecessary latency and weakens attention to earlier information in dynamic scenarios. Inspired by human cognition of thinking while reading, we first design a \textit{\textbf{streaming thinking}} paradigm for LLMs, where reasoning unfolds in the order of input and further adjusts its depth once reading is complete. We instantiate this paradigm with \textit{StreamingThinker}, a framework that enables LLMs to think while reading through the integration of streaming CoT generation, streaming-constraint training, and streaming parallel inference. Specifically, StreamingThinker employs streaming reasoning units with quality control for CoT generation, enforces order-preserving reasoning through streaming attention masks and position encoding, and leverages parallel KV caches that decouple input encoding from reasoning generation, thereby ensuring alignment and enabling true concurrency. We evaluate StreamingThinker on the Qwen3 model family across math reasoning, logical reasoning, and context-based QA reasoning tasks. Experimental results show that the StreamingThinker preserves performance comparable to batch thinking, while yielding an 80\% reduction in token waiting before the onset of reasoning and a more than 60\% reduction in time-level latency for producing the final answer, demonstrating the effectiveness of the streaming paradigm for LLM reasoning. Code will be released at https://github.com/EIT-NLP/StreamingLLM/tree/main/StreamingThinker.