MOSAIC: Masked Objective with Selective Adaptation for In-domain Contrastive Learning
作者: Vera Pavlova, Mohammed Makhlouf
分类: cs.CL, cs.AI
发布日期: 2025-10-19 (更新: 2026-01-29)
💡 一句话要点
提出MOSAIC框架,通过选择性自适应的掩码目标,实现文本嵌入模型在特定领域的对比学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 领域自适应 文本嵌入 对比学习 掩码语言建模 自然语言处理
📋 核心要点
- 现有文本嵌入模型在特定领域表现不佳,缺乏领域知识,无法有效捕捉领域内的语义关系。
- MOSAIC框架通过联合优化掩码语言建模和对比学习目标,使模型能够学习领域相关的表示,同时保持语义区分能力。
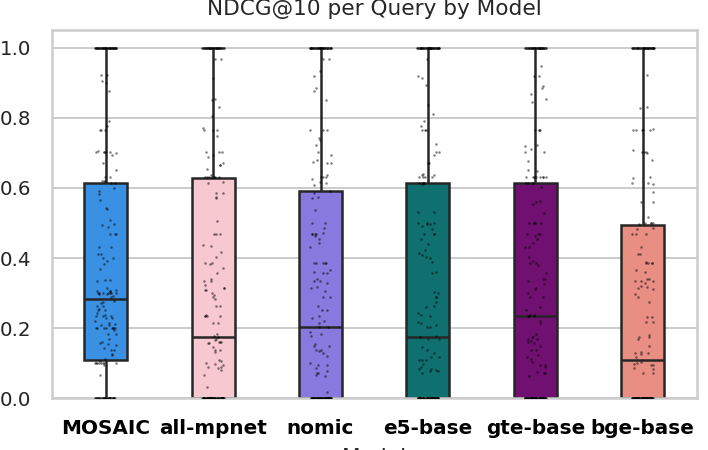
- 实验结果表明,MOSAIC在多个领域取得了显著的性能提升,NDCG@10指标最高提升13.4%。
📝 摘要(中文)
本文提出了一种名为MOSAIC(Masked Objective with Selective Adaptation for In-domain Contrastive learning)的多阶段框架,用于文本嵌入模型在特定领域的自适应,该框架融合了联合领域特定的掩码监督。该方法旨在解决将大规模通用领域文本嵌入模型适配到专业领域时面临的挑战。通过在统一的训练流程中联合优化掩码语言建模(MLM)和对比目标,该方法能够有效地学习领域相关的表示,同时保留原始模型强大的语义区分能力。在包括高资源和低资源领域在内的多个数据集上的实验验证表明,该方法相对于强大的通用领域基线,在NDCG@10(归一化折损累计增益)指标上取得了高达13.4%的提升。全面的消融研究进一步证明了每个组件的有效性,突出了平衡的联合监督和分阶段自适应的重要性。
🔬 方法详解
问题定义:论文旨在解决通用文本嵌入模型在特定领域表现不佳的问题。现有方法难以有效迁移通用知识到特定领域,并且缺乏领域相关的语义理解能力,导致在特定领域的任务中性能下降。
核心思路:MOSAIC的核心思路是通过联合训练掩码语言模型(MLM)和对比学习目标,使模型能够同时学习领域相关的语言知识和保持良好的语义区分能力。通过选择性地自适应领域数据,模型能够更好地适应特定领域的特点。
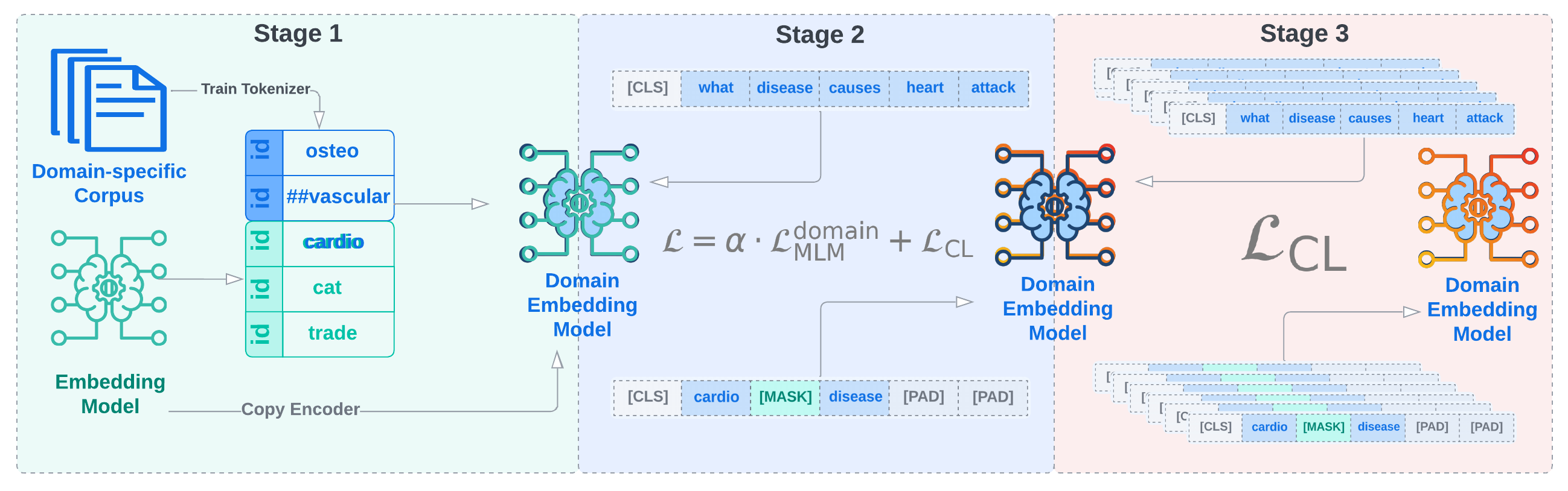
技术框架:MOSAIC是一个多阶段的训练框架,主要包含以下几个阶段:1) 预训练的通用文本嵌入模型初始化;2) 使用领域数据进行掩码语言建模(MLM)训练,使模型学习领域相关的语言知识;3) 使用领域数据进行对比学习训练,增强模型在领域内的语义区分能力;4) 联合优化MLM和对比学习目标,平衡领域知识学习和语义区分能力。
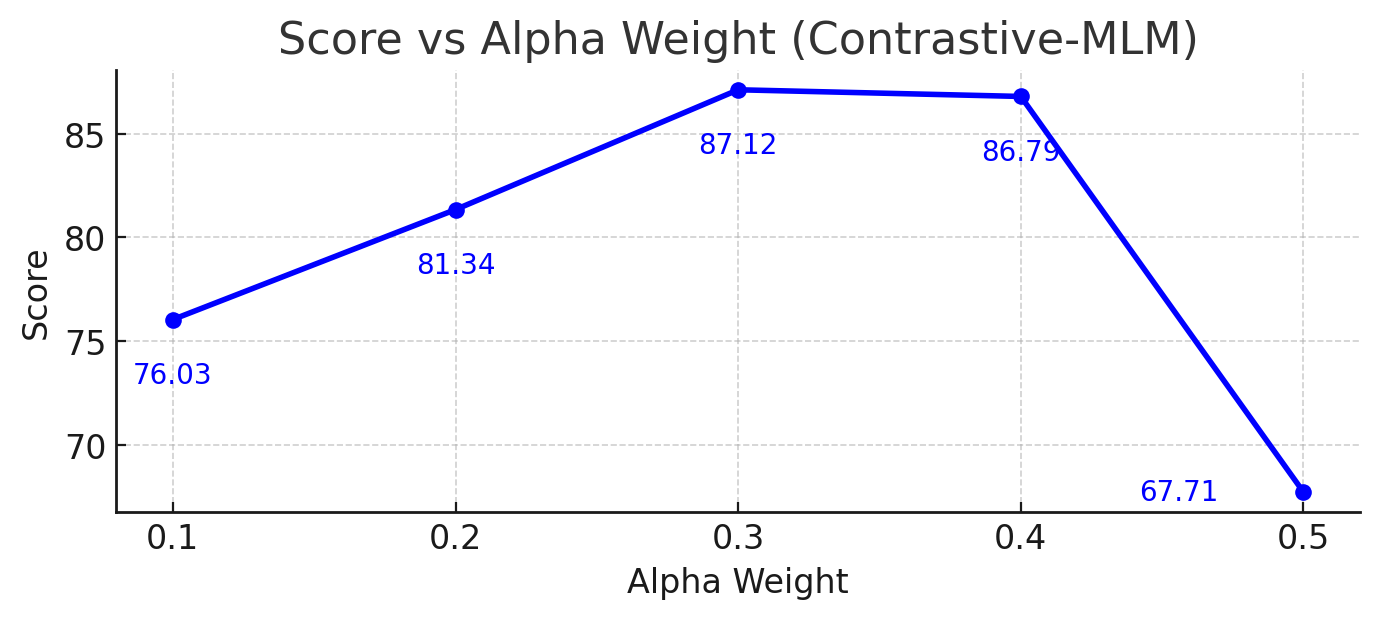
关键创新:MOSAIC的关键创新在于联合优化掩码语言建模和对比学习目标,并采用选择性自适应策略。这种联合优化能够使模型在学习领域知识的同时,保持良好的语义区分能力,从而在特定领域取得更好的性能。选择性自适应策略允许模型根据领域数据的特点,调整学习的重点,从而更好地适应特定领域。
关键设计:MOSAIC的关键设计包括:1) 使用Transformer作为基础模型架构;2) 采用BERT的掩码策略进行MLM训练;3) 使用InfoNCE损失函数进行对比学习训练;4) 通过调整MLM和对比学习损失的权重,平衡领域知识学习和语义区分能力;5) 分阶段进行训练,先进行MLM训练,再进行对比学习训练,最后进行联合优化。
🖼️ 关键图片
📊 实验亮点
MOSAIC在多个领域数据集上进行了实验验证,结果表明,相对于强大的通用领域基线,MOSAIC在NDCG@10指标上取得了显著的提升,最高提升幅度达到13.4%。消融研究表明,联合优化MLM和对比学习目标,以及分阶段训练策略,对MOSAIC的性能提升至关重要。
🎯 应用场景
MOSAIC框架可应用于各种需要领域特定文本理解的场景,例如:医学文本分析、金融文档处理、法律文本挖掘等。通过提升文本嵌入模型在特定领域的性能,可以改善信息检索、文本分类、问答系统等下游任务的效果,具有重要的实际应用价值和商业前景。
📄 摘要(原文)
We introduce MOSAIC (Masked Objective with Selective Adaptation for In-domain Contrastive learning), a multi-stage framework for domain adaptation of text embedding models that incorporates joint domain-specific masked supervision. Our approach addresses the challenges of adapting large-scale general-domain text embedding models to specialized domains. By jointly optimizing masked language modeling (MLM) and contrastive objectives within a unified training pipeline, our method enables effective learning of domain-relevant representations while preserving the robust semantic discrimination properties of the original model. We empirically validate our approach on both high-resource and low-resource domains, achieving improvements up to 13.4% in NDCG@10 (Normalized Discounted Cumulative Gain) over strong general-domain baselines. Comprehensive ablation studies further demonstrate the effectiveness of each component, highlighting the importance of balanced joint supervision and staged adaptation.