Mapping from Meaning: Addressing the Miscalibration of Prompt-Sensitive Language Models
作者: Kyle Cox, Jiawei Xu, Yikun Han, Rong Xu, Tianhao Li, Chi-Yang Hsu, Tianlong Chen, Walter Gerych, Ying Ding
分类: cs.CL, cs.LG
发布日期: 2025-10-19
期刊: Proceedings of the AAAI Conference on Artificial Intelligence. 39, 22 (Apr. 2025), 23696-23703
DOI: 10.1609/aaai.v39i22.34540
💡 一句话要点
提出基于语义概念空间采样的Prompt校准方法,提升语言模型不确定性估计。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Prompt工程 不确定性校准 泛化误差 语义概念空间
📋 核心要点
- 现有大语言模型对prompt敏感,相同语义的prompt可能导致差异巨大的输出分布,无法准确反映模型真实的不确定性。
- 论文提出在语义“概念空间”中进行采样,通过释义扰动提高不确定性校准,核心思想是提升模型对prompt含义的泛化能力。
- 实验表明,该方法在不影响准确性的前提下,有效提升了不确定性校准,并能定量分析prompt敏感性对模型不确定性的影响。
📝 摘要(中文)
大型语言模型(LLMs)的一个有趣现象是prompt敏感性。对于语义等价的prompt,模型可能产生截然不同的答案分布。这表明模型输出分布所反映的不确定性,可能无法真实反映模型对prompt含义的不确定性。本文将prompt敏感性建模为一种泛化误差,并证明通过释义扰动在语义“概念空间”中采样,可以提高不确定性校准,同时不影响准确性。此外,本文还提出了一种新的黑盒LLM不确定性分解指标,该指标通过对自然语言生成中的语义连续性进行建模,改进了基于熵的分解方法。结果表明,该分解指标可用于量化LLM不确定性中有多少归因于prompt敏感性。这项工作为提高prompt敏感语言模型的不确定性校准提供了一种新方法,并提供了证据表明,某些LLM未能对输入的含义表现出一致的通用推理能力。
🔬 方法详解
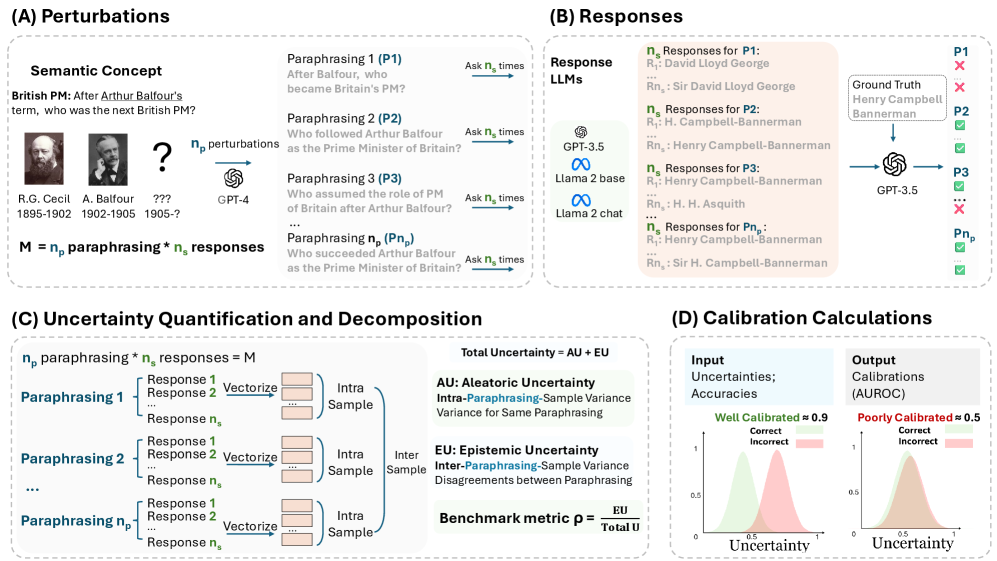
问题定义:论文旨在解决大型语言模型中存在的prompt敏感性问题。具体而言,即使输入语义相同的prompt,模型也可能给出差异很大的预测分布,这表明模型对自身预测的不确定性估计存在偏差(miscalibration)。现有方法难以有效解决这一问题,因为它们没有充分考虑prompt的语义变化对模型输出的影响。
核心思路:论文的核心思路是将prompt敏感性视为一种泛化误差,并认为模型需要在语义“概念空间”中进行泛化。通过在语义空间中进行采样,即使用不同的释义prompt,可以迫使模型学习到更加鲁棒的语义表示,从而提高不确定性校准。
技术框架:论文的技术框架主要包含两个部分:一是基于释义扰动的prompt采样方法,二是不确定性分解指标。首先,通过对原始prompt进行释义生成多个语义等价的prompt。然后,使用这些prompt输入到LLM中,得到多个预测分布。最后,使用提出的不确定性分解指标,分析模型的不确定性来源,并评估prompt敏感性对不确定性的影响。
关键创新:论文的关键创新在于:(1) 将prompt敏感性建模为一种泛化误差,并提出在语义空间中进行采样来解决该问题。(2) 提出了一种新的不确定性分解指标,该指标考虑了自然语言生成中的语义连续性,能够更准确地量化prompt敏感性对模型不确定性的影响。与传统的基于熵的分解方法相比,该指标更加关注语义层面的信息。
关键设计:在prompt采样方面,论文使用了释义生成模型来生成语义等价的prompt。具体实现细节未知,但关键在于保证生成prompt的语义与原始prompt尽可能一致,同时在表达方式上有所差异。在不确定性分解指标方面,具体公式和计算方法未知,但其核心思想是分解模型的不确定性为多个部分,其中一部分与prompt敏感性相关。
🖼️ 关键图片

📊 实验亮点
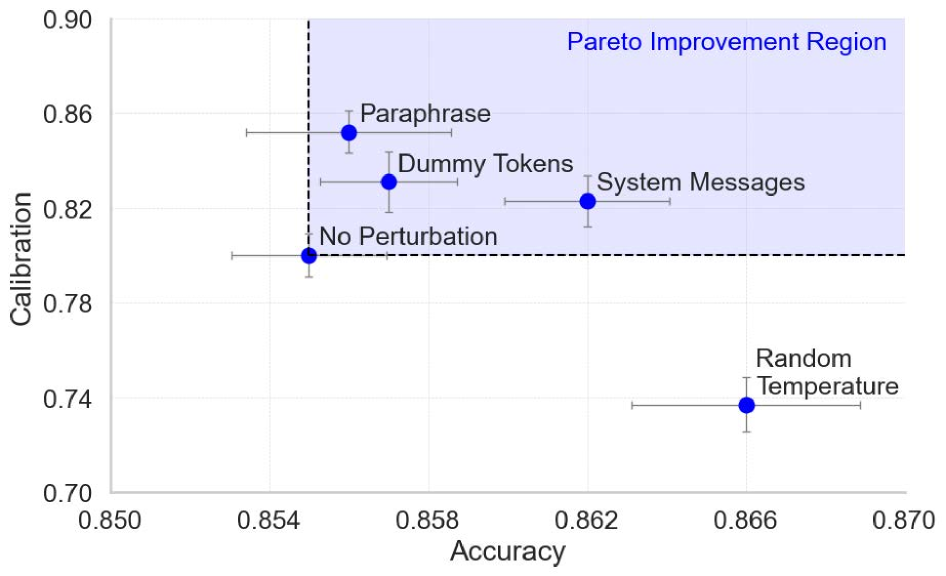
论文通过实验验证了所提出的prompt采样方法可以有效提高不确定性校准,同时不影响模型的准确性。此外,实验结果表明,提出的不确定性分解指标能够准确量化prompt敏感性对模型不确定性的影响,并揭示了不同LLM在prompt敏感性方面的差异。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于对模型可靠性要求较高的自然语言处理任务,例如医疗诊断、金融风控等。通过提高模型的不确定性校准,可以帮助用户更好地理解模型的预测结果,并做出更明智的决策。此外,该研究还可以促进对大型语言模型prompt敏感性的深入理解,为开发更加鲁棒和可靠的语言模型提供指导。
📄 摘要(原文)
An interesting behavior in large language models (LLMs) is prompt sensitivity. When provided with different but semantically equivalent versions of the same prompt, models may produce very different distributions of answers. This suggests that the uncertainty reflected in a model's output distribution for one prompt may not reflect the model's uncertainty about the meaning of the prompt. We model prompt sensitivity as a type of generalization error, and show that sampling across the semantic ``concept space'' with paraphrasing perturbations improves uncertainty calibration without compromising accuracy. Additionally, we introduce a new metric for uncertainty decomposition in black-box LLMs that improves upon entropy-based decomposition by modeling semantic continuities in natural language generation. We show that this decomposition metric can be used to quantify how much LLM uncertainty is attributed to prompt sensitivity. Our work introduces a new way to improve uncertainty calibration in prompt-sensitive language models, and provides evidence that some LLMs fail to exhibit consistent general reasoning about the meanings of their inputs.