so much depends / upon / a whitespace: Why Whitespace Matters for Poets and LLMs
作者: Sriharsh Bhyravajjula, Melanie Walsh, Anna Preus, Maria Antoniak
分类: cs.CL
发布日期: 2025-10-19
期刊: Text2Story Workshop @ ECIR 2022, CEUR Workshop Proceedings, Vol. 3117, pp. 67-74, 2022. Available at https://ceur-ws.org/Vol-3117/paper7.pdf
💡 一句话要点
关注诗歌空白符:研究空白符对诗歌创作和LLM生成诗歌的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 诗歌生成 空白符 大型语言模型 文本处理 诗歌分析
📋 核心要点
- 现有NLP研究对诗歌中空白符的关注不足,忽略了其在语义和形式上的重要作用。
- 通过分析大量诗歌语料库,研究不同诗人、时期和来源的空白符使用模式。
- 对比分析已发表诗歌、LLM生成诗歌和在线社区诗歌的空白符使用情况,揭示差异。
📝 摘要(中文)
空白符是诗歌形式的关键组成部分,既反映了对标准化形式的遵守,也反映了对这些形式的反叛。每首诗的空白符分布都反映了诗人的艺术选择,是诗歌不可或缺的语义和空间特征。然而,尽管诗歌作为一种历史悠久的艺术形式和大型语言模型(LLM)的生成任务而广受欢迎,但NLP社区对空白符的关注不足。本文使用来自 Poetry Foundation 的包含 1.9 万首英语诗歌的语料库,研究了 4000 位诗人如何在作品中使用空白符。我们发布了包含 2.8 千首具有保留格式的公共领域诗歌的子集,以促进该领域的进一步研究。我们将已发表诗歌中的空白符使用情况与 (1) 5.1 万首 LLM 生成的诗歌和 (2) 在线社区发布的 1.2 万首未发表的诗歌进行了比较。我们还探讨了不同时期、诗歌形式和数据来源的空白符使用情况。此外,我们发现不同的文本处理方法可能导致诗歌数据中空白符的显著不同表示,这促使我们使用这些诗歌和空白符模式来讨论用于组装 LLM 预训练数据集的处理策略的影响。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成诗歌时,对空白符的使用与人类诗人存在的差异问题。现有方法在处理诗歌文本时,往往忽略或错误地处理空白符,导致生成的诗歌在形式和语义上与人类创作的诗歌存在差距。这种忽略源于对空白符在诗歌中作用的认识不足。
核心思路:论文的核心思路是通过量化分析不同来源(已发表诗歌、LLM生成诗歌、在线社区诗歌)的诗歌中空白符的使用模式,揭示空白符在诗歌创作中的重要性。通过对比分析,可以了解LLM在生成诗歌时对空白符的理解和运用是否符合人类诗人的习惯,从而为改进LLM的诗歌生成能力提供指导。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据收集:收集来自 Poetry Foundation 的已发表诗歌、LLM 生成的诗歌以及在线社区的诗歌。2) 预处理:对收集到的诗歌数据进行预处理,包括保留原始格式的空白符。3) 特征提取:提取诗歌中与空白符相关的特征,例如行首空格数、行尾空格数、行间空格数等。4) 对比分析:对不同来源的诗歌数据进行对比分析,比较它们在空白符使用上的差异。5) 误差分析:分析不同文本处理方法对空白符表示的影响。
关键创新:论文的关键创新在于强调了空白符在诗歌中的重要性,并首次系统地研究了不同来源的诗歌中空白符的使用模式。通过对比分析,揭示了LLM在生成诗歌时对空白符的理解和运用与人类诗人存在的差异。此外,论文还探讨了不同的文本处理方法对空白符表示的影响,为LLM预训练数据集的构建提供了新的视角。
关键设计:论文的关键设计包括:1) 构建了一个包含大量诗歌数据的语料库,涵盖了不同来源、时期和风格的诗歌。2) 设计了一系列与空白符相关的特征,用于量化分析诗歌中空白符的使用模式。3) 采用了多种统计分析方法,例如 t 检验、方差分析等,用于比较不同来源的诗歌数据在空白符使用上的差异。4) 探讨了不同的文本处理方法(例如分词、词干提取等)对空白符表示的影响,并提出了相应的建议。
🖼️ 关键图片

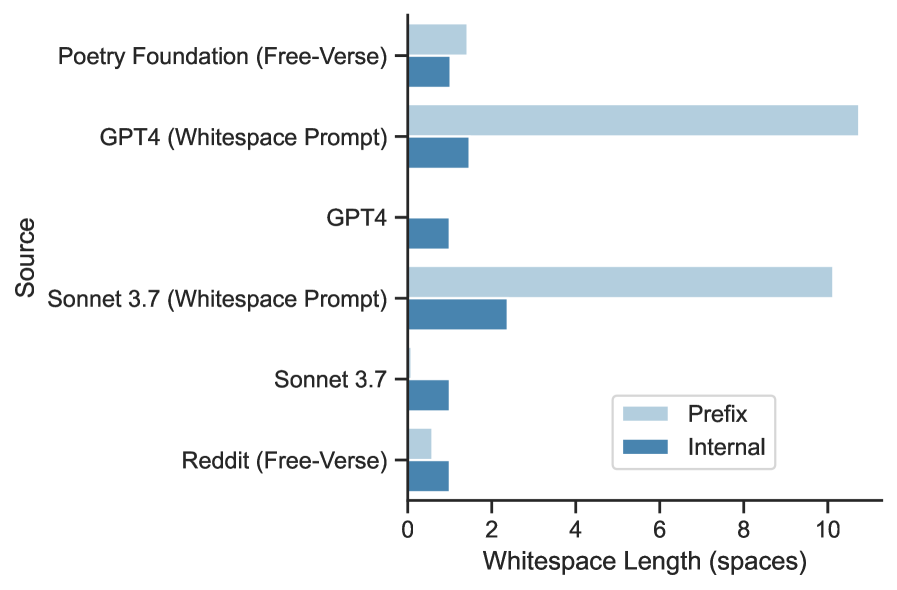
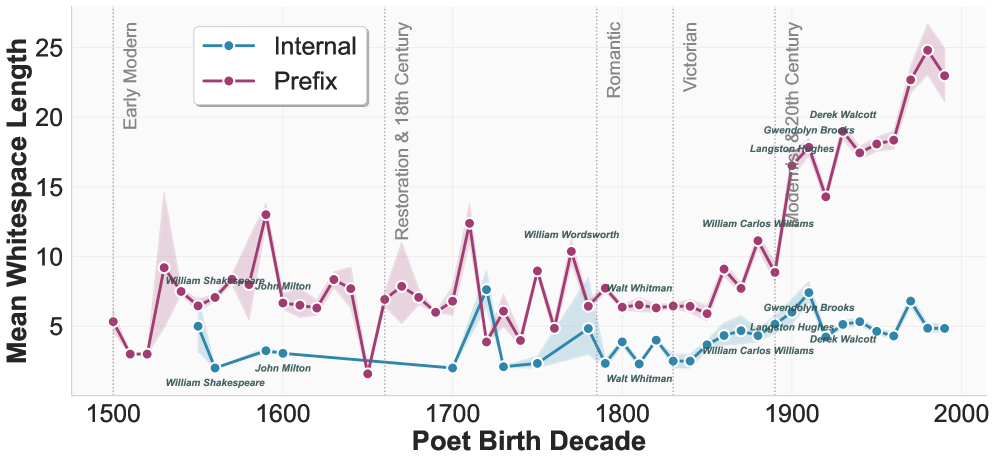
📊 实验亮点
研究发现,LLM生成的诗歌在空白符使用上与人类诗人存在显著差异。例如,LLM生成的诗歌往往缺乏人类诗人使用的某些特定的空白符模式。通过对比分析,论文量化了这些差异,并为改进LLM的诗歌生成能力提供了具体的指导。
🎯 应用场景
该研究成果可应用于改进LLM的诗歌生成能力,使其生成的诗歌在形式和语义上更接近人类创作的诗歌。此外,该研究还可以为诗歌教学和研究提供新的视角,帮助人们更好地理解诗歌的艺术价值。该研究对于提升人机交互的自然性和艺术性具有潜在价值。
📄 摘要(原文)
Whitespace is a critical component of poetic form, reflecting both adherence to standardized forms and rebellion against those forms. Each poem's whitespace distribution reflects the artistic choices of the poet and is an integral semantic and spatial feature of the poem. Yet, despite the popularity of poetry as both a long-standing art form and as a generation task for large language models (LLMs), whitespace has not received sufficient attention from the NLP community. Using a corpus of 19k English-language published poems from Poetry Foundation, we investigate how 4k poets have used whitespace in their works. We release a subset of 2.8k public-domain poems with preserved formatting to facilitate further research in this area. We compare whitespace usage in the published poems to (1) 51k LLM-generated poems, and (2) 12k unpublished poems posted in an online community. We also explore whitespace usage across time periods, poetic forms, and data sources. Additionally, we find that different text processing methods can result in significantly different representations of whitespace in poetry data, motivating us to use these poems and whitespace patterns to discuss implications for the processing strategies used to assemble pretraining datasets for LLMs.