Unleashing Diverse Thinking Modes in LLMs through Multi-Agent Collaboration
作者: Zhixuan He, Yue Feng
分类: cs.CL, cs.AI, cs.LG, cs.MA
发布日期: 2025-10-18
💡 一句话要点
提出DiMo框架,通过多Agent协作激发LLM多样化思维模式,提升推理能力和可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多Agent协作 大型语言模型 可解释性推理 思维模式多样性 知识图谱 检索增强推理 人机智能
📋 核心要点
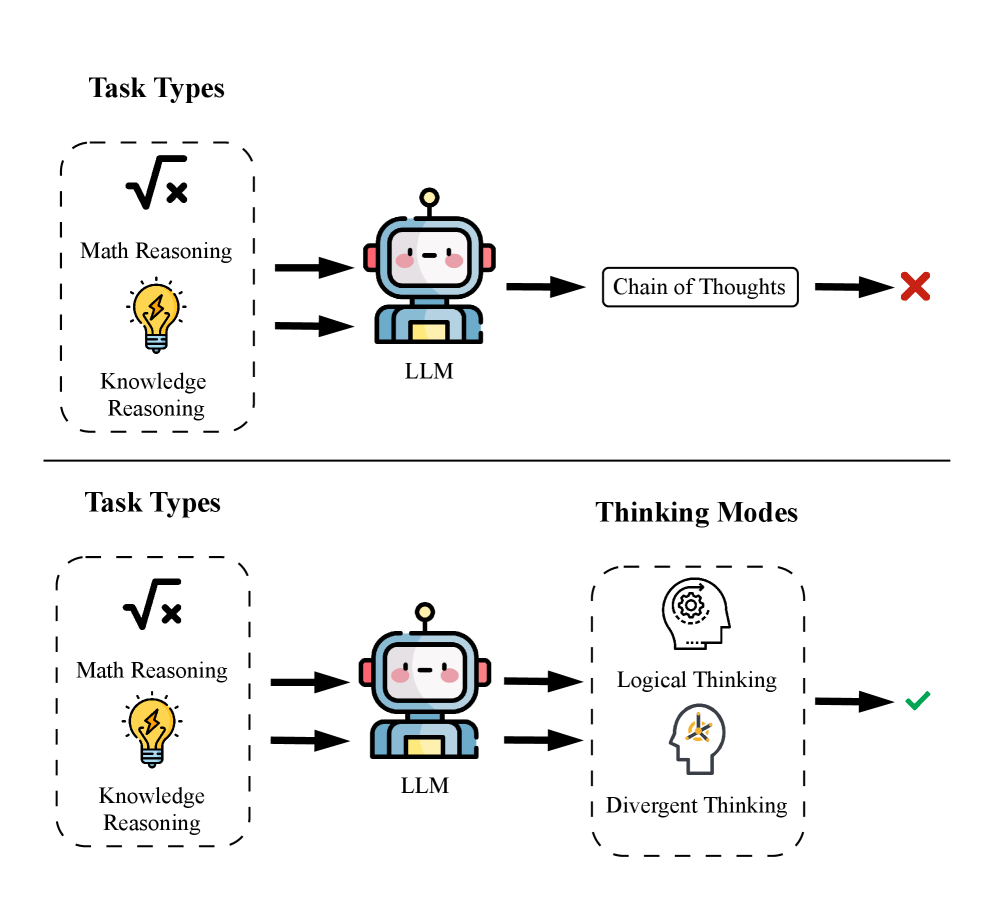
- 现有LLM推理能力强但缺乏可解释性,推理过程如同黑盒,难以理解和信任。
- DiMo框架通过构建多Agent辩论环境,激发LLM的不同思维模式,从而提升推理能力和可解释性。
- 实验表明,DiMo在多个基准测试中显著提升了LLM的准确性,尤其在数学问题上表现突出。
📝 摘要(中文)
本文提出了一种用于多样化思维模式的多Agent协作框架(DiMo),旨在提升大型语言模型(LLM)的性能和可解释性。DiMo通过模拟四个具有不同专业知识的LLM Agent之间的结构化辩论来实现。每个Agent代表一种独特的推理范式,框架通过协作探索不同的认知方法。通过迭代辩论,Agent们挑战并改进初始响应,从而产生更可靠的结论和清晰可审计的推理链。在六个基准测试中,DiMo在统一的开源设置下,提高了相对于广泛使用的单模型和辩论基线的准确性,尤其在数学问题上提升最为显著。DiMo被定位为一个语义感知、Web原生的多Agent框架,它使用LLM Agent模拟人机智能,生成带有语义类型和URL注释的证据链,用于解释和用户友好的交互。虽然实验使用了标准推理基准,但该框架旨在实例化于Web语料库和知识图谱之上,将检索增强推理与下游系统可以检查和重用的结构化论证相结合。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在推理任务中表现出色,但其推理过程往往缺乏透明度和可解释性。用户难以理解LLM得出结论的原因,这限制了LLM在需要高度信任和可追溯性的场景中的应用。此外,单一的推理模式可能限制了LLM解决复杂问题的能力。
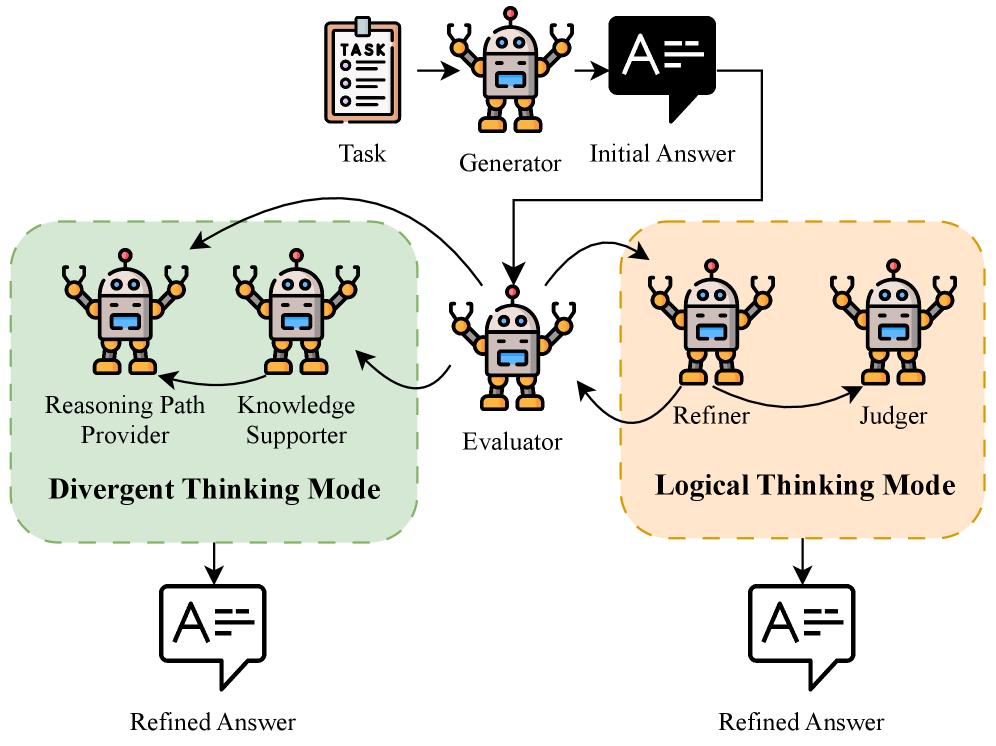
核心思路:DiMo的核心思路是模拟人类专家之间的辩论过程,通过多个具有不同专业知识和推理风格的Agent之间的协作,激发LLM的多样化思维模式。每个Agent负责从不同的角度分析问题,相互挑战和改进彼此的观点,最终达成更全面和可靠的结论。这种方式不仅提高了推理的准确性,还提供了可解释的推理链。
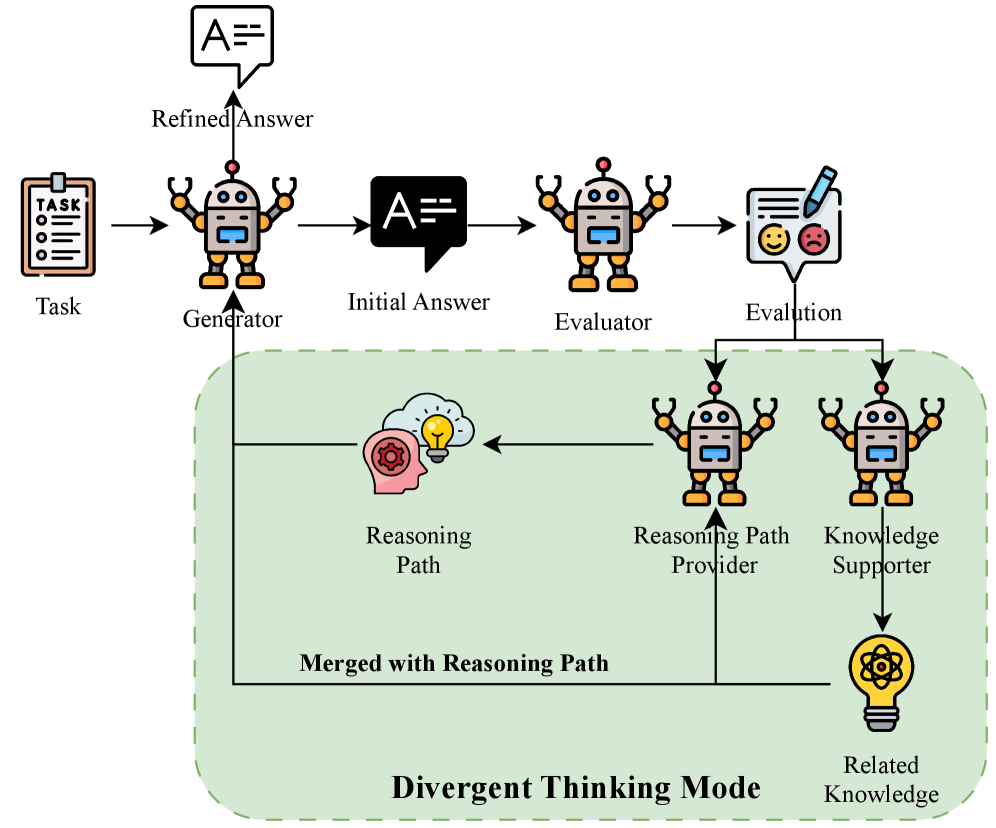
技术框架:DiMo框架包含四个主要Agent:一个提出初始解决方案的“Proposer”,一个验证解决方案的“Verifier”,一个提供替代方案的“Alternative”和一个综合所有信息的“Integrator”。整个流程包括:1) Proposer提出初始解决方案;2) Verifier验证Proposer的方案,指出潜在问题;3) Alternative提出替代方案;4) Integrator综合Proposer、Verifier和Alternative的观点,形成最终结论。这个过程可以迭代多次,直到达成共识。
关键创新:DiMo的关键创新在于其多Agent协作的架构,它允许LLM以不同的思维模式参与推理过程。与传统的单模型或简单的集成方法不同,DiMo通过模拟辩论来促进Agent之间的互动和知识共享,从而产生更鲁棒和可解释的推理结果。此外,DiMo框架的设计使其能够与Web语料库和知识图谱集成,实现检索增强的推理。
关键设计:DiMo框架的关键设计包括Agent的角色定义、辩论流程的控制和信息的综合策略。每个Agent都配备了特定的提示工程(Prompt Engineering),以引导其执行特定的推理任务。辩论流程通过预定义的规则进行控制,以确保讨论的效率和有效性。信息的综合策略则依赖于Integrator Agent的能力,它需要能够识别和整合来自不同Agent的关键信息,并生成最终的结论。
🖼️ 关键图片
📊 实验亮点
DiMo在六个基准测试中,相较于单模型和辩论基线,显著提高了准确性。尤其在数学问题上,DiMo取得了最大的性能提升,证明了其在复杂推理任务中的有效性。实验结果表明,多Agent协作能够有效提升LLM的推理能力和鲁棒性。
🎯 应用场景
DiMo框架可应用于需要高度可信和可解释的AI系统中,例如金融风险评估、医疗诊断辅助、法律咨询等领域。通过提供清晰的推理链和多角度的分析,DiMo可以帮助用户更好地理解AI的决策过程,从而增强信任感。未来,DiMo可以与知识图谱和Web数据集成,实现更强大的推理能力。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate strong performance but often lack interpretable reasoning. This paper introduces the Multi-Agent Collaboration Framework for Diverse Thinking Modes (DiMo), which enhances both performance and interpretability by simulating a structured debate among four specialized LLM agents. Each agent embodies a distinct reasoning paradigm, allowing the framework to collaboratively explore diverse cognitive approaches. Through iterative debate, agents challenge and refine initial responses, yielding more robust conclusions and an explicit, auditable reasoning chain. Across six benchmarks and under a unified open-source setup, DiMo improves accuracy over widely used single-model and debate baselines, with the largest gains on math. We position DiMo as a semantics-aware, Web-native multi-agent framework: it models human-machine intelligence with LLM agents that produce semantically typed, URL-annotated evidence chains for explanations and user-friendly interactions. Although our experiments use standard reasoning benchmarks, the framework is designed to be instantiated over Web corpora and knowledge graphs, combining retrieval-augmented reasoning with structured justifications that downstream systems can inspect and reuse.