Verifiable Fine-Tuning for LLMs: Zero-Knowledge Training Proofs Bound to Data Provenance and Policy
作者: Hasan Akgul, Daniel Borg, Arta Berisha, Amina Rahimova, Andrej Novak, Mila Petrov
分类: cs.CR, cs.CL
发布日期: 2025-10-19 (更新: 2025-12-29)
备注: 20 pages, 10 figures
💡 一句话要点
提出可验证微调方法,为大语言模型提供数据溯源和策略约束的零知识训练证明。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可验证微调 零知识证明 大语言模型 数据溯源 策略约束
📋 核心要点
- 现有大语言模型微调缺乏数据溯源和策略约束,导致信任问题。
- 提出可验证微调方法,生成零知识证明,确保模型训练过程可信。
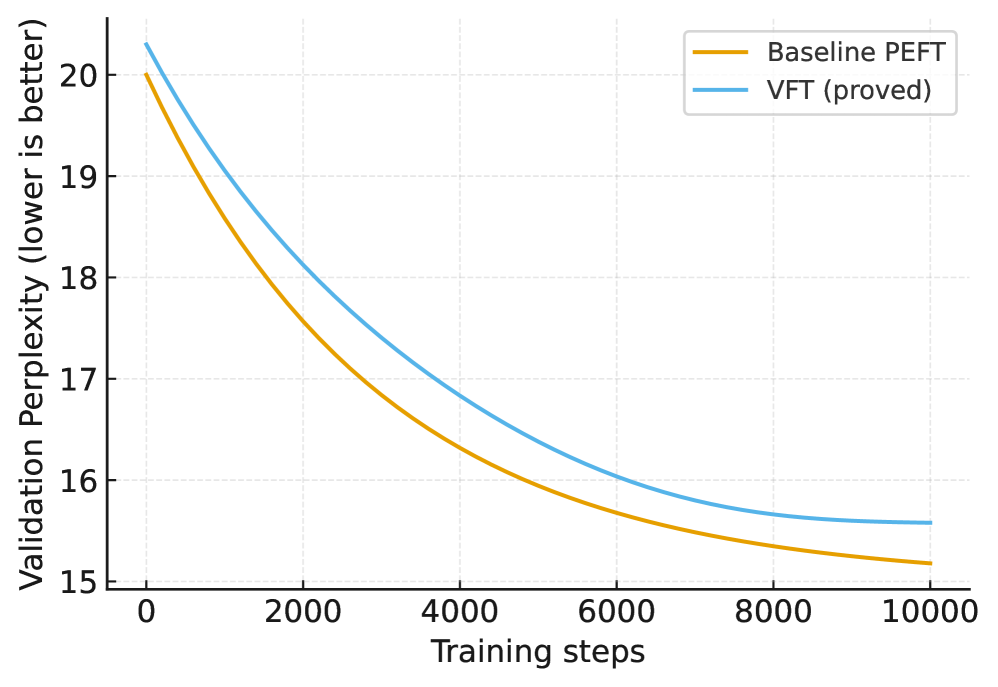
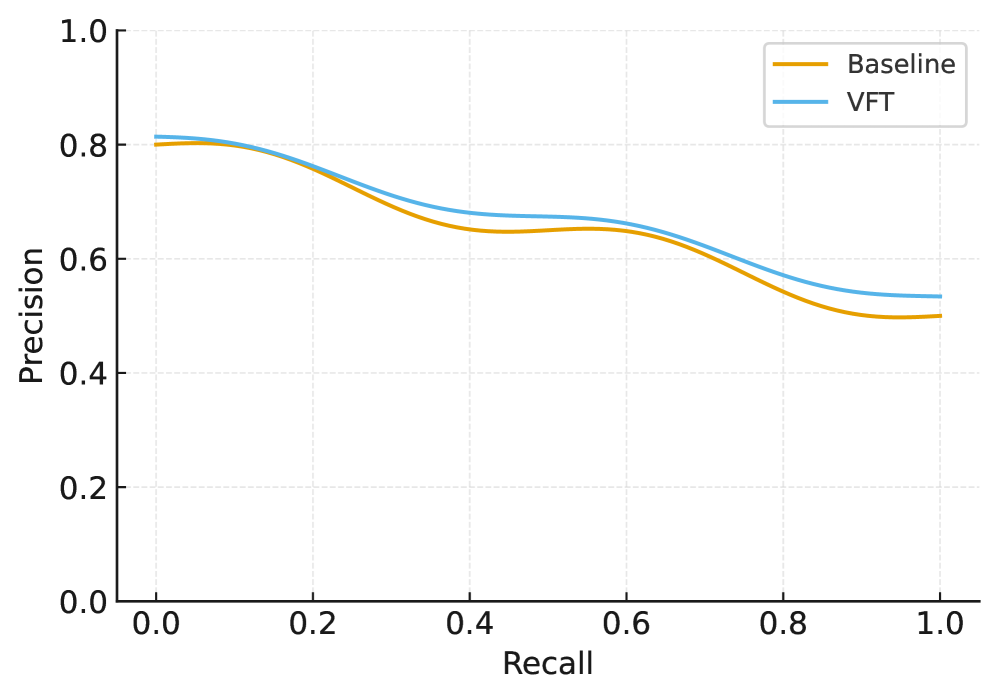
- 实验表明,该方法在保持模型效用的同时,实现了高效的证明性能,并满足策略约束。
📝 摘要(中文)
大型语言模型通常通过参数高效的微调进行适配,但目前的发布实践在数据使用和更新计算方面提供的保证不足。本文提出了一种可验证微调的协议和系统,该系统能够生成简洁的零知识证明,证明发布的模型是在声明的训练程序和可审计的数据集承诺下,从公共初始化获得的。该方法结合了五个要素:首先,将数据源、预处理、许可证和每个epoch的配额计数器绑定到清单的承诺;其次,一个可验证的采样器,支持公开可重放和私有索引隐藏的批次选择;第三,限制为参数高效微调的更新电路,该电路强制执行AdamW风格的优化器语义和具有显式误差预算的证明友好的近似;第四,递归聚合,将每个步骤的证明折叠成每个epoch和端到端的证书,验证时间仅需毫秒;第五,溯源绑定和可选的可信执行属性卡,证明代码身份和常量。在英语和双语指令混合数据上,该方法在严格的预算内保持了效用,同时实现了实际的证明性能。策略配额的执行没有违规,私有采样窗口没有显示出可测量的索引泄漏。联邦实验表明,该系统与概率审计和带宽约束相兼容。这些结果表明,对于实际的参数高效管道来说,端到端的可验证微调在今天是可行的,从而弥合了受监管和去中心化部署的关键信任缺口。
🔬 方法详解
问题定义:现有的大语言模型微调方法,在模型发布时,通常缺乏对训练数据的详细记录和策略执行的有效验证。这使得用户难以信任模型,尤其是在需要数据溯源和合规性保证的场景下。现有的方法无法提供充分的证据,证明模型确实按照声明的方式进行训练,并且没有违反任何预设的规则或限制。
核心思路:本文的核心思路是通过零知识证明技术,创建一个可验证的微调流程。该流程能够生成简洁的证明,证明发布的模型是在特定的训练程序和可审计的数据集承诺下获得的。这样,用户可以通过验证这些证明,来确认模型的训练过程是可信的,并且符合预期的策略约束。
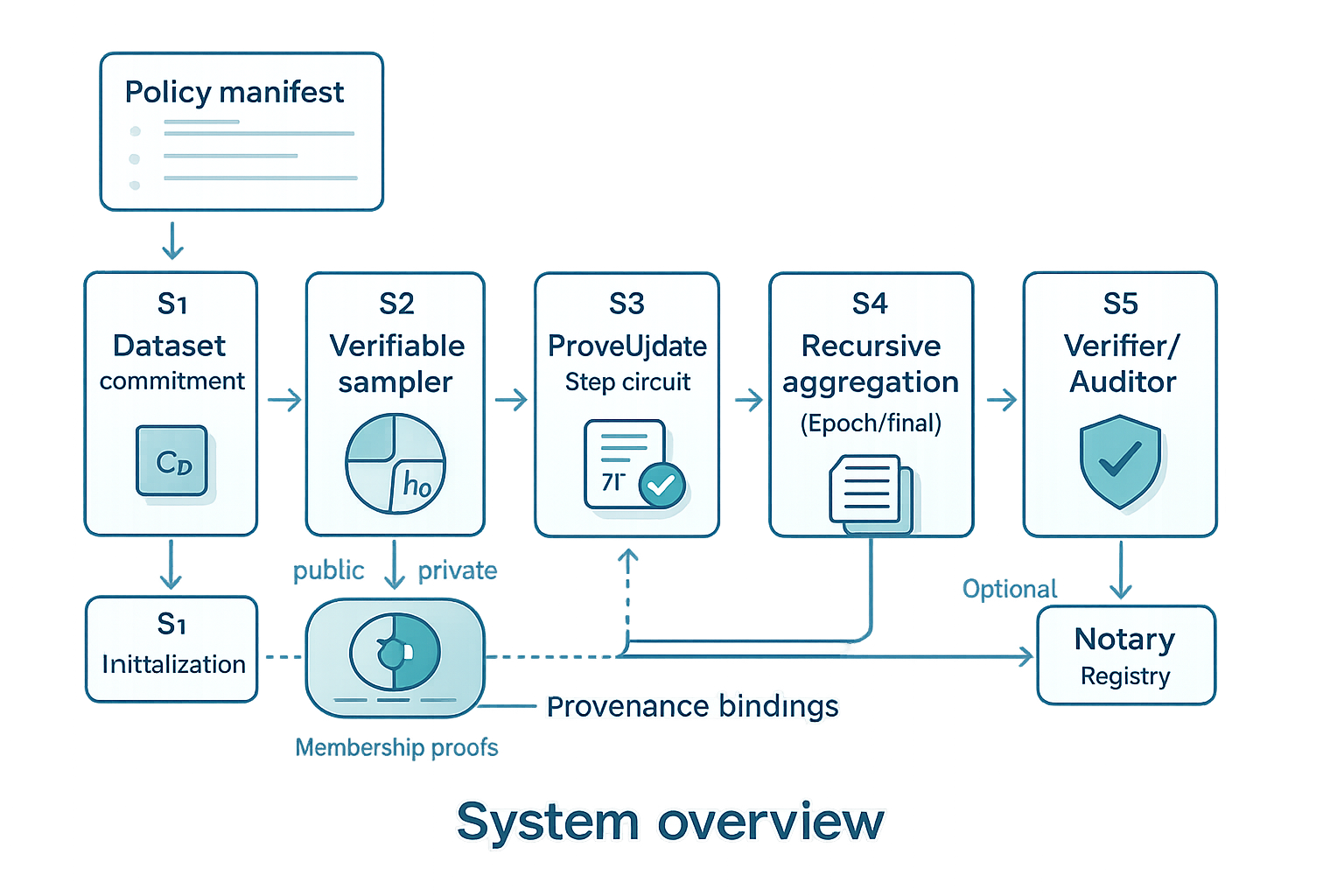
技术框架:该方法包含五个主要模块:1) 数据承诺:将数据源、预处理、许可证等信息绑定到清单,并生成承诺。2) 可验证采样器:支持公开可重放和私有索引隐藏的批次选择,确保数据采样的公平性和隐私性。3) 更新电路:限制为参数高效微调,并强制执行AdamW优化器语义和证明友好的近似。4) 递归聚合:将每步的证明聚合成每epoch和端到端的证书,提高验证效率。5) 溯源绑定:使用可信执行环境(TEE)证明代码身份和常量,增强安全性。
关键创新:该方法最重要的创新在于将零知识证明技术应用于大语言模型的微调过程,实现了端到端的可验证性。与传统方法相比,该方法能够提供更强的信任保证,并且能够有效地执行策略约束。此外,该方法还通过递归聚合技术,显著提高了证明的效率,使其能够在实际应用中可行。
关键设计:在更新电路中,使用了证明友好的近似来简化计算,并显式地考虑了误差预算。在采样器设计中,采用了私有索引隐藏技术,防止数据泄露。在递归聚合中,采用了高效的证明聚合算法,将多个证明合并成一个更小的证明。此外,还使用了参数高效微调技术,降低了证明的计算复杂度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在英语和双语指令混合数据上,能够在严格的预算内保持模型效用,同时实现实际的证明性能。策略配额的执行没有违规,私有采样窗口没有显示出可测量的索引泄漏。联邦实验表明,该系统与概率审计和带宽约束相兼容。
🎯 应用场景
该研究成果可应用于金融、医疗等对数据安全和合规性要求高的领域。通过可验证微调,可以确保模型训练过程符合监管要求,并保护用户隐私。此外,该方法还可用于去中心化场景,增强模型的可信度和透明度,促进更广泛的应用。
📄 摘要(原文)
Large language models are often adapted through parameter efficient fine tuning, but current release practices provide weak assurances about what data were used and how updates were computed. We present Verifiable Fine Tuning, a protocol and system that produces succinct zero knowledge proofs that a released model was obtained from a public initialization under a declared training program and an auditable dataset commitment. The approach combines five elements. First, commitments that bind data sources, preprocessing, licenses, and per epoch quota counters to a manifest. Second, a verifiable sampler that supports public replayable and private index hiding batch selection. Third, update circuits restricted to parameter efficient fine tuning that enforce AdamW style optimizer semantics and proof friendly approximations with explicit error budgets. Fourth, recursive aggregation that folds per step proofs into per epoch and end to end certificates with millisecond verification. Fifth, provenance binding and optional trusted execution property cards that attest code identity and constants. On English and bilingual instruction mixtures, the method maintains utility within tight budgets while achieving practical proof performance. Policy quotas are enforced with zero violations, and private sampling windows show no measurable index leakage. Federated experiments demonstrate that the system composes with probabilistic audits and bandwidth constraints. These results indicate that end to end verifiable fine tuning is feasible today for real parameter efficient pipelines, closing a critical trust gap for regulated and decentralized deployments.