Bits Leaked per Query: Information-Theoretic Bounds on Adversarial Attacks against LLMs
作者: Masahiro Kaneko, Timothy Baldwin
分类: cs.CR, cs.CL, cs.LG
发布日期: 2025-10-19
备注: NeurIPS 2025 (spotlight)
💡 一句话要点
提出信息论框架,量化LLM对抗攻击中的信息泄露,指导透明度与安全性的平衡。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗攻击 信息泄露 互信息 安全性 透明度 越狱攻击
📋 核心要点
- 现有LLM对抗攻击研究缺乏对信息泄露规模的量化分析,审计和防御缺乏理论指导。
- 论文提出基于互信息的信息论框架,将信息泄露量化为每次查询泄露的比特数,并推导出攻击所需的查询次数下界。
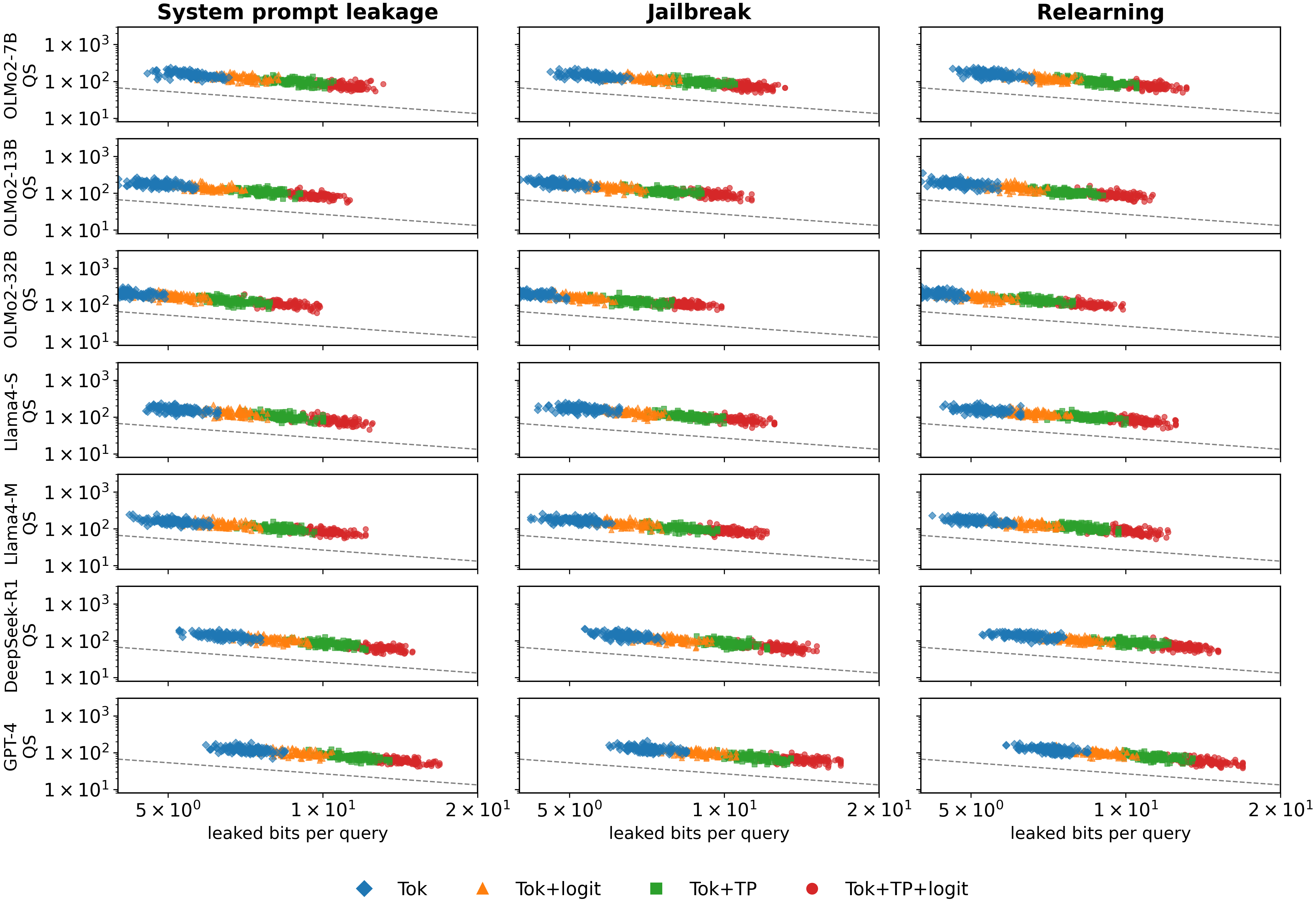
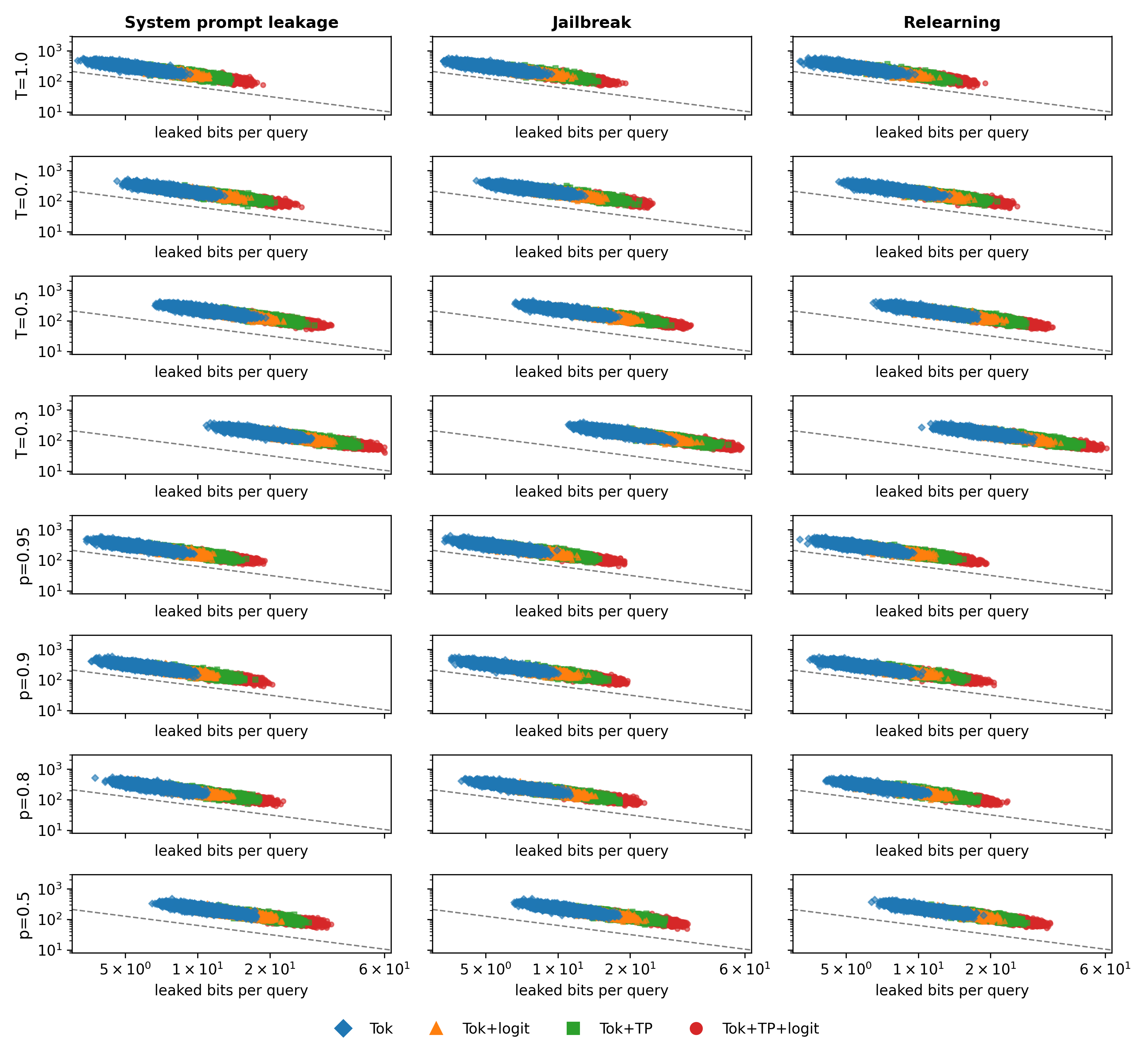
- 实验表明,不同类型的信息泄露(答案token、logits、思考过程)对攻击成本有显著影响,验证了理论框架的有效性。
📝 摘要(中文)
大型语言模型(LLM)的安全受到恶意用户的对抗攻击威胁,这些攻击试图推断目标属性$T$,该属性在指令发布时未知,仅在观察到模型的回复后才变得可知。目标属性$T$的例子包括触发LLM有害响应或拒绝的二元标志,以及通过对抗性指令恢复被遗忘的信息的程度。LLM通过包含答案token、思考过程token或logits的回复来揭示一个潜在泄露攻击提示的可观察信号$Z$。然而,信息泄露的规模仍然是零星的,审计人员缺乏原则性指导,防御者对透明度与风险的权衡视而不见。我们用一个信息论框架填补了这个空白,该框架计算了可以安全披露多少信息,并使审计人员能够衡量他们的方法与基本限制的接近程度。将观察$Z$和目标属性$T$之间的互信息$I(Z;T)$视为每次查询泄露的比特数,我们表明,实现误差$\varepsilon$至少需要$\log(1/\varepsilon)/I(Z;T)$次查询,其规模与泄漏率的倒数成线性关系,并且仅与所需的精度成对数关系。因此,即使披露量适度增加,也会使攻击成本从二次方降至对数级别(就所需精度而言)。在七个LLM上进行的系统提示泄露、越狱和重新学习攻击实验证实了该理论:仅暴露答案token需要大约一千次查询;添加logits将其减少到大约一百次;而揭示完整的思考过程则将其减少到几十次。我们的结果为部署LLM时平衡透明度和安全性提供了第一个原则性标准。
🔬 方法详解
问题定义:论文旨在解决LLM对抗攻击中信息泄露规模难以量化的问题。现有方法缺乏对透明度与安全性的权衡的原则性指导,导致审计人员难以评估攻击风险,防御者难以制定有效的防御策略。
核心思路:论文的核心思路是将对抗攻击视为一种信息推断过程,通过量化LLM回复中泄露的目标属性信息,来评估攻击的难易程度。核心在于使用互信息$I(Z;T)$来衡量观察到的信号$Z$(例如,LLM的回复)与目标属性$T$(例如,是否触发有害响应)之间的依赖关系。
技术框架:论文的技术框架主要包含以下几个步骤:1) 定义目标属性$T$和可观察信号$Z$;2) 使用互信息$I(Z;T)$量化信息泄露量,即每次查询泄露的比特数;3) 推导攻击成功所需的最小查询次数下界,该下界与$I(Z;T)$成反比,与目标精度成对数关系;4) 通过实验验证理论框架的有效性,并分析不同类型信息泄露对攻击成本的影响。
关键创新:论文的关键创新在于:1) 提出了一个信息论框架,用于量化LLM对抗攻击中的信息泄露;2) 推导了攻击成功所需的最小查询次数下界,为评估攻击风险提供了理论依据;3) 通过实验验证了理论框架的有效性,并分析了不同类型信息泄露对攻击成本的影响。与现有方法相比,该方法提供了一种原则性的方法来平衡透明度和安全性。
关键设计:论文的关键设计包括:1) 使用互信息$I(Z;T)$作为信息泄露的度量,能够有效捕捉观察信号$Z$与目标属性$T$之间的依赖关系;2) 推导的查询次数下界为$\log(1/\varepsilon)/I(Z;T)$,表明攻击成本与信息泄露量成反比,与目标精度成对数关系;3) 实验中,通过控制LLM回复中泄露的信息类型(答案token、logits、思考过程),来分析不同类型信息泄露对攻击成本的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,仅暴露答案token需要约1000次查询才能成功攻击,而添加logits可以将查询次数减少到约100次,揭示完整的思考过程则只需几十次查询。这些结果验证了理论框架的有效性,并表明不同类型的信息泄露对攻击成本有显著影响。
🎯 应用场景
该研究成果可应用于LLM的安全审计和防御策略设计。通过量化信息泄露,可以帮助开发者评估LLM的潜在风险,并制定相应的防御措施,例如限制LLM回复中包含的敏感信息,从而提高LLM的安全性。此外,该研究还可以指导LLM的透明度设计,在保证安全的前提下,尽可能地提供有用的信息。
📄 摘要(原文)
Adversarial attacks by malicious users that threaten the safety of large language models (LLMs) can be viewed as attempts to infer a target property $T$ that is unknown when an instruction is issued, and becomes knowable only after the model's reply is observed. Examples of target properties $T$ include the binary flag that triggers an LLM's harmful response or rejection, and the degree to which information deleted by unlearning can be restored, both elicited via adversarial instructions. The LLM reveals an \emph{observable signal} $Z$ that potentially leaks hints for attacking through a response containing answer tokens, thinking process tokens, or logits. Yet the scale of information leaked remains anecdotal, leaving auditors without principled guidance and defenders blind to the transparency--risk trade-off. We fill this gap with an information-theoretic framework that computes how much information can be safely disclosed, and enables auditors to gauge how close their methods come to the fundamental limit. Treating the mutual information $I(Z;T)$ between the observation $Z$ and the target property $T$ as the leaked bits per query, we show that achieving error $\varepsilon$ requires at least $\log(1/\varepsilon)/I(Z;T)$ queries, scaling linearly with the inverse leak rate and only logarithmically with the desired accuracy. Thus, even a modest increase in disclosure collapses the attack cost from quadratic to logarithmic in terms of the desired accuracy. Experiments on seven LLMs across system-prompt leakage, jailbreak, and relearning attacks corroborate the theory: exposing answer tokens alone requires about a thousand queries; adding logits cuts this to about a hundred; and revealing the full thinking process trims it to a few dozen. Our results provide the first principled yardstick for balancing transparency and security when deploying LLMs.