Online Learning Defense against Iterative Jailbreak Attacks via Prompt Optimization
作者: Masahiro Kaneko, Zeerak Talat, Timothy Baldwin
分类: cs.CL
发布日期: 2025-10-19
💡 一句话要点
提出基于在线学习的防御框架,对抗迭代式越狱攻击
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 在线学习 强化学习 提示优化
📋 核心要点
- 现有防御方法无法有效应对迭代式越狱攻击中动态变化的提示。
- 利用强化学习在线优化提示,区分并拒绝有害提示,同时保证无害任务的响应质量。
- 实验表明,该方法显著优于现有防御方法,并提升了对无害任务的响应质量。
📝 摘要(中文)
本文提出了一种新颖的框架,通过在线学习动态更新防御策略,以应对迭代式越狱攻击。迭代式越狱方法通过重复重写提示并将其输入到大型语言模型(LLM)中,利用模型先前的响应来指导每次新的迭代,从而诱导有害输出,已被证明是一种非常有效的攻击策略。与现有防御方法不同,本文提出的方法主动中断这种动态试错循环。该方法利用有害的越狱提示和典型的无害提示之间的区别,引入了一种基于强化学习的方法,该方法优化提示,以确保对无害任务的适当响应,同时明确拒绝有害提示。此外,为了抑制对攻击期间探索的窄带部分输入重写的过度拟合,引入了过去方向梯度阻尼(PDGD)。在三个LLM上进行的实验表明,该方法显著优于五种现有的防御方法,对抗五种迭代式越狱方法。此外,结果表明,提示优化策略同时提高了对无害任务的响应质量。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面对迭代式越狱攻击时,现有防御方法无法有效阻止攻击的问题。迭代式攻击通过不断试错和利用模型反馈来生成恶意提示,现有防御方法难以适应这种动态变化,容易被绕过。
核心思路:论文的核心思路是构建一个在线学习的防御框架,该框架能够根据每次新的提示动态调整防御策略。通过区分有害的越狱提示和无害的正常提示,利用强化学习优化提示,从而在保证正常任务性能的同时,有效阻止恶意攻击。
技术框架:整体框架包含以下几个主要模块:1) 提示输入模块:接收来自用户的提示;2) 提示优化模块:利用强化学习算法,对提示进行微调,使其更接近无害提示的分布;3) LLM推理模块:将优化后的提示输入到LLM中,获取模型的响应;4) 奖励函数模块:根据模型的响应,计算奖励信号,用于指导强化学习算法的更新;5) 梯度阻尼模块:使用Past-Direction Gradient Damping (PDGD) 来防止过拟合。
关键创新:最重要的创新点在于将在线学习和强化学习应用于LLM的防御。与传统的静态防御方法不同,该方法能够根据攻击者的行为动态调整防御策略,从而更有效地对抗迭代式攻击。此外,PDGD的引入有效缓解了过拟合问题,提高了模型的泛化能力。
关键设计:奖励函数的设计至关重要,需要能够准确区分有害和无害的提示。论文中可能采用了基于安全规则、内容过滤或模型预测的奖励函数。PDGD的具体实现可能涉及对梯度方向的约束或正则化,以防止模型过度拟合到攻击样本的梯度方向上。强化学习算法的选择也可能影响最终的防御效果,常见的选择包括策略梯度方法或Q-learning方法。
🖼️ 关键图片

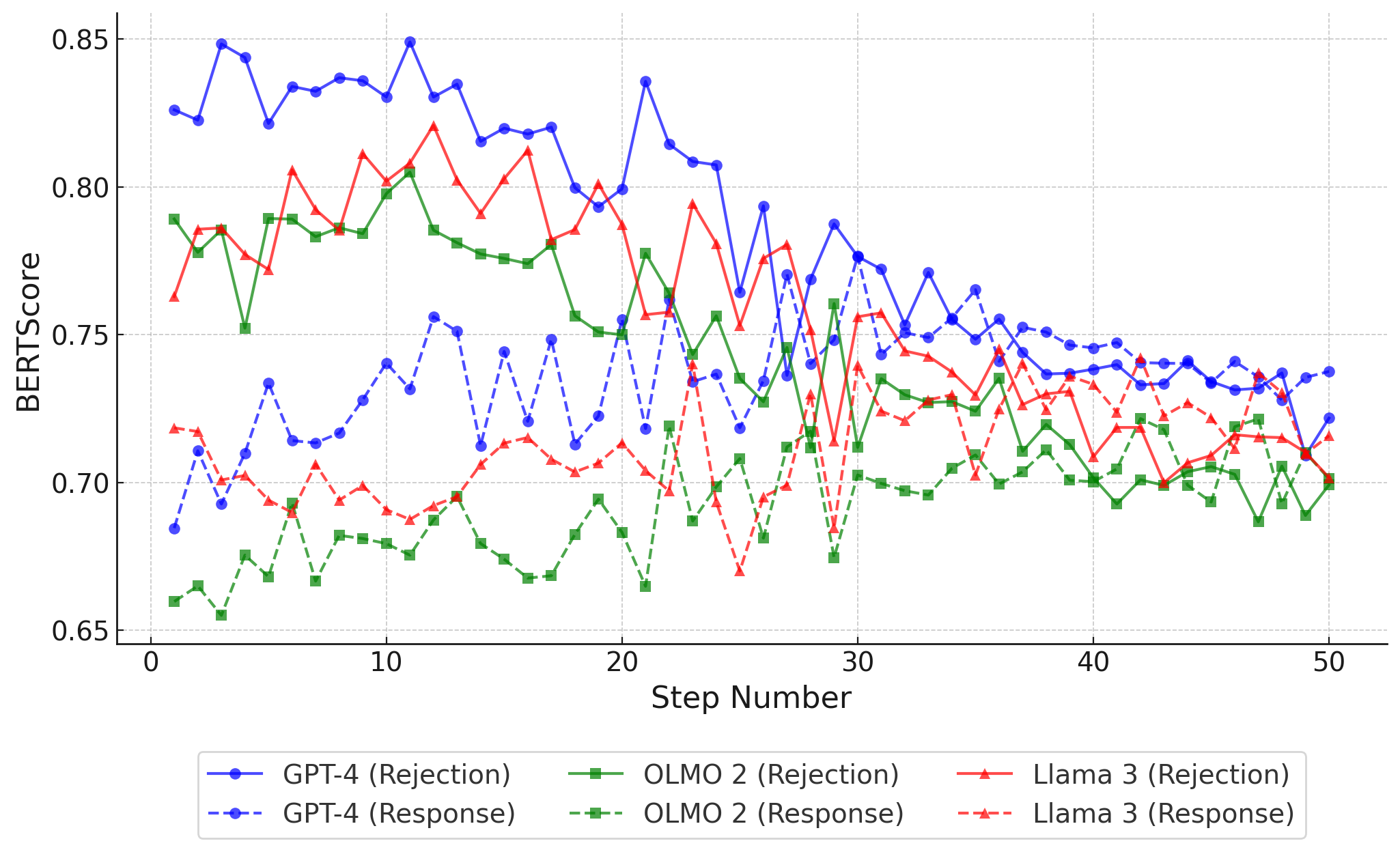

📊 实验亮点
实验结果表明,该方法在对抗五种迭代式越狱攻击时,显著优于五种现有的防御方法。具体而言,该方法在防御成功率上取得了显著提升,同时保证了对无害任务的响应质量。此外,PDGD的引入有效缓解了过拟合问题,提高了模型的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要安全保障的大型语言模型应用场景,例如智能客服、内容生成、代码助手等。通过在线学习防御框架,可以有效提升LLM的安全性,防止恶意用户利用迭代式攻击获取有害信息或执行恶意操作,从而保障用户体验和数据安全。未来,该方法可以进一步扩展到其他类型的攻击防御,例如对抗样本攻击、数据投毒攻击等。
📄 摘要(原文)
Iterative jailbreak methods that repeatedly rewrite and input prompts into large language models (LLMs) to induce harmful outputs -- using the model's previous responses to guide each new iteration -- have been found to be a highly effective attack strategy. Despite being an effective attack strategy against LLMs and their safety mechanisms, existing defenses do not proactively disrupt this dynamic trial-and-error cycle. In this study, we propose a novel framework that dynamically updates its defense strategy through online learning in response to each new prompt from iterative jailbreak methods. Leveraging the distinctions between harmful jailbreak-generated prompts and typical harmless prompts, we introduce a reinforcement learning-based approach that optimizes prompts to ensure appropriate responses for harmless tasks while explicitly rejecting harmful prompts. Additionally, to curb overfitting to the narrow band of partial input rewrites explored during an attack, we introduce Past-Direction Gradient Damping (PDGD). Experiments conducted on three LLMs show that our approach significantly outperforms five existing defense methods against five iterative jailbreak methods. Moreover, our results indicate that our prompt optimization strategy simultaneously enhances response quality for harmless tasks.