U-Codec: Ultra Low Frame-rate Neural Speech Codec for Fast High-fidelity Speech Generation
作者: Xusheng Yang, Long Zhou, Wenfu Wang, Kai Hu, Shulin Feng, Chenxing Li, Meng Yu, Dong Yu, Yuexian Zou
分类: cs.SD, cs.CL, cs.LG
发布日期: 2025-10-19
💡 一句话要点
提出U-Codec,一种超低帧率神经语音编解码器,用于快速高保真语音生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音编解码 神经语音合成 低帧率 Transformer 残差向量量化 LLM-TTS 语音重建
📋 核心要点
- 现有语音编解码器在极低帧率下会损失语音清晰度和频谱细节,难以实现高质量语音合成。
- U-Codec通过Transformer帧间依赖模块和残差向量量化,在5Hz超低帧率下保持语音质量。
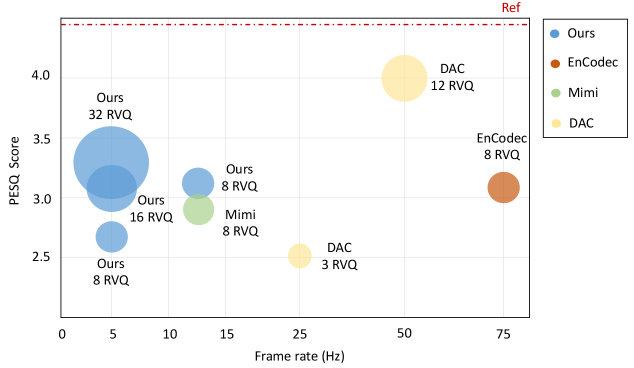
- 实验表明,U-Codec能显著加速LLM-TTS推理,在保持语音自然度的同时,速度提升约3倍。
📝 摘要(中文)
本文提出了一种超低帧率神经语音编解码器U-Codec,它以极低的5Hz帧率(每秒5帧)实现高保真重建和快速语音生成。在5Hz的极端压缩下,通常会导致严重的清晰度和频谱细节损失。为此,我们引入了一个基于Transformer的帧间长期依赖模块,并系统地探索了残差向量量化(RVQ)的深度和码本大小,以确定最佳配置。此外,我们将U-Codec应用于基于大型语言模型(LLM)的自回归TTS模型,该模型利用全局和局部分层架构来有效地捕获跨多层token的依赖关系。我们将基于LLM的TTS从50Hz的3层RVQ扩展到5Hz的32层RVQ。实验结果表明,与高帧率编解码器相比,U-Codec将基于LLM的TTS推理速度提高了约3倍,同时保持了相似性和自然度。这些结果验证了使用高度压缩的5Hz离散token进行快速和高保真语音合成的可行性。
🔬 方法详解
问题定义:论文旨在解决在极低帧率(5Hz)下进行高质量语音编解码的问题。现有的语音编解码器在如此低的帧率下会面临严重的语音清晰度和频谱细节损失,导致合成语音质量显著下降,难以满足快速且高质量语音生成的需求。
核心思路:论文的核心思路是通过引入Transformer架构来建模帧间的长期依赖关系,并结合残差向量量化(RVQ)技术,在超低帧率下尽可能保留语音的关键信息。通过这种方式,即使在极端压缩的情况下,也能重建出高保真度的语音。
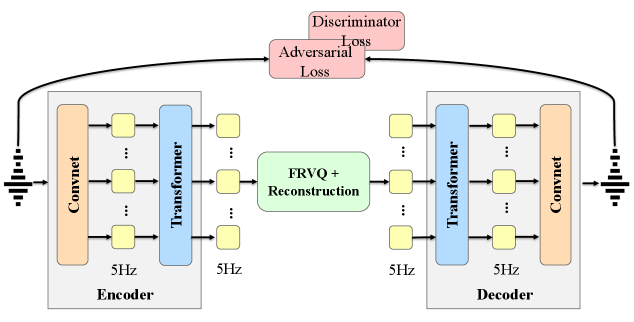
技术框架:U-Codec主要包含编码器和解码器两部分。编码器将输入语音转换为一系列离散的token,这些token以5Hz的帧率表示语音信息。编码器中使用了Transformer模块来捕获帧间的长期依赖关系,从而更好地保留语音的上下文信息。解码器则将这些离散token转换回语音信号。此外,论文还将U-Codec集成到基于LLM的TTS系统中,利用LLM强大的建模能力来生成高质量的语音。
关键创新:论文的关键创新在于将Transformer架构和残差向量量化技术结合,用于超低帧率的语音编解码。传统的语音编解码器难以在如此低的帧率下保持语音质量,而U-Codec通过建模帧间依赖关系和优化量化策略,显著提升了低帧率语音的重建质量。此外,将U-Codec与LLM-TTS结合,实现了快速且高质量的语音合成。
关键设计:U-Codec的关键设计包括:1) 基于Transformer的帧间依赖模块,用于捕获语音的长期上下文信息;2) 残差向量量化(RVQ)的深度和码本大小的优化,以找到最佳的量化配置;3) 将U-Codec集成到LLM-TTS系统中,利用LLM的建模能力来生成高质量的语音。论文探索了不同RVQ深度和码本大小的配置,最终选择了32层RVQ,以在5Hz的帧率下实现最佳的语音质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,U-Codec在5Hz的超低帧率下,能够实现高保真的语音重建。与高帧率编解码器相比,U-Codec将基于LLM的TTS推理速度提高了约3倍,同时保持了语音的相似性和自然度。这些结果验证了U-Codec在快速语音合成方面的有效性。
🎯 应用场景
U-Codec在需要快速语音合成的场景中具有广泛的应用前景,例如语音助手、游戏、实时语音翻译等。其超低帧率的特性使其在带宽受限的环境下也能实现高质量的语音通信。此外,U-Codec与LLM-TTS的结合,为构建更高效、更自然的语音交互系统提供了新的可能性。
📄 摘要(原文)
We propose \textbf{U-Codec}, an \textbf{U}ltra low frame-rate neural speech \textbf{Codec} that achieves high-fidelity reconstruction and fast speech generation at an extremely low frame-rate of 5Hz (5 frames per second). Extreme compression at 5Hz typically leads to severe intelligibility and spectral detail loss, we introduce a Transformer-based inter-frame long-term dependency module and systematically explore residual vector quantization (RVQ) depth and codebook size to identify optimal configurations. Moreover, we apply U-Codec into a large language model (LLM)-based auto-regressive TTS model, which leverages global and local hierarchical architecture to effectively capture dependencies across multi-layer tokens. We extend LLM-based TTS from 3-layer RVQ at 50Hz to 32-layer RVQ at 5Hz. Experimental results demonstrate that U-Codec improves LLM-based TTS inference speed by around 3 $\times$ over high-frame-rate codecs while maintaining similarity and naturalness. These results validate the feasibility of using highly compressed 5Hz discrete tokens for fast and high-fidelity speech synthesis.