ReviewGuard: Enhancing Deficient Peer Review Detection via LLM-Driven Data Augmentation
作者: Haoxuan Zhang, Ruochi Li, Sarthak Shrestha, Shree Harshini Mamidala, Revanth Putta, Arka Krishan Aggarwal, Ting Xiao, Junhua Ding, Haihua Chen
分类: cs.CL
发布日期: 2025-10-18 (更新: 2025-11-20)
备注: Accepted as a full paper at the 2025 ACM/IEEE Joint Conference on Digital Libraries (JCDL 2025)
🔗 代码/项目: GITHUB
💡 一句话要点
ReviewGuard:利用LLM驱动的数据增强提升缺陷同行评审检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 同行评审 缺陷评审检测 大型语言模型 数据增强 学术诚信
📋 核心要点
- 同行评审质量下降,AI辅助评审的兴起加剧了缺陷评审的风险,威胁学术诚信。
- ReviewGuard利用LLM进行数据增强,构建大规模缺陷评审数据集,并微调模型以提升检测性能。
- 实验表明,ReviewGuard能有效检测缺陷评审,混合训练策略显著提升了Qwen等模型的召回率和F1值。
📝 摘要(中文)
同行评审是科学的守门人,但投稿数量的激增和大型语言模型(LLM)在学术评估中的广泛应用带来了前所未有的挑战。虽然最近的工作主要集中在使用LLM来提高评审效率,但来自人类专家和AI系统的未经检查的缺陷评审可能会系统性地破坏学术诚信。为了解决这个问题,我们引入了ReviewGuard,这是一个自动化的系统,用于通过一个四阶段的LLM驱动框架来检测和分类缺陷评审:从OpenReview上的ICLR和NeurIPS收集数据,使用GPT-4.1进行标注并进行人工验证,合成数据增强产生6,634篇论文和24,657条真实评审以及46,438条合成评审,以及对基于编码器的模型和开源LLM进行微调。特征分析表明,缺陷评审的评分较低,自我报告的置信度较高,结构复杂性降低,并且比充分评审具有更多的负面情绪。AI生成的文本检测显示,自ChatGPT出现以来,AI撰写的评审急剧增加。合成数据和真实数据的混合训练显着提高了检测性能——例如,Qwen 3-8B的召回率达到0.6653,F1达到0.7073,分别从0.5499和0.5606提高。这项研究提出了第一个用于检测缺陷同行评审的LLM驱动系统,为同行评审中的AI治理提供了依据。代码、提示和数据可在https://github.com/haoxuan-unt2024/ReviewGuard获得。
🔬 方法详解
问题定义:论文旨在解决同行评审中缺陷评审难以检测的问题。现有方法难以有效区分充分评审和缺陷评审,尤其是在AI辅助评审日益普及的情况下,缺陷评审可能对学术诚信造成威胁。现有方法缺乏足够的数据和有效的模型来应对这一挑战。
核心思路:论文的核心思路是利用LLM生成合成数据来增强训练数据集,从而提高缺陷评审检测模型的性能。通过分析缺陷评审的特征,指导LLM生成更具代表性的合成数据,并结合真实数据进行训练,提升模型的泛化能力。
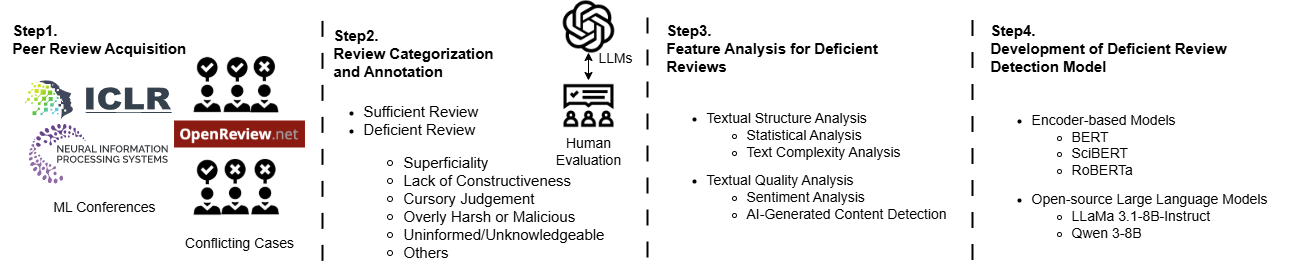
技术框架:ReviewGuard包含四个主要阶段:1) 数据收集:从OpenReview收集ICLR和NeurIPS的评审数据。2) 数据标注:使用GPT-4.1对评审进行标注,并进行人工验证。3) 数据增强:利用LLM生成合成评审数据,扩充数据集。4) 模型训练:微调基于编码器的模型和开源LLM,用于缺陷评审检测。
关键创新:该论文的关键创新在于利用LLM进行数据增强,构建大规模的缺陷评审数据集。通过分析缺陷评审的特征(如评分、置信度、结构复杂性和情感),指导LLM生成更真实的合成数据,从而有效提升了缺陷评审检测模型的性能。
关键设计:在数据增强阶段,论文设计了特定的prompt,指导GPT-4.1生成不同类型的缺陷评审。在模型训练阶段,采用了混合训练策略,将真实数据和合成数据结合起来进行训练,以提高模型的泛化能力。具体参数设置和损失函数细节未知。
🖼️ 关键图片

📊 实验亮点
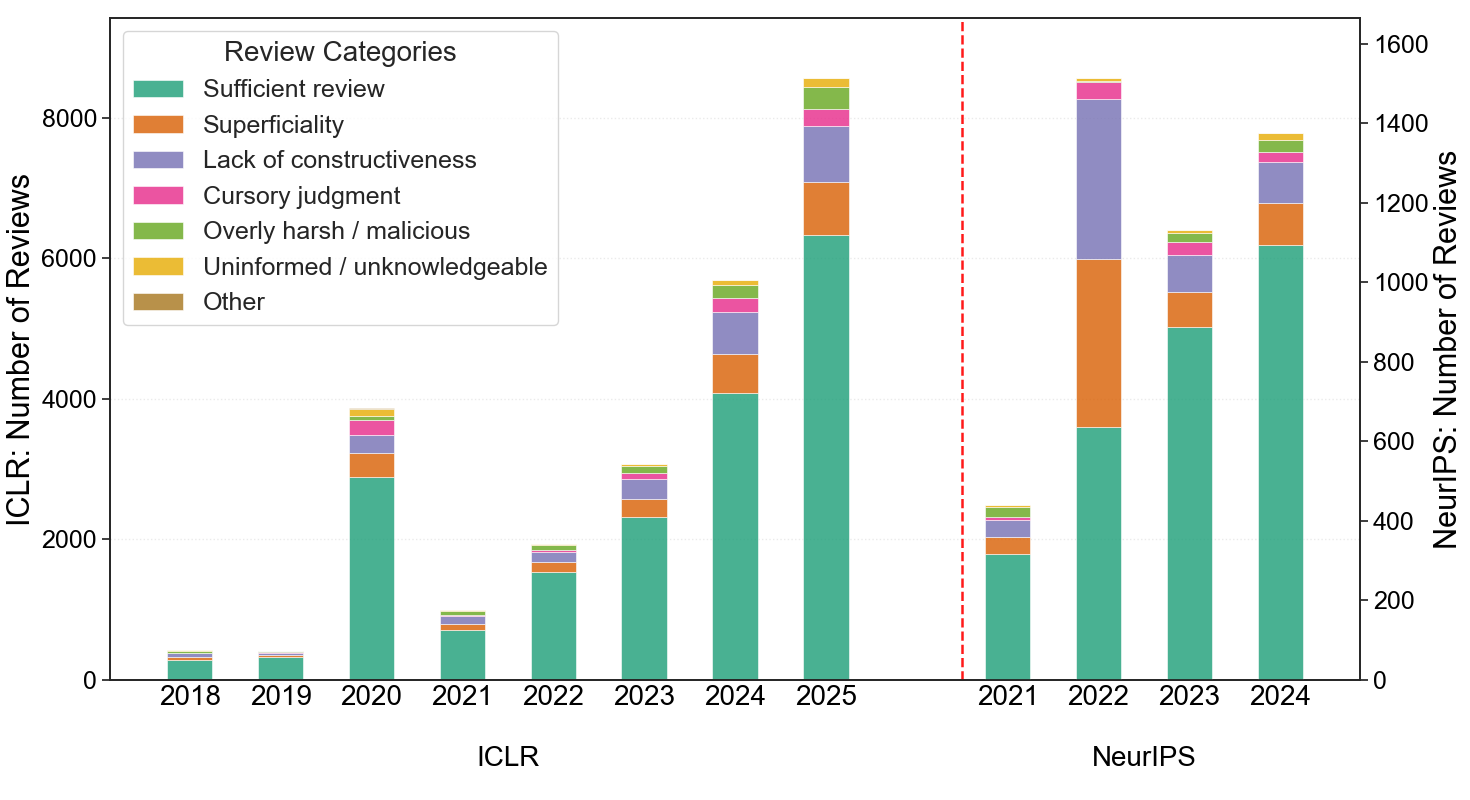
实验结果表明,ReviewGuard能够有效检测缺陷评审。通过混合训练策略,Qwen 3-8B模型的召回率从0.5499提升到0.6653,F1值从0.5606提升到0.7073。AI生成文本检测显示,自ChatGPT出现以来,AI撰写的评审急剧增加,更突显了缺陷评审检测的重要性。
🎯 应用场景
ReviewGuard可应用于学术出版领域,自动检测和过滤缺陷同行评审,提升评审质量,维护学术诚信。该系统还可用于培训评审人员,提高其识别缺陷评审的能力。未来,该技术可扩展到其他需要质量控制的领域,如软件代码审查、医疗诊断等。
📄 摘要(原文)
Peer review serves as the gatekeeper of science, yet the surge in submissions and widespread adoption of large language models (LLMs) in scholarly evaluation present unprecedented challenges. While recent work has focused on using LLMs to improve review efficiency, unchecked deficient reviews from both human experts and AI systems threaten to systematically undermine academic integrity. To address this issue, we introduce ReviewGuard, an automated system for detecting and categorizing deficient reviews through a four-stage LLM-driven framework: data collection from ICLR and NeurIPS on OpenReview, GPT-4.1 annotation with human validation, synthetic data augmentation yielding 6,634 papers with 24,657 real and 46,438 synthetic reviews, and fine-tuning of encoder-based models and open-source LLMs. Feature analysis reveals that deficient reviews exhibit lower rating scores, higher self-reported confidence, reduced structural complexity, and more negative sentiment than sufficient reviews. AI-generated text detection shows dramatic increases in AI-authored reviews since ChatGPT's emergence. Mixed training with synthetic and real data substantially improves detection performance - for example, Qwen 3-8B achieves recall of 0.6653 and F1 of 0.7073, up from 0.5499 and 0.5606 respectively. This study presents the first LLM-driven system for detecting deficient peer reviews, providing evidence to inform AI governance in peer review. Code, prompts, and data are available at https://github.com/haoxuan-unt2024/ReviewGuard