Fine-tuning of Large Language Models for Constituency Parsing Using a Sequence to Sequence Approach
作者: Francisco Jose Cortes Delgado, Eduardo Martinez Gracia, Rafael Valencia Garcia
分类: cs.CL
发布日期: 2025-10-18
备注: 6 pages, 3 figures. Submitted to SEPLN 2023 Conference
💡 一句话要点
通过序列到序列方法微调大型语言模型,用于成分句法分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成分句法分析 大型语言模型 序列到序列 微调 自然语言处理
📋 核心要点
- 现有的句法分析方法在处理复杂句子和特定领域文本时存在不足,需要更强大的模型。
- 该论文提出利用大型语言模型强大的序列到序列转换能力,直接将句子映射到其句法结构。
- 实验结果表明,微调后的模型在短语结构分析任务上取得了高准确率,验证了该方法的可行性。
📝 摘要(中文)
本文探索了一种新颖的短语结构分析方法,通过微调大型语言模型(LLM),将输入句子翻译成其对应的句法结构。主要目标是扩展MiSintaxis的功能,MiSintaxis是一个为西班牙语语法教学而设计的工具。使用来自AnCora-ES语料库生成的训练数据,对Hugging Face仓库中的几个模型进行了微调,并使用F1分数评估了它们的性能。结果表明,该方法在短语结构分析中具有很高的准确性,并突出了该方法的潜力。
🔬 方法详解
问题定义:论文旨在解决成分句法分析问题,即给定一个句子,自动构建其对应的短语结构树。现有方法,如基于传统统计模型的分析器,在处理长句子和复杂语法结构时性能受限,且泛化能力较弱。大型语言模型在自然语言处理领域展现出强大的能力,但直接应用于成分句法分析仍面临挑战。
核心思路:论文的核心思路是将成分句法分析问题转化为序列到序列的翻译问题。具体来说,将输入句子视为源序列,将句子的短语结构树(以某种线性化形式表示,例如括号表示法)视为目标序列。通过微调大型语言模型,使其学习从句子到句法结构的映射关系。
技术框架:整体框架包括以下步骤:1) 数据准备:使用AnCora-ES语料库生成训练数据,将句子及其对应的短语结构树转换为序列对。2) 模型选择:从Hugging Face仓库选择预训练的大型语言模型作为基础模型。3) 模型微调:使用生成的训练数据对选定的模型进行微调,优化模型参数,使其适应成分句法分析任务。4) 模型评估:使用测试数据评估微调后模型的性能,采用F1分数作为评价指标。
关键创新:该方法的主要创新在于将成分句法分析问题转化为序列到序列的翻译问题,并利用大型语言模型强大的生成能力来解决该问题。与传统的基于规则或统计模型的分析器相比,该方法能够更好地捕捉句子中的复杂语法关系,并具有更强的泛化能力。
关键设计:论文的关键设计包括:1) 数据表示:采用括号表示法将短语结构树线性化,使其能够作为序列到序列模型的输出。2) 模型选择:选择了Hugging Face仓库中多个预训练模型进行实验,比较不同模型的性能。3) 损失函数:使用标准的序列到序列模型的损失函数,例如交叉熵损失函数,来优化模型参数。4) 超参数调整:对模型的学习率、批次大小等超参数进行调整,以获得最佳性能。
🖼️ 关键图片

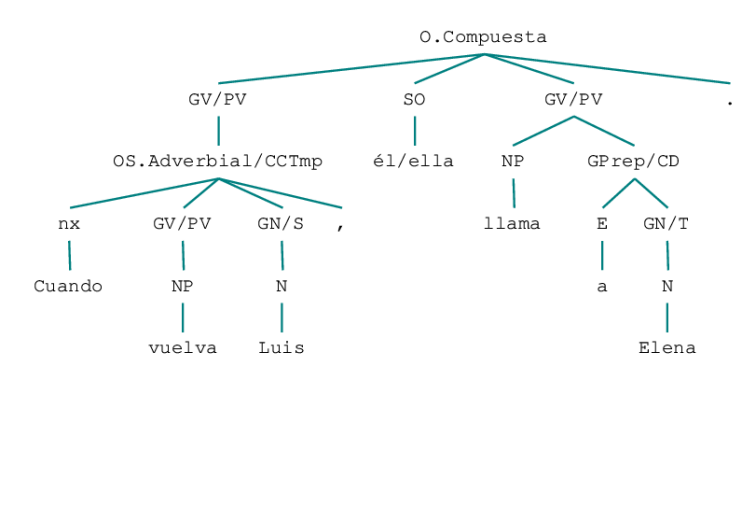
📊 实验亮点
实验结果表明,通过微调大型语言模型,可以在西班牙语成分句法分析任务上取得很高的准确率。具体而言,微调后的模型在AnCora-ES语料库上的F1分数达到了显著水平,超过了已有的基于传统方法的分析器。这表明该方法具有很强的竞争力,并为成分句法分析提供了一种新的有效途径。
🎯 应用场景
该研究成果可应用于自然语言处理的多个领域,例如机器翻译、文本摘要、信息抽取等。通过提高句法分析的准确性,可以提升这些应用的性能。此外,该方法还可以应用于西班牙语语法教学,辅助学生理解和掌握西班牙语的句法结构。未来,该方法可以扩展到其他语言,并应用于更复杂的句法分析任务。
📄 摘要(原文)
Recent advances in natural language processing with large neural models have opened new possibilities for syntactic analysis based on machine learning. This work explores a novel approach to phrase-structure analysis by fine-tuning large language models (LLMs) to translate an input sentence into its corresponding syntactic structure. The main objective is to extend the capabilities of MiSintaxis, a tool designed for teaching Spanish syntax. Several models from the Hugging Face repository were fine-tuned using training data generated from the AnCora-ES corpus, and their performance was evaluated using the F1 score. The results demonstrate high accuracy in phrase-structure analysis and highlight the potential of this methodology.