Vocab Diet: Reshaping the Vocabulary of LLMs with Vector Arithmetic
作者: Yuval Reif, Guy Kaplan, Roy Schwartz
分类: cs.CL
发布日期: 2025-10-19
💡 一句话要点
提出Vocab Diet,利用向量运算重塑LLM词汇表,提升词汇多样性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 词汇表压缩 词形变体 向量运算 自然语言处理
📋 核心要点
- 现有LLM的tokenization算法冗余地处理词形变体,导致词汇表效率低下,限制了对罕见词和多语言的支持。
- Vocab Diet通过将词形变体表示为基本形式和转换向量的组合,紧凑地重塑词汇表,释放空间。
- 实验表明,该方法能在不显著影响下游性能的前提下,减少词汇表大小并扩展词汇覆盖范围。
📝 摘要(中文)
大型语言模型(LLMs)已被证明能够将词形变体(例如,“walk”->“walked”)编码为嵌入空间中的线性方向。然而,标准的tokenization算法将这些变体视为不同的token,导致大小受限的词汇表被表面形式变体(例如,“walk”,“walking”,“Walk”)占据,牺牲了不太常见的单词和多语言覆盖。我们表明,许多这些变体可以通过转换向量来捕获——加性偏移量,当应用于基本形式词嵌入时,产生适当的词表示——无论是在输入空间还是输出空间。在此基础上,我们提出了一种紧凑的词汇表重塑方法:与其为每个表面形式分配唯一的token,不如将它们由共享的基本形式和转换向量组成(例如,“walked”=“walk”+过去时)。我们将我们的方法应用于多个LLM和五种语言,最多可以删除10%的词汇表条目——从而释放空间来分配新的、更多样化的token。重要的是,我们在扩展词汇表覆盖范围到词汇表外单词的同时,对下游性能的影响最小,并且不修改模型权重。我们的发现促使人们对词汇表设计进行基础性的重新思考,从字符串枚举转向利用语言底层结构的组合词汇表。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的词汇表通常包含大量词形变体(如“walk”、“walking”、“walked”),这些变体占据了有限的词汇空间,导致模型无法有效处理低频词汇和多语言场景。标准的tokenization方法将这些词形变体视为独立的token,没有充分利用它们之间的语义关系,造成了词汇冗余。
核心思路:论文的核心思路是将词形变体表示为基本形式和转换向量的组合。例如,“walked”可以表示为“walk”加上一个表示过去时的转换向量。通过这种方式,模型只需要存储基本形式的词嵌入和少量的转换向量,就可以生成各种词形变体,从而大大减少了词汇表的大小。这种方法利用了词形变体之间的线性关系,提高了词汇表的效率。
技术框架:该方法主要包含以下几个步骤:1) 确定基本形式:选择每个词形变体的基本形式(例如,动词的原型)。2) 计算转换向量:通过计算词形变体和其基本形式的词嵌入之间的差值,得到转换向量。3) 重塑词汇表:从原始词汇表中移除词形变体,只保留基本形式和转换向量。在模型推理时,可以通过将基本形式的词嵌入加上相应的转换向量来生成词形变体的表示。该方法不需要修改模型权重,可以直接应用于现有的LLM。
关键创新:该方法最重要的技术创新点在于将词形变体表示为基本形式和转换向量的组合,从而实现了词汇表的紧凑表示。与传统的tokenization方法相比,该方法能够更有效地利用词汇空间,提高模型对低频词汇和多语言场景的处理能力。此外,该方法不需要修改模型权重,可以直接应用于现有的LLM,具有很强的实用性。
关键设计:论文的关键设计包括:1) 转换向量的计算方法:使用词形变体和其基本形式的词嵌入之间的差值作为转换向量。2) 词汇表重塑策略:从原始词汇表中移除词形变体,只保留基本形式和转换向量。3) 模型推理时的词形变体生成方法:通过将基本形式的词嵌入加上相应的转换向量来生成词形变体的表示。论文没有涉及具体的损失函数或网络结构的设计,因为该方法主要关注词汇表的重塑,而不是模型结构的修改。
🖼️ 关键图片


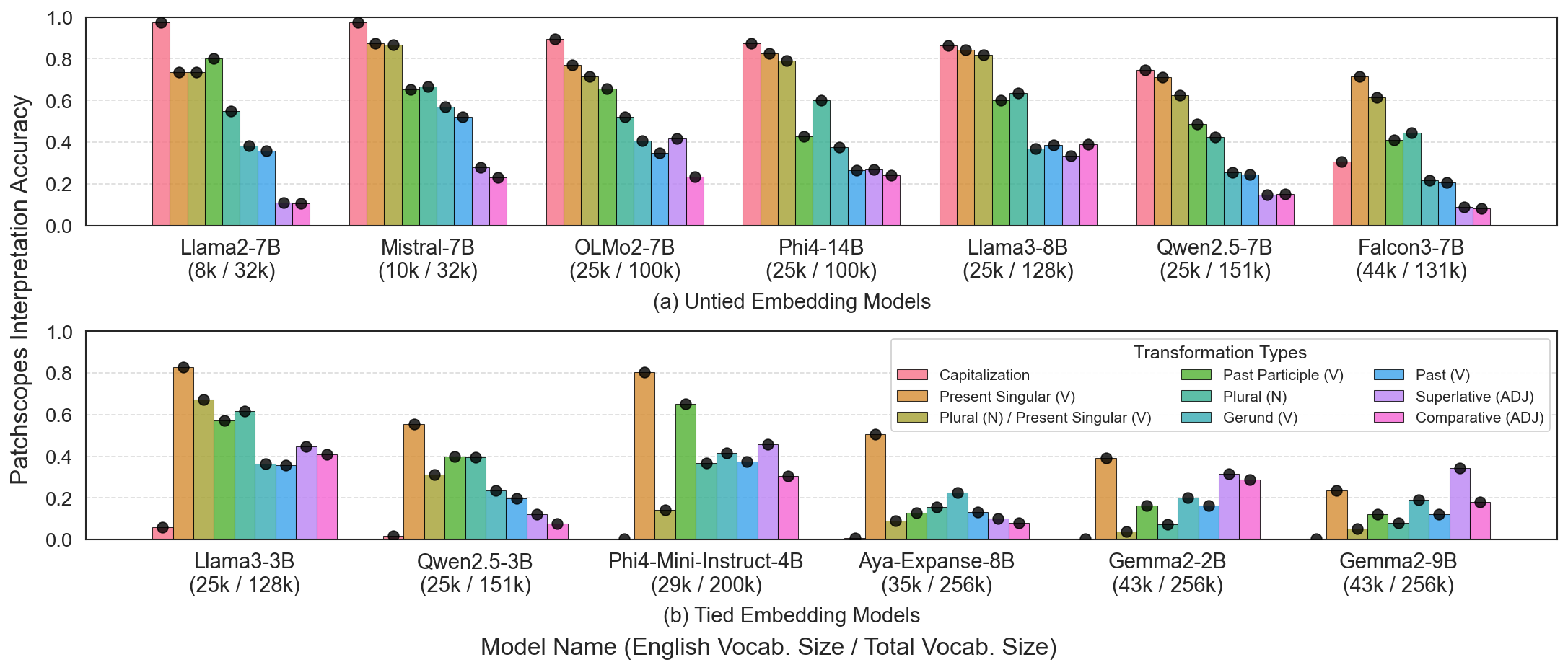
📊 实验亮点
实验结果表明,该方法能够在多个LLM和五种语言上有效地减少词汇表的大小,最多可删除10%的词汇表条目。同时,该方法对下游性能的影响最小,并且能够扩展词汇覆盖范围到词汇表外单词。这些结果表明,该方法是一种有效的词汇表重塑方法,具有很强的实用价值。
🎯 应用场景
该研究成果可广泛应用于各种自然语言处理任务中,尤其是在资源受限的环境下,例如移动设备或嵌入式系统。通过减少词汇表的大小,可以降低模型的存储和计算成本,提高模型的部署效率。此外,该方法还可以用于扩展模型的词汇覆盖范围,提高模型对低频词汇和多语言场景的处理能力。未来,该方法有望应用于机器翻译、文本生成、信息检索等领域。
📄 摘要(原文)
Large language models (LLMs) were shown to encode word form variations, such as "walk"->"walked", as linear directions in embedding space. However, standard tokenization algorithms treat these variations as distinct tokens -- filling the size-capped vocabulary with surface form variants (e.g., "walk", "walking", "Walk"), at the expense of less frequent words and multilingual coverage. We show that many of these variations can be captured by transformation vectors -- additive offsets that yield the appropriate word's representation when applied to the base form word embedding -- in both the input and output spaces. Building on this, we propose a compact reshaping of the vocabulary: rather than assigning unique tokens to each surface form, we compose them from shared base form and transformation vectors (e.g., "walked" = "walk" + past tense). We apply our approach to multiple LLMs and across five languages, removing up to 10% of vocabulary entries -- thereby freeing space to allocate new, more diverse tokens. Importantly, we do so while also expanding vocabulary coverage to out-of-vocabulary words, with minimal impact on downstream performance, and without modifying model weights. Our findings motivate a foundational rethinking of vocabulary design, moving from string enumeration to a compositional vocabulary that leverages the underlying structure of language.