When Models Can't Follow: Testing Instruction Adherence Across 256 LLMs
作者: Richard J. Young, Brandon Gillins, Alice M. Matthews
分类: cs.CL, cs.LG
发布日期: 2025-10-18
备注: 21 pages, 3 figures, 5 tables. Comprehensive evaluation of 256 LLMs on instruction-following tasks
💡 一句话要点
提出一种高效的LLM指令遵循能力评估框架,诊断模型在格式、内容、逻辑等方面的不足。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令遵循 模型评估 基准测试 提示工程
📋 核心要点
- 现有LLM指令遵循评估方法计算成本高昂,且模型可能已在现有基准上训练,导致评估结果失真。
- 设计包含20个提示的紧凑测试套件,针对格式、内容、逻辑等不同指令遵循方面进行评估。
- 对256个LLM进行大规模评估,揭示了模型在特定指令类型上的失败模式,并提供了性能对比分析。
📝 摘要(中文)
大型语言模型(LLM)的广泛应用使得对其指令遵循能力的系统评估变得至关重要。虽然存在全面的基准测试,但能够快速诊断特定指令遵循模式的评估方法仍然很有价值。由于较新的模型可能已经在现有基准上进行过训练,因此需要新的评估方法来评估其真正的能力,而非记忆性能。本文提出了一种简化的评估框架,使用20个精心设计的提示来评估LLM在不同任务类别中的指令遵循能力。我们通过一项大规模实证研究展示了该框架,该研究于2025年10月14日进行,测试了来自OpenRouter提供的331个模型中的256个经过验证的可用模型。为了确保方法论的严谨性并防止选择偏差,我们首先验证了每个模型的基本功能。与需要大量计算资源的大规模基准测试不同,我们的方法提供了一种实用的诊断工具,研究人员和从业者可以随时应用。我们的方法建立在可验证的指令之上,同时引入了一个紧凑的测试套件,在全面性和效率之间取得了平衡。每个提示都针对指令遵循的不同方面,包括格式合规性、内容约束、逻辑排序和多步骤任务执行。我们评估了来自主要提供商(OpenAI、Anthropic、Google、Meta、Mistral)和新兴实现(Qwen、DeepSeek、社区模型)的模型,并提供了比较性能分析。我们的研究结果揭示了一致的失败模式,并确定了构成特殊挑战的特定指令类型。这项工作贡献了一种实用的评估工具,以及对当代LLM领域指令遵循能力的最全面的实证分析之一。
🔬 方法详解
问题定义:现有的大型语言模型指令遵循能力评估方法,要么需要大量的计算资源,要么评估结果可能因为模型已经在现有基准上训练过而产生偏差,无法真实反映模型的指令遵循能力。因此,需要一种高效、可信的评估方法,能够快速诊断模型在不同指令遵循方面的不足。
核心思路:论文的核心思路是设计一个紧凑但全面的测试套件,包含一系列精心设计的提示,每个提示针对不同的指令遵循方面,例如格式合规性、内容约束、逻辑排序和多步骤任务执行。通过分析模型在这些提示上的表现,可以快速诊断模型在指令遵循方面的弱点。
技术框架:该评估框架主要包含以下几个阶段:1) 模型验证:首先验证每个模型的基本功能,确保其能够正常工作。2) 提示设计:设计包含20个提示的测试套件,每个提示针对不同的指令遵循方面。3) 模型评估:使用测试套件对模型进行评估,记录模型的输出。4) 结果分析:分析模型的输出,识别模型在指令遵循方面的失败模式,并进行性能对比分析。
关键创新:该方法最重要的创新点在于其紧凑性和全面性。与需要大量计算资源的大规模基准测试不同,该方法只需要20个提示即可对模型的指令遵循能力进行全面评估。此外,该方法还考虑了模型可能已经在现有基准上训练过的问题,通过设计新的提示来评估模型的真实能力。
关键设计:提示的设计是该方法的核心。每个提示都经过精心设计,以针对特定的指令遵循方面。例如,一些提示要求模型按照特定的格式输出,一些提示要求模型遵守特定的内容约束,一些提示要求模型按照特定的逻辑顺序执行任务,一些提示要求模型执行多步骤任务。此外,为了防止模型作弊,提示中还包含一些可验证的指令。
🖼️ 关键图片
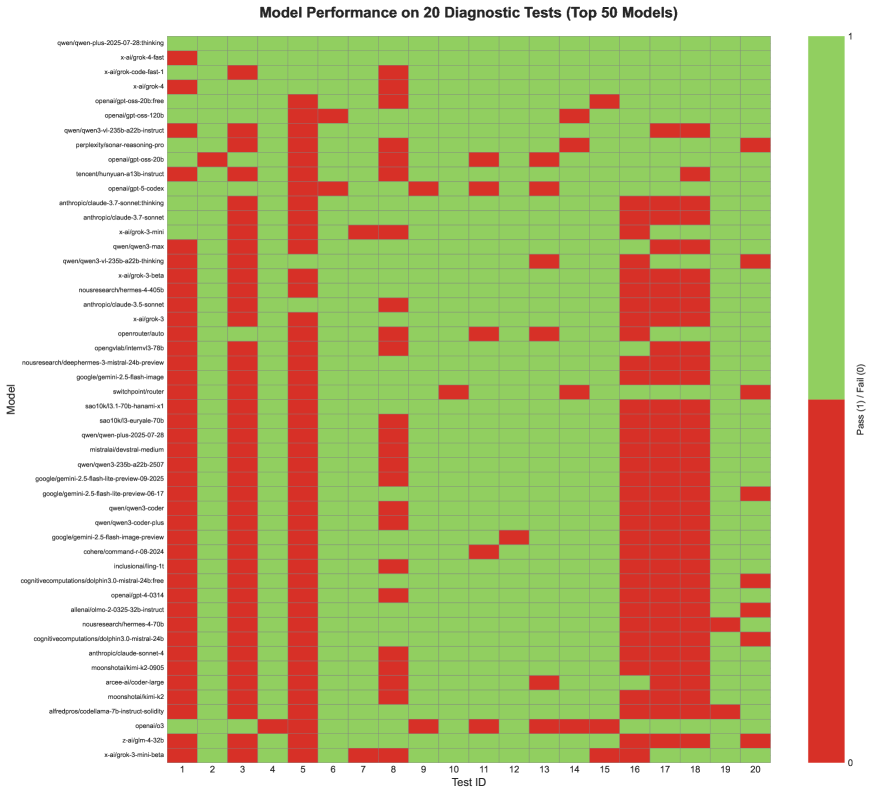

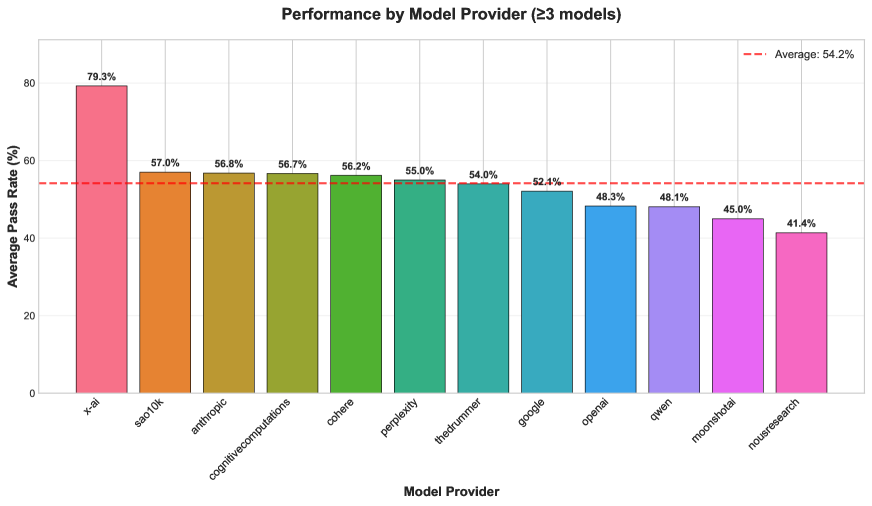
📊 实验亮点
该研究对256个LLM进行了大规模评估,揭示了模型在特定指令类型上的失败模式,例如在格式合规性和逻辑排序方面表现较差。研究还提供了来自不同提供商的模型的性能对比分析,为用户选择合适的模型提供了参考。
🎯 应用场景
该研究成果可应用于LLM的开发和评估,帮助开发者更好地了解模型的指令遵循能力,并针对性地进行改进。同时,该评估框架也可作为一种诊断工具,帮助研究人员和从业者快速评估LLM的指令遵循能力,选择合适的模型应用于特定场景。
📄 摘要(原文)
Despite widespread deployment of Large Language Models, systematic evaluation of instruction-following capabilities remains challenging. While comprehensive benchmarks exist, focused assessments that quickly diagnose specific instruction adherence patterns are valuable. As newer models may be trained on existing benchmarks, novel evaluation approaches are needed to assess genuine capabilities rather than memorized performance. This paper presents a streamlined evaluation framework using twenty carefully designed prompts to assess LLM instruction-following across diverse task categories. We demonstrate this framework through a large-scale empirical study conducted on October 14, 2025, testing 256 verified working models from 331 available via OpenRouter. To ensure methodological rigor and prevent selection bias, we first verified each model's basic functionality before inclusion. Unlike large-scale benchmarks requiring extensive computational resources, our approach offers a practical diagnostic tool researchers and practitioners can readily apply. Our methodology builds upon verifiable instructions while introducing a compact test suite balancing comprehensiveness with efficiency. Each prompt targets distinct aspects of instruction following, including format compliance, content constraints, logical sequencing, and multi-step task execution. We evaluate models from major providers (OpenAI, Anthropic, Google, Meta, Mistral) and emerging implementations (Qwen, DeepSeek, community models), providing comparative performance analysis. Our findings reveal consistent failure modes and identify specific instruction types posing particular challenges. This work contributes both a practical evaluation tool and one of the most comprehensive empirical analyses of instruction-following capabilities across the contemporary LLM landscape.