Language over Content: Tracing Cultural Understanding in Multilingual Large Language Models
作者: Seungho Cho, Changgeon Ko, Eui Jun Hwang, Junmyeong Lee, Huije Lee, Jong C. Park
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-18 (更新: 2025-11-11)
备注: Accepted to CIKM 2025 Workshop on Human Centric AI
💡 一句话要点
通过激活路径分析,揭示多语言大模型中的文化理解机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文化理解 激活路径分析 跨文化评估 多语言处理
📋 核心要点
- 现有大语言模型文化理解评估侧重输出,忽略了内部机制和驱动因素。
- 论文通过分析激活路径重叠,探究大语言模型在不同文化和语言条件下的内部表征。
- 实验表明,语言相似性对内部表征影响显著,但文化差异可能导致表征差异。
📝 摘要(中文)
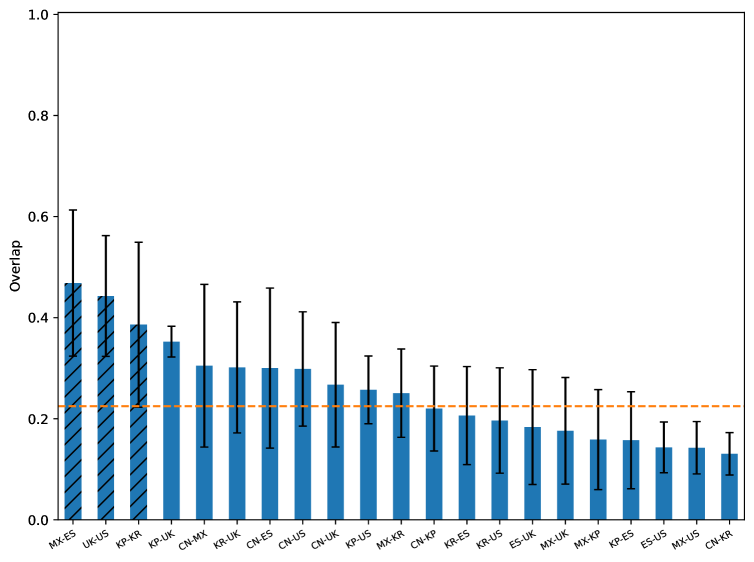
大型语言模型(LLMs)越来越多地应用于不同的文化背景中,因此准确的文化理解至关重要。以往的评估主要集中在输出层面的性能,掩盖了驱动响应差异的因素。而使用电路分析的研究覆盖的语言较少,且很少关注文化。本文通过测量在两种条件下回答语义等价问题时的激活路径重叠来追踪LLM内部的文化理解机制:一是固定问题语言,改变目标国家;二是固定国家,改变问题语言。我们还使用同语言国家对来区分语言和文化方面的影响。结果表明,同语言、跨国家问题的内部路径重叠程度高于跨语言、同国家问题,表明存在很强的语言特定模式。值得注意的是,韩国-朝鲜对的重叠度较低且变异性较高,表明语言相似性并不能保证对齐的内部表征。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在跨文化应用中文化理解机制不明确的问题。现有评估方法主要关注输出结果,无法深入了解模型内部如何处理和理解不同文化背景下的信息。此外,现有的电路分析方法覆盖的语言种类有限,且很少关注文化因素,难以全面评估LLMs的文化理解能力。
核心思路:论文的核心思路是通过分析LLMs在处理语义等价但文化背景不同的问题时,其内部激活路径的重叠程度,来推断模型对不同文化的理解程度。如果模型对不同文化背景的问题产生相似的激活路径,则表明模型对这些文化具有相似的理解。反之,如果激活路径差异较大,则表明模型对这些文化的理解存在差异。
技术框架:论文的技术框架主要包括以下几个步骤:1) 设计语义等价但文化背景不同的问题;2) 使用LLMs回答这些问题,并记录模型内部的激活值;3) 计算不同问题对应的激活路径之间的重叠程度;4) 分析激活路径重叠程度与文化背景之间的关系。具体而言,论文设计了两种实验条件:一是固定问题语言,改变目标国家;二是固定国家,改变问题语言。此外,论文还使用了同语言国家对(如韩国-朝鲜)来区分语言和文化方面的影响。
关键创新:论文的关键创新在于提出了一种基于激活路径分析的文化理解评估方法。该方法能够深入了解LLMs内部如何处理和理解不同文化背景下的信息,从而为改进LLMs的跨文化应用提供指导。此外,论文还通过对比不同实验条件下的激活路径重叠程度,揭示了语言和文化因素对LLMs内部表征的影响。
关键设计:论文的关键设计包括:1) 精心设计的语义等价但文化背景不同的问题,确保问题能够有效区分不同文化背景;2) 选择合适的LLMs作为实验对象,确保模型具有一定的文化理解能力;3) 使用合适的激活路径重叠度量方法,确保能够准确反映不同问题对应的激活路径之间的相似程度。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,同语言、跨国家问题的内部路径重叠程度高于跨语言、同国家问题,说明语言对模型内部表征的影响更大。值得注意的是,韩国-朝鲜这对语言相似但文化差异显著的国家对,其激活路径重叠度较低,表明语言相似性并不一定意味着相似的内部表征。这些发现为理解LLMs的文化理解机制提供了重要依据。
🎯 应用场景
该研究成果可应用于提升多语言大模型在跨文化交流、内容生成和信息检索等领域的性能。通过深入理解模型对不同文化的认知差异,可以开发更具文化敏感性的AI系统,减少文化误解和偏见,促进全球范围内的有效沟通和合作。未来的研究可以进一步探索如何利用这些发现来改进模型的训练方法,使其更好地适应不同的文化环境。
📄 摘要(原文)
Large language models (LLMs) are increasingly used across diverse cultural contexts, making accurate cultural understanding essential. Prior evaluations have mostly focused on output-level performance, obscuring the factors that drive differences in responses, while studies using circuit analysis have covered few languages and rarely focused on culture. In this work, we trace LLMs' internal cultural understanding mechanisms by measuring activation path overlaps when answering semantically equivalent questions under two conditions: varying the target country while fixing the question language, and varying the question language while fixing the country. We also use same-language country pairs to disentangle language from cultural aspects. Results show that internal paths overlap more for same-language, cross-country questions than for cross-language, same-country questions, indicating strong language-specific patterns. Notably, the South Korea-North Korea pair exhibits low overlap and high variability, showing that linguistic similarity does not guarantee aligned internal representation.