All You Need is One: Capsule Prompt Tuning with a Single Vector
作者: Yiyang Liu, James C. Liang, Heng Fan, Wenhao Yang, Yiming Cui, Xiaotian Han, Lifu Huang, Dongfang Liu, Qifan Wang, Cheng Han
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-19
备注: NeurIPS 2025
💡 一句话要点
提出CaPT:利用单向量胶囊提示调整,提升大语言模型在下游任务的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示学习 参数高效微调 大语言模型 注意力机制 实例感知 胶囊提示 单向量提示
📋 核心要点
- 现有基于提示学习的方法依赖大量提示和网格搜索,计算成本高昂,且缺乏实例相关信息。
- CaPT通过单向量胶囊提示,同时融入实例相关和任务相关信息,作为“注意力锚点”提升性能。
- 实验表明,CaPT在多种语言任务上表现出色,例如T5-Large平均准确率84.03%,且参数效率高。
📝 摘要(中文)
基于提示的学习已成为一种参数高效的微调方法(PEFT),通过任务相关的指导来调节生成过程,从而促进大型语言模型(LLM)适应下游任务。然而,当前的基于提示的学习方法严重依赖于费力的网格搜索以获得最佳提示长度,并且通常需要大量的提示,从而引入额外的计算负担。更糟糕的是,我们的初步研究结果表明,任务相关的提示设计本质上受到缺乏实例相关信息的限制,导致与输入序列产生微妙的注意力相互作用。相反,简单地将实例相关信息作为指导的一部分可以增强提示调整模型的性能,而无需额外的微调。此外,我们发现了一个有趣的现象,即“注意力锚点”,即在序列的最早位置加入实例相关的token可以成功地保持对关键结构信息的强烈关注,并表现出与所有输入token更积极的注意力交互。鉴于我们的观察,我们引入了胶囊提示调整(CaPT),这是一种高效且有效的解决方案,它将现成的、信息丰富的实例语义融入到基于提示的学习中。我们的方法创新性地以几乎无参数的方式(即,单个胶囊提示)集成了实例相关和任务相关的信息。实验结果表明,我们的方法可以在各种语言任务中表现出卓越的性能(例如,在T5-Large上平均准确率为84.03%),充当“注意力锚点”,同时享受高参数效率(例如,在Llama3.2-1B上占模型参数的0.003%)。
🔬 方法详解
问题定义:现有基于提示学习的方法在微调大型语言模型时,存在计算成本高、需要大量人工调参的问题。具体来说,它们依赖于耗时的网格搜索来确定最佳提示长度,并且需要多个提示才能达到良好的性能。此外,这些方法通常忽略了实例相关的信息,导致模型在处理不同输入时,注意力机制的表现不够理想。
核心思路:CaPT的核心思路是将实例相关的信息融入到提示中,从而使模型能够更好地理解输入,并提高生成质量。通过将实例相关的信息作为“注意力锚点”,引导模型关注输入中的关键结构信息,并促进输入token之间的有效交互。这种方法旨在克服传统提示学习方法缺乏实例感知能力的局限性。
技术框架:CaPT的技术框架主要包括以下几个步骤:首先,提取输入实例的语义信息,形成实例相关的“胶囊”表示。然后,将该胶囊表示与任务相关的提示相结合,形成最终的提示。最后,将该提示输入到大型语言模型中,进行微调或推理。整个过程只需要一个单向量胶囊提示,大大减少了参数量和计算成本。
关键创新:CaPT最重要的技术创新在于其单向量胶囊提示的设计,它能够以一种高效且有效的方式,同时融入实例相关和任务相关的信息。与传统的提示学习方法相比,CaPT不需要进行费力的网格搜索,也不需要大量的提示,从而大大降低了计算成本。此外,CaPT通过将实例相关的信息作为“注意力锚点”,提高了模型的性能。
关键设计:CaPT的关键设计包括:1) 使用预训练的语言模型提取实例的语义信息;2) 设计一种有效的胶囊表示方法,将实例的语义信息压缩成一个单向量;3) 将胶囊表示与任务相关的提示相结合,形成最终的提示;4) 将最终的提示输入到大型语言模型中,进行微调或推理。具体的参数设置和网络结构取决于具体的应用场景和大型语言模型的选择。
🖼️ 关键图片

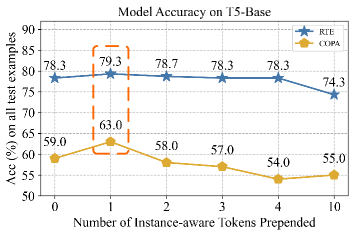
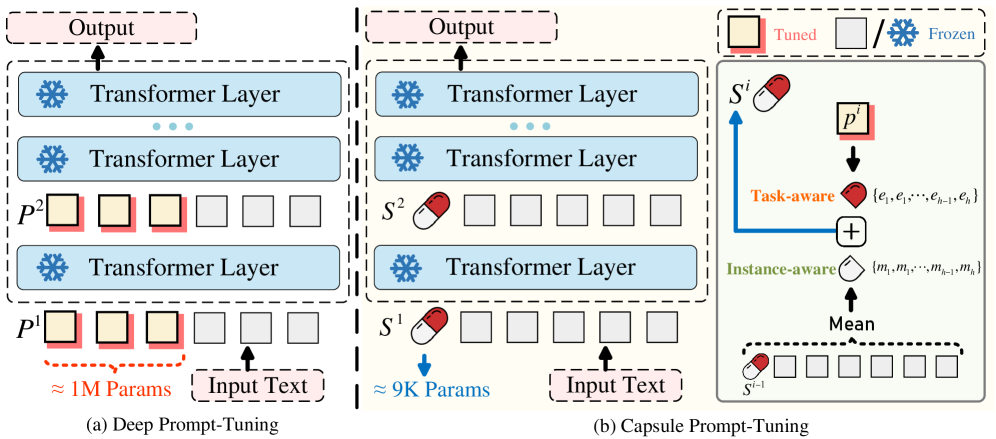
📊 实验亮点
CaPT在多个语言任务上取得了显著的性能提升。例如,在T5-Large模型上,CaPT的平均准确率达到了84.03%。此外,CaPT的参数效率非常高,在Llama3.2-1B模型上,它只占模型参数的0.003%。这些结果表明,CaPT是一种高效且有效的提示学习方法,可以显著提高大型语言模型的性能。
🎯 应用场景
CaPT具有广泛的应用前景,可以应用于各种自然语言处理任务,例如文本分类、情感分析、问答系统和机器翻译等。它特别适用于资源受限的场景,例如移动设备或嵌入式系统,因为它的参数效率很高。未来,CaPT可以进一步扩展到其他模态,例如图像和语音,从而实现多模态的提示学习。
📄 摘要(原文)
Prompt-based learning has emerged as a parameter-efficient finetuning (PEFT) approach to facilitate Large Language Model (LLM) adaptation to downstream tasks by conditioning generation with task-aware guidance. Despite its successes, current prompt-based learning methods heavily rely on laborious grid searching for optimal prompt length and typically require considerable number of prompts, introducing additional computational burden. Worse yet, our pioneer findings indicate that the task-aware prompt design is inherently limited by its absence of instance-aware information, leading to a subtle attention interplay with the input sequence. In contrast, simply incorporating instance-aware information as a part of the guidance can enhance the prompt-tuned model performance without additional fine-tuning. Moreover, we find an interesting phenomenon, namely "attention anchor", that incorporating instance-aware tokens at the earliest position of the sequence can successfully preserve strong attention to critical structural information and exhibit more active attention interaction with all input tokens. In light of our observation, we introduce Capsule Prompt-Tuning (CaPT), an efficient and effective solution that leverages off-the-shelf, informative instance semantics into prompt-based learning. Our approach innovatively integrates both instance-aware and task-aware information in a nearly parameter-free manner (i.e., one single capsule prompt). Empirical results demonstrate that our method can exhibit superior performance across various language tasks (e.g., 84.03\% average accuracy on T5-Large), serving as an "attention anchor," while enjoying high parameter efficiency (e.g., 0.003\% of model parameters on Llama3.2-1B).