Hallucination Benchmark for Speech Foundation Models
作者: Alkis Koudounas, Moreno La Quatra, Manuel Giollo, Sabato Marco Siniscalchi, Elena Baralis
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-10-18
备注: Under Review
💡 一句话要点
提出SHALLLOW基准,用于评估语音基础模型中的幻觉现象。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音识别 幻觉评估 基准测试 语音基础模型 错误分析
📋 核心要点
- 现有ASR评估指标主要关注错误率,无法有效区分语音错误和模型幻觉,导致对模型真实性能评估不足。
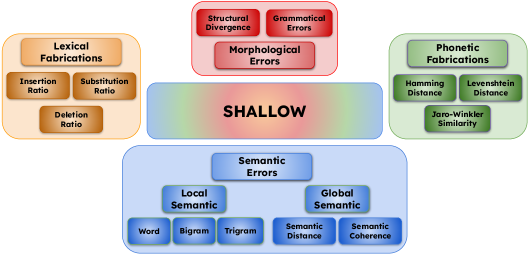
- 提出SHALLOW基准框架,从词汇、语音、形态和语义四个维度系统性地量化和评估ASR模型中的幻觉现象。
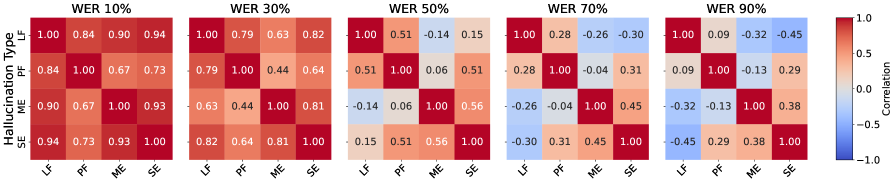
- 实验表明,SHALLOW在高识别质量时与WER相关,但在低质量时能捕捉WER无法区分的细粒度错误模式。
📝 摘要(中文)
自动语音识别(ASR)系统中的幻觉指的是神经ASR模型产生的流畅且连贯的转录,但这些转录与底层的声学输入(即语音信号)完全无关。与传统的解码错误类似,幻觉可能会损害转录在下游应用中的可用性,但由于它们保留了句法和语义上合理的结构,因此可能更具危害性。这种表面上的连贯性可能会误导后续处理阶段,并带来严重的风险,尤其是在医疗保健和法律等关键领域。传统的评估指标主要集中在基于错误的指标上,无法区分语音不准确和幻觉。因此,迫切需要新的评估框架,能够有效地识别和评估更容易产生幻觉内容的模型。为此,我们引入了SHALLOW,这是第一个系统地对ASR中的幻觉现象进行分类和量化的基准框架,它沿着词汇、语音、形态和语义四个互补的轴进行评估。我们在每个类别中定义了有针对性的指标,以生成可解释的模型行为概况。通过对各种架构和语音领域的评估,我们发现,当识别质量较高时(即WER较低时),SHALLOW指标与词错误率(WER)密切相关。然而,随着WER的增加,这种相关性会显著减弱。因此,SHALLOW能够捕捉到WER在退化和具有挑战性的条件下无法区分的细粒度错误模式。我们的框架支持对模型弱点的具体诊断,并提供超出聚合错误率所能提供的模型改进反馈。
🔬 方法详解
问题定义:论文旨在解决自动语音识别(ASR)模型中幻觉现象的评估问题。现有评估方法,如词错误率(WER),主要关注整体错误率,无法区分语音错误和模型产生的幻觉。幻觉是指模型生成与实际语音内容无关但语法和语义上合理的转录,会对下游应用产生误导,尤其是在高风险领域。
核心思路:论文的核心思路是构建一个多维度的评估框架,从词汇、语音、形态和语义四个角度系统性地量化ASR模型中的幻觉现象。通过定义针对每个维度的指标,可以更细粒度地分析模型的行为,识别模型在哪些方面容易产生幻觉。
技术框架:SHALLOW框架包含四个主要模块,分别对应词汇、语音、形态和语义四个维度。每个模块定义了特定的指标来衡量模型在相应维度上的幻觉程度。例如,词汇维度可能关注模型是否生成了与输入语音完全无关的词汇,语音维度可能关注模型是否生成了发音相似但含义不同的词汇。整体流程是:输入语音 -> ASR模型 -> SHALLOW评估框架 -> 输出各维度幻觉指标。
关键创新:SHALLOW的关键创新在于其多维度评估方法,它超越了传统的基于错误率的评估,能够更全面地刻画ASR模型的行为。与现有方法相比,SHALLOW能够识别模型在特定维度上的弱点,为模型改进提供更具体的指导。
关键设计:SHALLOW框架的关键设计在于每个维度指标的定义。这些指标需要能够准确地反映模型在该维度上的幻觉程度,同时也要易于计算和解释。论文中可能详细描述了这些指标的具体计算方法和参数设置。此外,框架的设计还需要考虑不同语音领域和模型架构的适用性,保证评估的公平性和有效性。
🖼️ 关键图片
📊 实验亮点
SHALLOW基准的实验结果表明,在高识别质量(低WER)的情况下,SHALLOW指标与WER密切相关。然而,随着WER的增加,这种相关性显著减弱,表明SHALLOW能够捕捉到WER无法区分的细粒度错误模式。这说明SHALLOW在评估低质量语音识别结果时具有优势,能够更准确地反映模型的幻觉程度。
🎯 应用场景
该研究成果可应用于评估和改进各种语音基础模型,尤其是在医疗、法律等对准确性要求极高的领域。通过SHALLOW框架,可以诊断模型的弱点,指导模型训练,降低幻觉发生的概率,提高语音识别系统的可靠性和安全性。未来,该框架可扩展到其他语音处理任务,如语音翻译、语音合成等。
📄 摘要(原文)
Hallucinations in automatic speech recognition (ASR) systems refer to fluent and coherent transcriptions produced by neural ASR models that are completely unrelated to the underlying acoustic input (i.e., the speech signal). While similar to conventional decoding errors in potentially compromising the usability of transcriptions for downstream applications, hallucinations can be more detrimental due to their preservation of syntactically and semantically plausible structure. This apparent coherence can mislead subsequent processing stages and introduce serious risks, particularly in critical domains such as healthcare and law. Conventional evaluation metrics are primarily centered on error-based metrics and fail to distinguish between phonetic inaccuracies and hallucinations. Consequently, there is a critical need for new evaluation frameworks that can effectively identify and assess models with a heightened propensity for generating hallucinated content. To this end, we introduce SHALLOW, the first benchmark framework that systematically categorizes and quantifies hallucination phenomena in ASR along four complementary axes: lexical, phonetic, morphological, and semantic. We define targeted metrics within each category to produce interpretable profiles of model behavior. Through evaluation across various architectures and speech domains, we have found that SHALLOW metrics correlate strongly with word error rate (WER) when recognition quality is high (i.e., low WER). Still, this correlation weakens substantially as WER increases. SHALLOW, therefore, captures fine-grained error patterns that WER fails to distinguish under degraded and challenging conditions. Our framework supports specific diagnosis of model weaknesses and provides feedback for model improvement beyond what aggregate error rates can offer.