Rethinking On-policy Optimization for Query Augmentation
作者: Zhichao Xu, Shengyao Zhuang, Xueguang Ma, Bingsen Chen, Yijun Tian, Fengran Mo, Jie Cao, Vivek Srikumar
分类: cs.CL, cs.IR
发布日期: 2025-10-20
💡 一句话要点
提出On-policy伪文档查询扩展(OPQE),融合提示学习与强化学习优化信息检索中的查询增强。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 查询增强 信息检索 大型语言模型 强化学习 伪文档 提示学习 On-policy优化
📋 核心要点
- 现有查询增强方法,如基于提示和基于强化学习的方法,缺乏系统性的比较研究,难以确定最佳实践。
- 论文提出On-policy伪文档查询扩展(OPQE),结合提示学习的灵活性和强化学习的优化能力,生成伪文档以提升检索性能。
- 实验表明,OPQE方法优于单独的提示学习和基于强化学习的查询重写方法,验证了协同方法的有效性。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展引发了信息检索(IR)领域对查询增强的极大兴趣。目前主要有两种方法:一是通过提示LLMs生成答案或伪文档作为新查询,完全依赖模型的参数知识或上下文信息;二是应用强化学习(RL)微调LLMs进行查询重写,直接优化检索指标。尽管各有优缺点,但两种方法尚未在一致的实验条件下进行比较。本文首次对基于提示和基于RL的查询增强进行了系统比较,涵盖证据搜索、Ad Hoc检索和工具检索等多种基准。关键发现是,简单的、无需训练的查询增强通常与更昂贵的基于RL的方法性能相当,甚至超越,尤其是在使用强大的LLMs时。受此启发,我们提出了一种新的混合方法,即On-policy伪文档查询扩展(OPQE),该方法不是重写查询,而是让LLM策略学习生成最大化检索性能的伪文档,从而将提示的灵活性和生成结构与RL的定向优化相结合。实验表明,OPQE优于独立的提示和基于RL的重写,证明了一种协同方法可以产生最佳结果。我们公开了代码实现,以方便复现。
🔬 方法详解
问题定义:论文旨在解决信息检索中查询增强的问题。现有方法,如单纯基于提示的查询生成和基于强化学习的查询重写,各有优缺点,且缺乏直接的对比分析。基于提示的方法依赖于LLM的知识,可能不够精确;基于强化学习的方法需要大量的训练,成本较高。
核心思路:论文的核心思路是将提示学习和强化学习相结合,利用LLM生成伪文档,并通过强化学习优化伪文档的生成过程,使其更符合检索需求。这种方法旨在融合提示学习的灵活性和强化学习的优化能力,从而获得更好的检索性能。
技术框架:OPQE方法的核心框架是强化学习。LLM作为策略网络,输入原始查询,输出伪文档。检索系统使用原始查询和生成的伪文档进行检索,检索结果作为奖励信号反馈给LLM,用于更新策略网络。整个过程是一个标准的强化学习循环。
关键创新:OPQE的关键创新在于它不是直接重写查询,而是生成伪文档。这种方法允许LLM更自由地表达信息,避免了查询重写可能带来的信息损失。同时,通过强化学习优化伪文档的生成,使其更贴合检索需求,从而提高检索性能。
关键设计:OPQE的关键设计包括:1) 使用LLM作为策略网络,生成伪文档;2) 使用检索系统的检索结果作为奖励信号,例如NDCG或MAP;3) 使用On-policy的强化学习算法,如PPO或A2C,更新LLM的策略网络。具体的参数设置和网络结构取决于所使用的LLM和强化学习算法。
🖼️ 关键图片
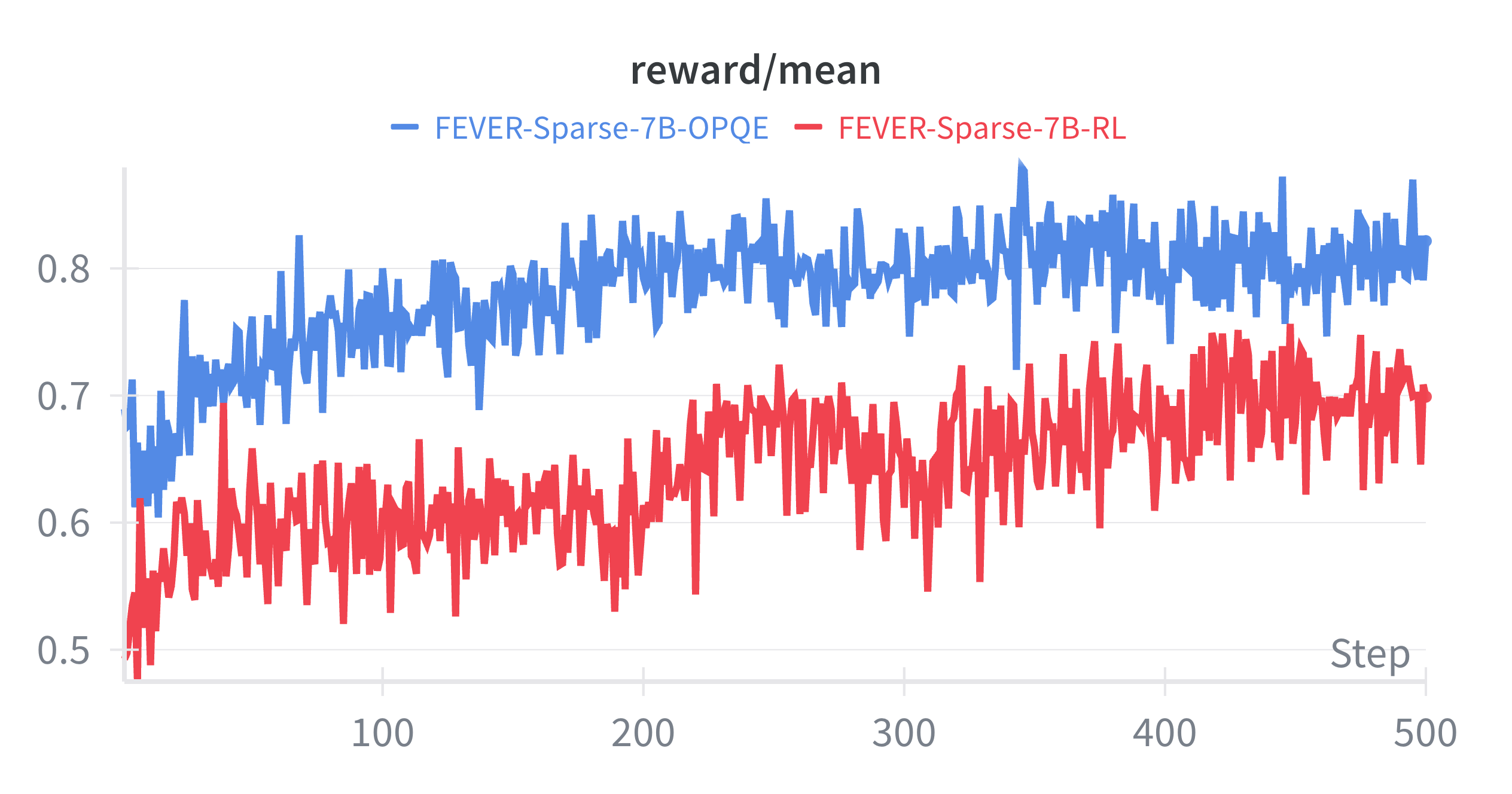
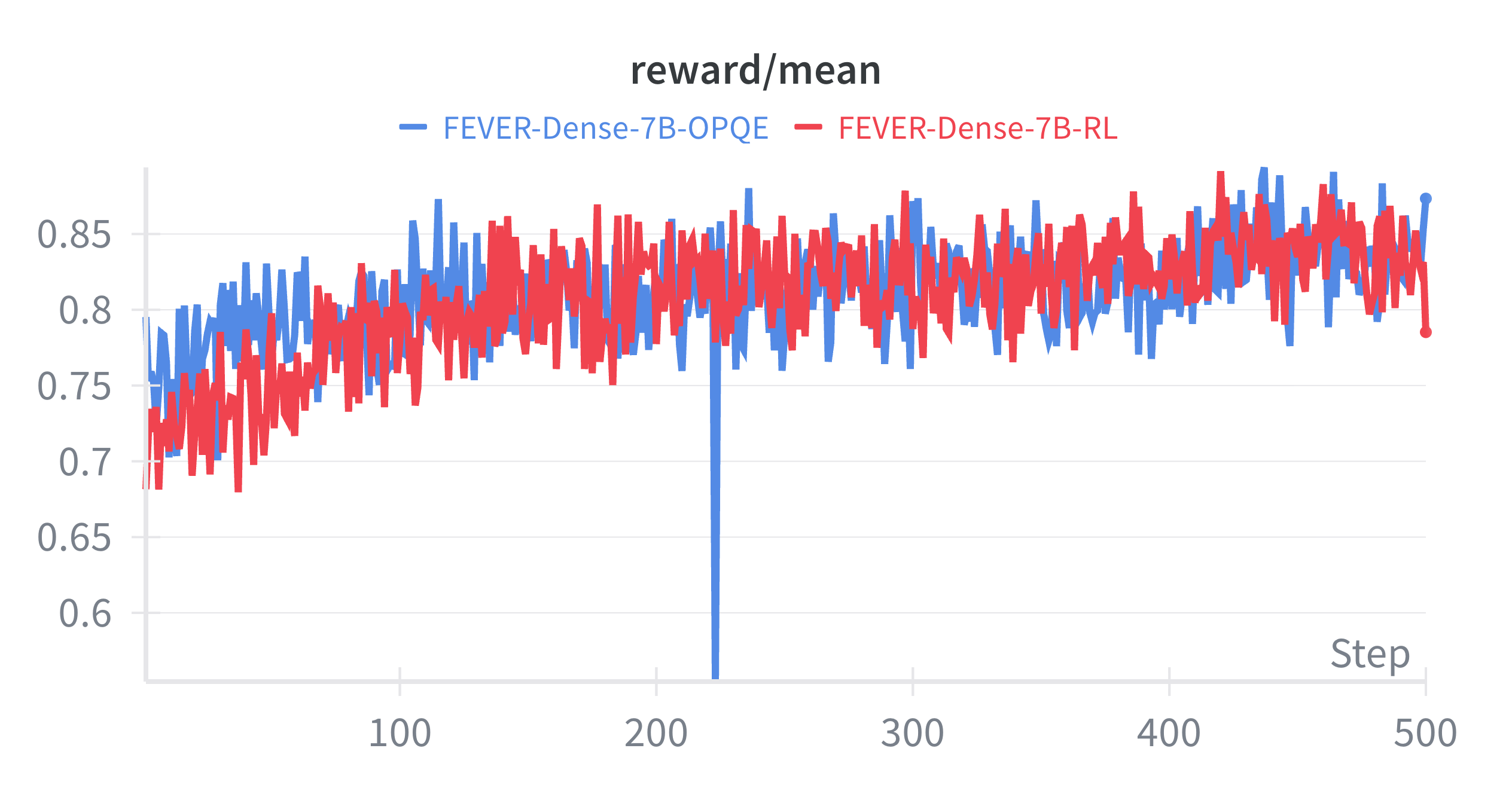
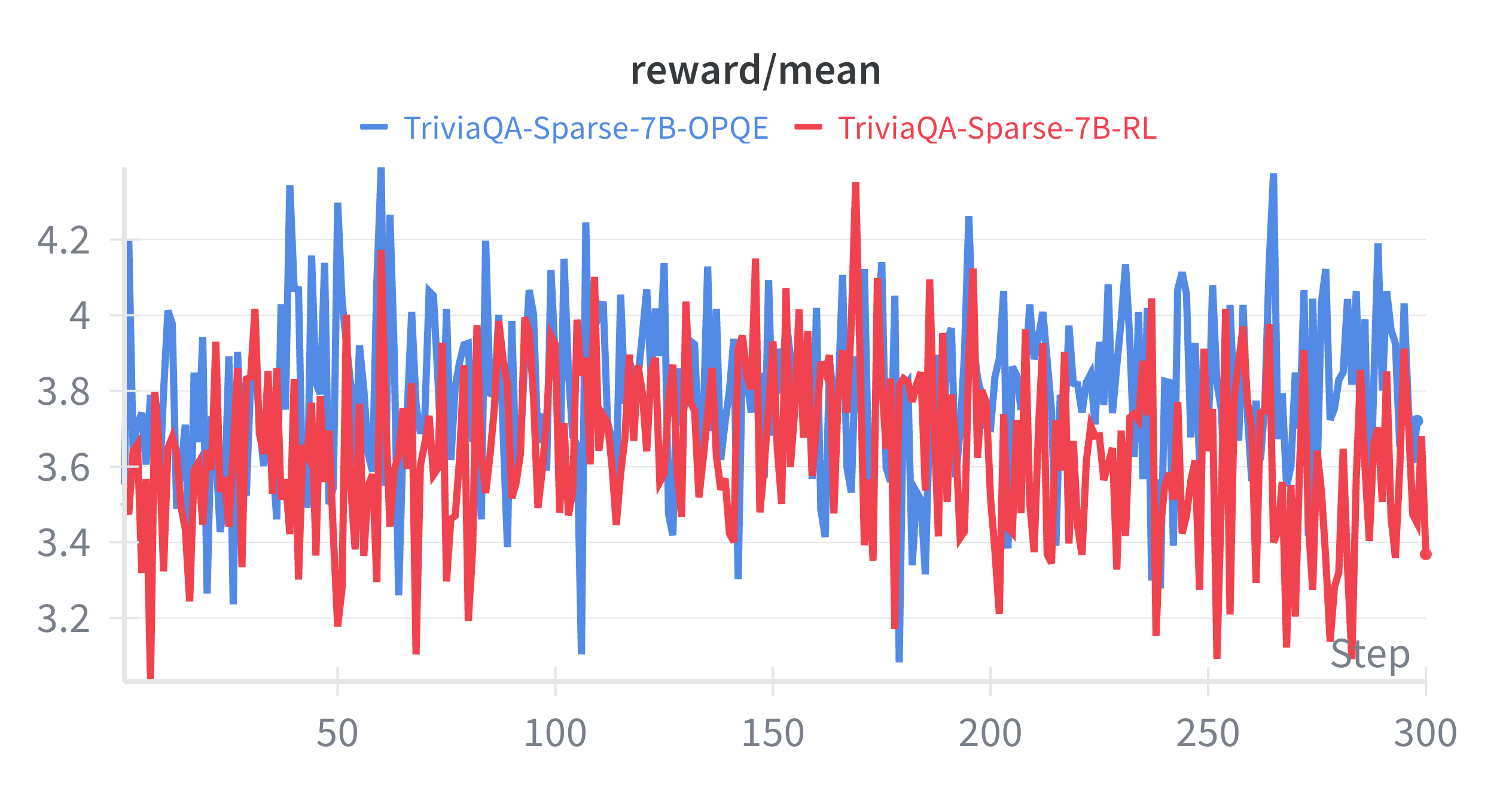
📊 实验亮点
实验结果表明,简单的、无需训练的查询增强方法通常与更昂贵的基于RL的方法性能相当,甚至超越,尤其是在使用强大的LLMs时。OPQE方法在多个基准测试中优于单独的提示学习和基于强化学习的查询重写方法,证明了协同方法的有效性。具体的性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种信息检索场景,例如搜索引擎、问答系统、推荐系统等。通过增强查询,可以提高检索的准确性和召回率,从而改善用户体验。此外,该方法还可以应用于工具检索,帮助用户更有效地找到所需的工具或资源。
📄 摘要(原文)
Recent advances in large language models (LLMs) have led to a surge of interest in query augmentation for information retrieval (IR). Two main approaches have emerged. The first prompts LLMs to generate answers or pseudo-documents that serve as new queries, relying purely on the model's parametric knowledge or contextual information. The second applies reinforcement learning (RL) to fine-tune LLMs for query rewriting, directly optimizing retrieval metrics. While having respective advantages and limitations, the two approaches have not been compared under consistent experimental conditions. In this work, we present the first systematic comparison of prompting-based and RL-based query augmentation across diverse benchmarks, including evidence-seeking, ad hoc, and tool retrieval. Our key finding is that simple, training-free query augmentation often performs on par with, or even surpasses, more expensive RL-based counterparts, especially when using powerful LLMs. Motivated by this discovery, we introduce a novel hybrid method, On-policy Pseudo-document Query Expansion (OPQE), which, instead of rewriting a query, the LLM policy learns to generate a pseudo-document that maximizes retrieval performance, thus merging the flexibility and generative structure of prompting with the targeted optimization of RL. We show OPQE outperforms both standalone prompting and RL-based rewriting, demonstrating that a synergistic approach yields the best results. Our implementation is made available to facilitate reproducibility.