Knowing the Facts but Choosing the Shortcut: Understanding How Large Language Models Compare Entities
作者: Hans Hergen Lehmann, Jae Hee Lee, Steven Schockaert, Stefan Wermter
分类: cs.CL, cs.AI
发布日期: 2025-10-19 (更新: 2026-01-24)
备注: 34 pages, 20 figures. Accepted for EACL 2026
💡 一句话要点
揭示大语言模型实体比较中的启发式偏见,并探究模型规模的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识推理 实体比较 启发式偏见 模型规模
📋 核心要点
- 现有研究缺乏对LLM在知识推理中依赖真实知识还是表面启发式的深入理解,尤其是在实体比较任务中。
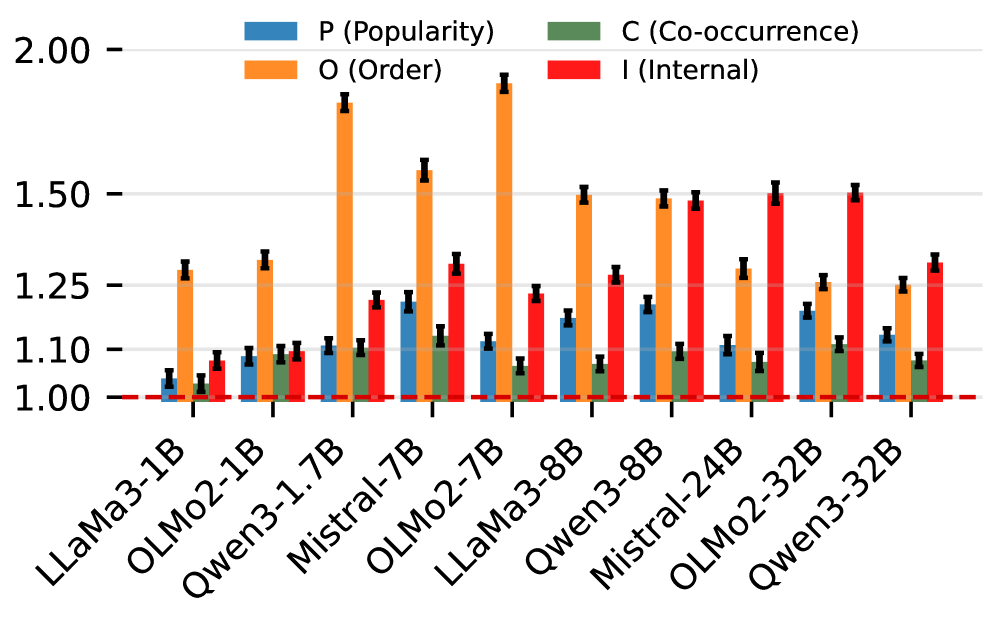
- 该论文通过分析LLM在数值属性上的实体比较,揭示了实体流行度、提及顺序和语义共现等启发式偏见。
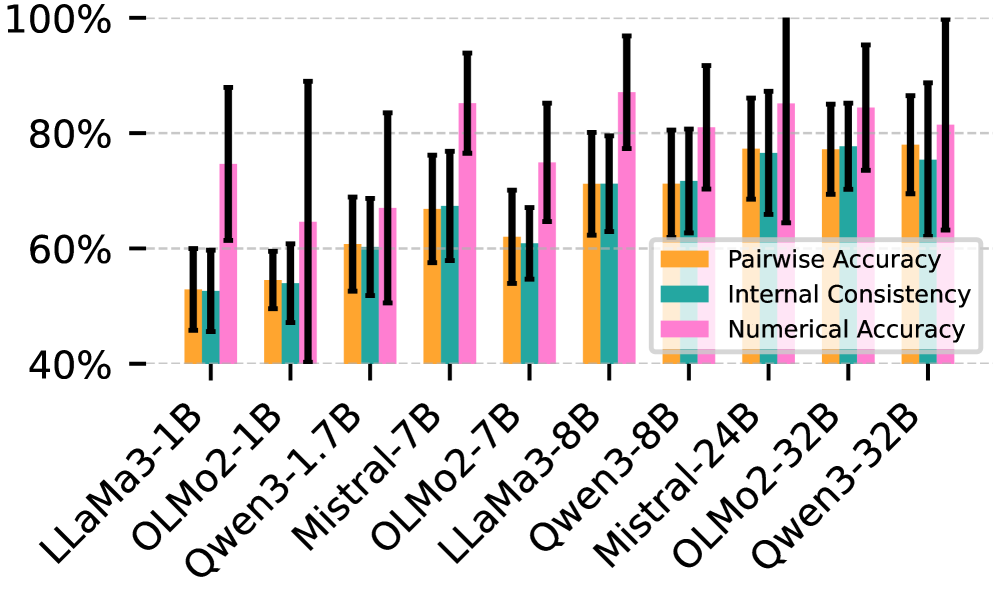
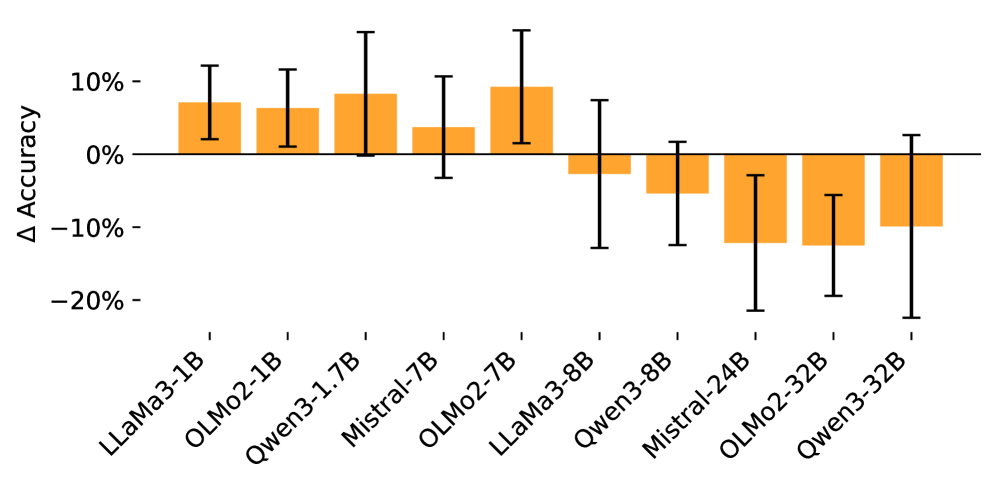
- 实验表明,小模型更依赖启发式,而大模型能选择性地利用数值知识,思维链提示可引导模型利用数值特征。
📝 摘要(中文)
大型语言模型(LLM)越来越多地用于基于知识的推理任务,但理解它们何时依赖于真实知识以及何时依赖于表面启发式方法仍然具有挑战性。我们通过实体比较任务来研究这个问题,要求模型比较实体在数值属性上的差异(例如,“多瑙河和尼罗河哪条更长?”),这为系统分析提供了明确的ground truth。尽管LLM拥有足够的数值知识来正确回答,但它们经常做出与这些知识相矛盾的预测。我们确定了三种强烈影响模型预测的启发式偏见:实体流行度、提及顺序和语义共现。对于较小的模型,仅使用这些表面线索的简单逻辑回归比模型自身的数值预测更准确地预测模型选择,这表明启发式方法在很大程度上取代了有原则的推理。至关重要的是,我们发现较大的模型(32B参数)在数值知识更可靠时有选择地依赖数值知识,而较小的模型(7-8B参数)没有表现出这种区分,这解释了为什么较大的模型即使在较小的模型拥有更准确的知识时也优于较小的模型。思维链提示引导所有模型在所有模型尺寸上使用数值特征。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在实体比较任务中,如何区分其是基于真实知识进行推理,还是仅仅依赖于表面启发式信息的问题。现有的方法难以区分这两种情况,并且缺乏对LLM内部推理机制的深入理解。尤其是在数值属性的实体比较中,LLM经常做出与已知事实相悖的错误判断,这表明其可能受到某些偏差的影响。
核心思路:论文的核心思路是通过设计特定的实体比较任务,并分析LLM的预测结果,来识别并量化影响LLM决策的启发式偏见。通过对比不同规模模型在相同任务上的表现,以及引入思维链提示等方法,来探究模型规模和提示策略对LLM推理方式的影响。核心假设是,较小的模型更容易受到启发式偏见的影响,而较大的模型可能能够更好地利用真实知识。
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 构建数据集:构建包含实体及其数值属性的数据集,用于实体比较任务。 2. 设计实验:设计一系列实体比较问题,例如“哪个河流更长?”,并要求LLM进行回答。 3. 分析预测结果:分析LLM的预测结果,识别并量化影响模型决策的启发式偏见,例如实体流行度、提及顺序和语义共现。 4. 对比不同规模模型:对比不同规模LLM在相同任务上的表现,探究模型规模对推理方式的影响。 5. 引入思维链提示:通过引入思维链提示,引导LLM进行更深入的推理,并观察其对模型决策的影响。
关键创新:该论文最重要的技术创新点在于: 1. 揭示了LLM在实体比较任务中存在的启发式偏见,并量化了这些偏见对模型决策的影响。 2. 发现了模型规模对LLM推理方式的影响,即较小的模型更容易受到启发式偏见的影响,而较大的模型能够更好地利用真实知识。 3. 证明了思维链提示可以有效地引导LLM进行更深入的推理,并减少对启发式偏见的依赖。
关键设计:论文的关键设计包括: 1. 实体比较任务的设计:选择具有明确数值属性的实体进行比较,例如河流长度、山峰高度等,以便进行客观评估。 2. 启发式偏见的量化:通过统计分析LLM的预测结果,量化实体流行度、提及顺序和语义共现等启发式偏见对模型决策的影响。 3. 模型规模的控制:选择不同规模的LLM进行对比实验,例如7-8B参数和32B参数的模型,以便探究模型规模对推理方式的影响。 4. 思维链提示的设计:设计清晰明确的思维链提示,引导LLM进行更深入的推理,例如“首先,我们需要知道X的长度,然后我们需要知道Y的长度,最后我们可以比较它们的长度。”
🖼️ 关键图片
📊 实验亮点
实验结果表明,对于较小的模型(7-8B参数),仅使用实体流行度、提及顺序和语义共现等表面线索的简单逻辑回归,比模型自身的数值预测更准确地预测模型选择。而较大的模型(32B参数)在数值知识更可靠时有选择地依赖数值知识。思维链提示可以有效地引导所有模型在所有模型尺寸上使用数值特征。
🎯 应用场景
该研究成果可应用于提升大语言模型在知识密集型任务中的可靠性和准确性,例如问答系统、知识图谱推理等。通过减少模型对表面启发式信息的依赖,并引导模型进行更深入的推理,可以提高模型在实际应用中的性能和可信度。此外,该研究还可以为模型设计和训练提供指导,例如通过引入正则化项来抑制启发式偏见,或通过使用思维链提示来提高模型的推理能力。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used for knowledge-based reasoning tasks, yet understanding when they rely on genuine knowledge versus superficial heuristics remains challenging. We investigate this question through entity comparison tasks by asking models to compare entities along numerical attributes (e.g., ``Which river is longer, the Danube or the Nile?''), which offer clear ground truth for systematic analysis. Despite having sufficient numerical knowledge to answer correctly, LLMs frequently make predictions that contradict this knowledge. We identify three heuristic biases that strongly influence model predictions: entity popularity, mention order, and semantic co-occurrence. For smaller models, a simple logistic regression using only these surface cues predicts model choices more accurately than the model's own numerical predictions, suggesting heuristics largely override principled reasoning. Crucially, we find that larger models (32B parameters) selectively rely on numerical knowledge when it is more reliable, while smaller models (7--8B parameters) show no such discrimination, which explains why larger models outperform smaller ones even when the smaller models possess more accurate knowledge. Chain-of-thought prompting steers all models towards using the numerical features across all model sizes.