Investigating the Impact of Rationales for LLMs on Natural Language Understanding
作者: Wenhang Shi, Shuqing Bian, Yiren Chen, Xinyi Zhang, Zhe Zhao, Pengfei Hu, Wei Lu, Xiaoyong Du
分类: cs.CL
发布日期: 2025-10-19
💡 一句话要点
研究推理链对LLM在自然语言理解任务中的影响,并提出相应优化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言理解 大型语言模型 推理链 思维链 可解释性 数据集构建 模型训练
📋 核心要点
- 现有研究忽略了推理链(CoT)对自然语言理解(NLU)任务的潜在影响,缺乏系统性探索。
- 构建包含推理链的NLURC数据集,并开发多种推理链增强方法,探索其在NLU任务中的有效性。
- 实验表明,CoT推理性能随模型增大而提升,特定设计的推理链训练方法可显著提升NLU性能。
📝 摘要(中文)
本文研究了思维链(CoT)推理对大型语言模型(LLM)在自然语言理解(NLU)任务中的影响。思维链通过提供逐步推理来得出最终答案,从而有益于LLM的推理和训练。虽然以往研究主要关注推理链在数学、符号和常识推理任务中的作用,但忽略了其对NLU任务的潜在影响。本文提出了一个问题:推理链是否也能同样有益于NLU任务?为了进行系统的探索,我们构建了NLURC,一个包含推理链的综合性高质量NLU数据集集合,并开发了各种推理链增强方法。通过使用该数据集探索这些方法在NLU任务中的适用性,我们发现了一些潜在的令人惊讶的发现:(1)随着模型规模的增长,CoT推理从阻碍NLU性能转变为超越直接标签预测,表明存在正相关关系。(2)大多数推理链增强训练方法的效果不如仅使用标签的训练,但有一种专门设计的方法始终能够实现改进。(3)使用推理链训练的LLM在未见过的NLU任务上取得了显著的性能提升,可以与规模是其十倍的模型相媲美,同时提供与商业LLM相当的可解释性。
🔬 方法详解
问题定义:论文旨在研究推理链(Chain-of-Thought, CoT)对大型语言模型(LLM)在自然语言理解(NLU)任务中的影响。现有方法主要关注CoT在推理任务中的作用,忽略了其在NLU任务中的潜力。直接将CoT应用于NLU任务可能并不直接有效,甚至可能损害性能。
核心思路:论文的核心思路是通过构建包含推理链的NLU数据集(NLURC),并设计不同的推理链增强方法,来系统性地探索CoT在NLU任务中的作用。通过实验分析,揭示CoT对NLU任务的影响规律,并找到有效的CoT增强方法。
技术框架:整体框架包括以下几个主要步骤:1) 构建NLURC数据集,该数据集包含NLU任务的输入、输出以及相应的推理链;2) 设计多种推理链增强方法,包括CoT推理和CoT训练;3) 在NLURC数据集上评估这些方法的性能,并与基线方法进行比较;4) 分析实验结果,总结CoT对NLU任务的影响规律,并提出改进建议。
关键创新:论文的关键创新点在于:1) 构建了高质量的NLURC数据集,为研究CoT在NLU任务中的作用提供了数据基础;2) 发现了CoT推理性能随模型增大而提升的现象,并提出了一种专门设计的推理链训练方法,能够有效提升NLU性能;3) 揭示了推理链在提升模型可解释性方面的作用。
关键设计:论文的关键设计包括:1) NLURC数据集的构建,需要保证推理链的质量和多样性;2) 推理链增强方法的选择,需要考虑不同的CoT使用方式(推理时生成或训练时加入);3) 实验评估指标的选择,需要能够全面反映模型在NLU任务上的性能和可解释性。具体参数设置和网络结构取决于所使用的LLM模型。
🖼️ 关键图片


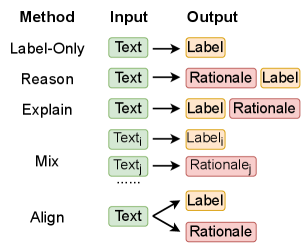
📊 实验亮点
实验结果表明,随着模型规模的增长,CoT推理从阻碍NLU性能转变为超越直接标签预测。一种专门设计的推理链训练方法始终能够实现改进,并且使用推理链训练的LLM在未见过的NLU任务上取得了显著的性能提升,可以与规模是其十倍的模型相媲美。
🎯 应用场景
该研究成果可应用于提升各种自然语言理解任务的性能,例如文本分类、情感分析、命名实体识别等。通过引入推理链,可以提高模型的可解释性,使其更易于理解和调试。此外,该研究还可以促进LLM在更多领域的应用,例如智能客服、机器翻译等。
📄 摘要(原文)
Chain-of-thought (CoT) rationales, which provide step-by-step reasoning to derive final answers, benefit LLMs in both inference and training. Incorporating rationales, either by generating them before answering during inference, or by placing them before or after the original answers during training - significantly improves model performance on mathematical, symbolic and commonsense reasoning tasks. However, most work focuses on the role of rationales in these reasoning tasks, overlooking their potential impact on other important tasks like natural language understanding (NLU) tasks. In this work, we raise the question: Can rationales similarly benefit NLU tasks? To conduct a systematic exploration, we construct NLURC, a comprehensive and high-quality NLU dataset collection with rationales, and develop various rationale-augmented methods. Through exploring the applicability of these methods on NLU tasks using the dataset, we uncover several potentially surprising findings: (1) CoT inference shifts from hindering NLU performance to surpassing direct label prediction as model size grows, indicating a positive correlation. (2) Most rationale-augmented training methods perform worse than label-only training, with one specially designed method consistently achieving improvements. (3) LLMs trained with rationales achieve significant performance gains on unseen NLU tasks, rivaling models ten times their size, while delivering interpretability on par with commercial LLMs.