Natural Language Processing for Cardiology: A Narrative Review
作者: Kailai Yang, Yan Leng, Xin Zhang, Tianlin Zhang, Paul Thompson, Bernard Keavney, Maciej Tomaszewski, Sophia Ananiadou
分类: cs.CL, cs.AI
发布日期: 2025-10-19 (更新: 2025-10-22)
💡 一句话要点
综述性研究:利用自然语言处理技术解决心血管疾病领域的挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言处理 心血管疾病 医学文本挖掘 大型语言模型 综述研究
📋 核心要点
- 心血管疾病信息分散在各种非结构化文本数据中,难以有效利用,阻碍了疾病的诊断、治疗和预防。
- 利用自然语言处理技术,从患者叙述、医疗记录和文献中提取关键信息,为心血管疾病研究提供新的视角。
- 通过对2014-2025年相关研究的系统分析,揭示了NLP在心血管病学中的应用趋势、挑战和未来方向。
📝 摘要(中文)
心血管疾病日益普遍,对全球健康产生深远影响。这些疾病复杂且受多种因素影响,包括遗传、生活方式和社会经济因素。相关信息分散在患者叙述、医疗记录和科学文献等多种文本数据中。自然语言处理(NLP)为分析此类非结构化数据提供了强大方法,使医疗专业人员和研究人员能够获得更深入的见解,从而改变心脏疾病的诊断、治疗和预防。本综述全面概述了2014年至2025年心血管病学中的NLP研究。系统检索了六个文献数据库,筛选出265篇相关文章,并从NLP范式、心脏病相关任务、疾病类型和数据来源等多维度分析。研究结果表明,这些维度存在显著多样性,反映了NLP在心脏病学研究中的广度和演变。时间分析进一步突出了方法学趋势,展示了从基于规则的系统到大型语言模型的演进。最后,讨论了关键挑战和未来方向,例如开发可解释的LLM和整合多模态数据。据我们所知,本综述是迄今为止对心脏病学NLP研究最全面的总结。
🔬 方法详解
问题定义:心血管疾病相关信息分散在各种非结构化文本数据中,例如患者病历、医学文献等,人工提取和分析效率低下且容易出错。现有方法难以有效整合这些信息,从而影响疾病的诊断、治疗和预防。因此,需要一种能够自动、高效地处理这些文本数据的工具。
核心思路:利用自然语言处理(NLP)技术,特别是近年来兴起的大型语言模型(LLM),自动提取和分析心血管疾病相关的文本信息。通过对大量文本数据的学习,LLM能够理解医学术语、识别疾病特征、关联风险因素,从而辅助医生进行诊断和治疗。
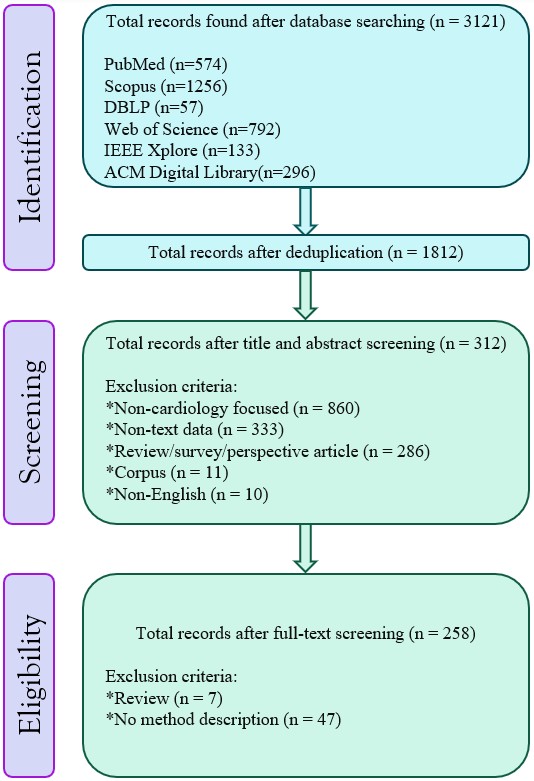
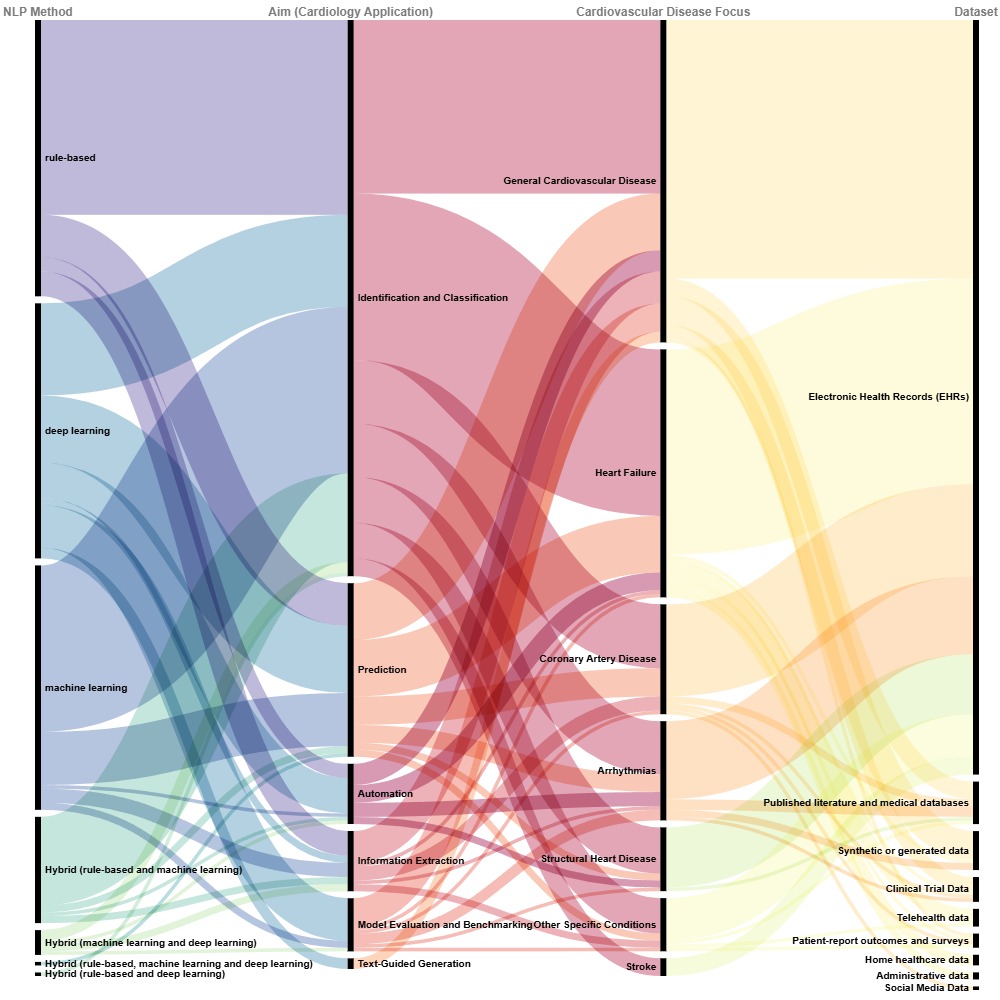
技术框架:该综述性研究主要通过以下步骤进行:1) 系统性文献检索:在六个主要的文献数据库中检索2014年至2025年间发表的关于NLP在心血管疾病应用的文章。2) 严格筛选:根据预定的标准筛选出相关的研究论文。3) 多维度分析:对筛选出的论文进行多维度分析,包括NLP范式、心脏病相关任务、疾病类型和数据来源等。4) 时间趋势分析:分析不同时间段内NLP方法在心血管疾病研究中的应用趋势。5) 总结挑战和未来方向:讨论当前研究面临的挑战,并展望未来的研究方向。
关键创新:该研究的关键创新在于对心血管疾病领域NLP研究的全面、系统的综述。它不仅总结了现有研究的成果,还分析了不同方法之间的差异和优劣,并指出了未来的研究方向。此外,该研究还强调了大型语言模型在心血管疾病研究中的潜力,并讨论了如何开发可解释的LLM。
关键设计:该综述性研究的关键设计在于其系统性的文献检索和多维度分析方法。通过在多个数据库中进行检索,并采用严格的筛选标准,确保了研究的全面性和可靠性。通过对NLP范式、心脏病相关任务、疾病类型和数据来源等多维度分析,能够更深入地了解NLP在心血管疾病研究中的应用情况。
🖼️ 关键图片

📊 实验亮点
该综述性研究分析了265篇相关文章,揭示了NLP在心血管病学研究中的广度和演变,展示了从基于规则的系统到大型语言模型的演进,并讨论了开发可解释的LLM和整合多模态数据等关键挑战和未来方向。该研究是迄今为止对心脏病学NLP研究最全面的总结。
🎯 应用场景
该研究成果可应用于辅助心血管疾病的诊断、治疗和预防。例如,可以利用NLP技术分析患者病历,自动识别疾病风险因素,为医生提供决策支持。还可以利用NLP技术分析医学文献,发现新的治疗方法和药物。此外,该研究还可以促进NLP技术在其他医学领域的应用。
📄 摘要(原文)
Cardiovascular diseases are becoming increasingly prevalent in modern society, with a profound impact on global health and well-being. These Cardiovascular disorders are complex and multifactorial, influenced by genetic predispositions, lifestyle choices, and diverse socioeconomic and clinical factors. Information about these interrelated factors is dispersed across multiple types of textual data, including patient narratives, medical records, and scientific literature. Natural language processing (NLP) has emerged as a powerful approach for analysing such unstructured data, enabling healthcare professionals and researchers to gain deeper insights that may transform the diagnosis, treatment, and prevention of cardiac disorders. This review provides a comprehensive overview of NLP research in cardiology from 2014 to 2025. We systematically searched six literature databases for studies describing NLP applications across a range of cardiovascular diseases. After a rigorous screening process, we identified 265 relevant articles. Each study was analysed across multiple dimensions, including NLP paradigms, cardiology-related tasks, disease types, and data sources. Our findings reveal substantial diversity within these dimensions, reflecting the breadth and evolution of NLP research in cardiology. A temporal analysis further highlights methodological trends, showing a progression from rule-based systems to large language models. Finally, we discuss key challenges and future directions, such as developing interpretable LLMs and integrating multimodal data. To the best of our knowledge, this review represents the most comprehensive synthesis of NLP research in cardiology to date.