Atomic Literary Styling: Mechanistic Manipulation of Prose Generation in Neural Language Models
作者: Tsogt-Ochir Enkhbayar
分类: cs.CL
发布日期: 2025-10-19
备注: 12 pages, 3 figures, 4 tables
💡 一句话要点
原子文学风格化:神经语言模型中散文生成的机制性操控
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 神经语言模型 文学风格 机制可解释性 消融研究 GPT-2
📋 核心要点
- 现有神经语言模型生成的文本缺乏文学性,难以区分高质量散文和AI生成文本。
- 通过识别并操控GPT-2中与文学风格相关的特定神经元,实现对散文生成的机制性控制。
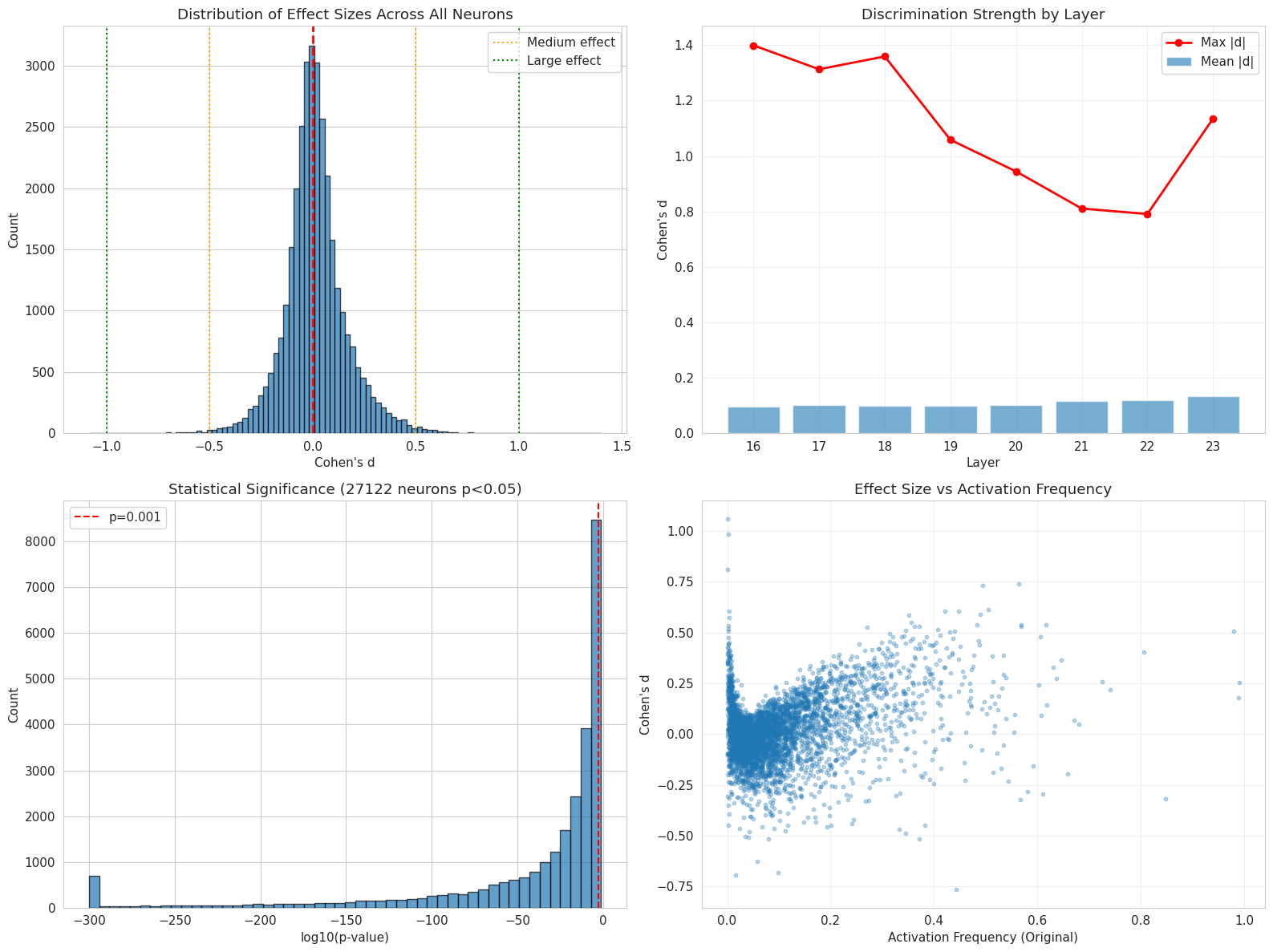
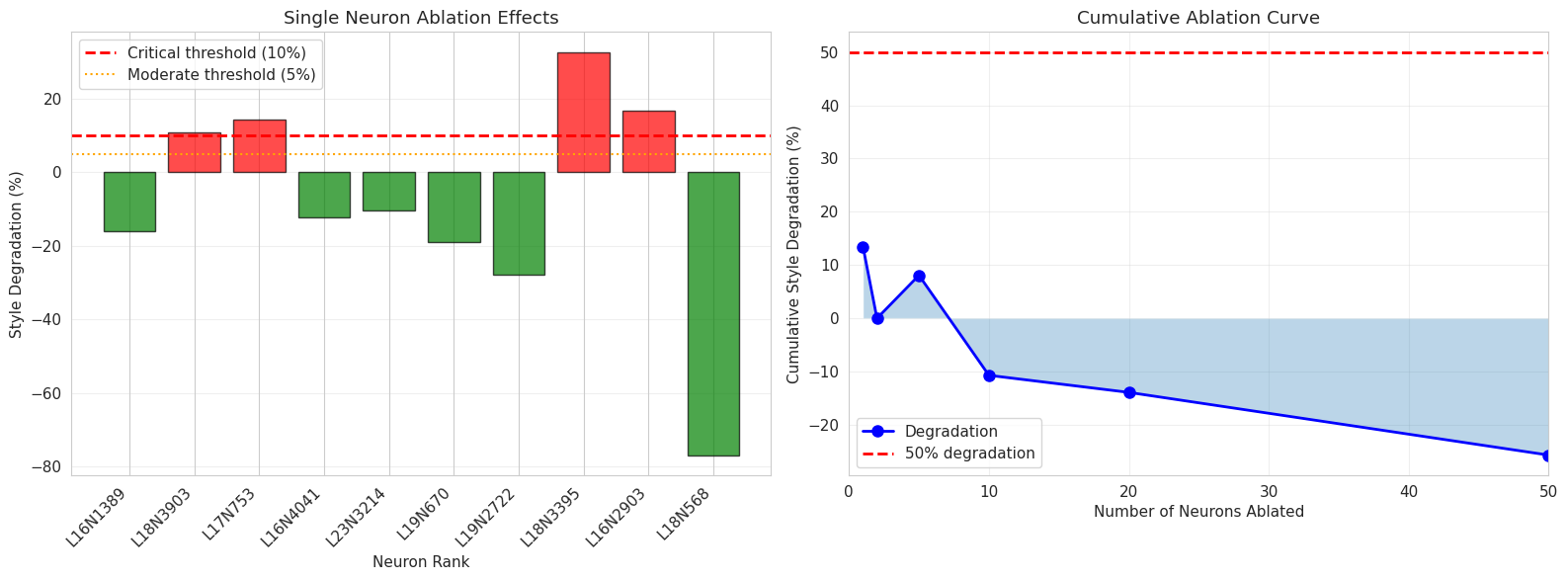
- 消融实验表明,移除与文学文本相关的神经元反而能提升生成文本的文学风格指标,提升幅度达25.7%。
📝 摘要(中文)
本文对GPT-2中的文学风格进行了机制性分析,识别出能够区分典范散文和僵化AI生成文本的单个神经元。以赫尔曼·梅尔维尔的《抄写员巴特比》为语料库,我们从后期层的3.55亿参数和32768个神经元中提取激活模式。我们发现27122个具有统计学意义的判别神经元($p < 0.05$),效应量高达$|d| = 1.4$。通过系统的消融研究,我们发现了一个悖论式的结果:虽然这些神经元在分析过程中与文学文本相关,但移除它们通常会提高而非降低生成的散文质量。具体而言,消融50个高判别神经元可使文学风格指标提高25.7%。这表明了神经网络中观察相关性和因果必然性之间存在关键差距。我们的发现挑战了这样一种假设,即在理想输入上激活的神经元将在生成过程中产生这些输出,这对机制可解释性研究和AI对齐具有重要意义。
🔬 方法详解
问题定义:论文旨在解决神经语言模型生成文本缺乏文学风格的问题。现有方法难以区分高质量文学作品和AI生成的僵化文本,缺乏对模型内部机制的理解,无法有效提升生成文本的文学性。
核心思路:论文的核心思路是通过识别并操控神经语言模型中与文学风格相关的特定神经元,从而实现对生成文本风格的精细控制。作者假设,模型中存在一些神经元,它们的激活模式与特定文学风格密切相关,通过干预这些神经元的活动,可以改变生成文本的风格。
技术框架:论文的技术框架主要包括以下几个阶段:1) 使用文学作品(《抄写员巴特比》)和AI生成文本作为语料库;2) 从GPT-2模型的后期层提取神经元的激活模式;3) 统计分析识别出能够区分文学作品和AI生成文本的判别神经元;4) 通过消融实验,移除这些判别神经元,并评估生成文本的文学风格变化。
关键创新:论文最重要的创新点在于发现并验证了“观察相关性”和“因果必然性”在神经语言模型中的差异。具体来说,论文发现,虽然某些神经元的激活与文学文本相关,但移除这些神经元反而能提升生成文本的文学风格。这挑战了传统的“激活即产生”的假设,为理解神经语言模型的内部机制提供了新的视角。
关键设计:论文的关键设计包括:1) 使用效应量(Cohen's d)来衡量神经元的判别能力;2) 使用消融实验来评估神经元对生成文本风格的影响;3) 使用文学风格指标(具体指标未知)来量化生成文本的文学性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过消融50个高判别神经元,可以使生成文本的文学风格指标提高25.7%。这一结果挑战了传统认知,表明观察到的神经元激活与最终生成结果之间并非简单的因果关系,为神经语言模型的机制性理解提供了新的证据。
🎯 应用场景
该研究成果可应用于提升神经语言模型生成文本的质量和风格控制,例如,可以用于生成更具文学性的创意文本、更符合特定作者风格的文本等。此外,该研究也为理解和操控大型语言模型的内部机制提供了新的思路,对AI对齐和可解释性研究具有重要意义。
📄 摘要(原文)
We present a mechanistic analysis of literary style in GPT-2, identifying individual neurons that discriminate between exemplary prose and rigid AI-generated text. Using Herman Melville's Bartleby, the Scrivener as a corpus, we extract activation patterns from 355 million parameters across 32,768 neurons in late layers. We find 27,122 statistically significant discriminative neurons ($p < 0.05$), with effect sizes up to $|d| = 1.4$. Through systematic ablation studies, we discover a paradoxical result: while these neurons correlate with literary text during analysis, removing them often improves rather than degrades generated prose quality. Specifically, ablating 50 high-discriminating neurons yields a 25.7% improvement in literary style metrics. This demonstrates a critical gap between observational correlation and causal necessity in neural networks. Our findings challenge the assumption that neurons which activate on desirable inputs will produce those outputs during generation, with implications for mechanistic interpretability research and AI alignment.