RAVEN: Robust Advertisement Video Violation Temporal Grounding via Reinforcement Reasoning
作者: Deyi Ji, Yuekui Yang, Haiyang Wu, Shaoping Ma, Tianrun Chen, Lanyun Zhu
分类: cs.CL
发布日期: 2025-10-18
备注: ACL 2025 (Oral, Industry Track)
💡 一句话要点
RAVEN:通过强化推理实现鲁棒的广告视频违规行为时序定位
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 广告视频违规检测 时序定位 强化学习 多模态大语言模型 课程学习 群体相对策略优化 内容审核
📋 核心要点
- 现有广告视频违规检测方法在时序定位精度、抗噪声标注干扰及泛化能力上存在不足。
- RAVEN框架融合课程强化学习与多模态大语言模型,提升推理和认知能力,从而更准确地检测违规行为。
- 实验结果表明,RAVEN在工业数据集和公共基准上均表现出色,并在在线A/B测试中验证了其有效性。
📝 摘要(中文)
广告视频违规检测对于确保平台合规性至关重要,但现有方法在精确时序定位、噪声标注和有限泛化能力方面存在困难。我们提出了RAVEN,一个新颖的框架,它集成了课程强化学习与多模态大型语言模型(MLLMs),以增强违规检测的推理和认知能力。RAVEN采用渐进式训练策略,结合精确和粗略标注的数据,并利用群体相对策略优化(GRPO)来发展涌现的推理能力,而无需显式的推理标注。多个分层复杂奖励机制确保了精确的时序定位和一致的类别预测。在工业数据集和公共基准上的实验表明,RAVEN在违规类别准确性和时间间隔定位方面取得了优异的性能。我们还设计了一个pipeline,将RAVEN部署到在线广告服务中,在线A/B测试进一步验证了其在实际应用中的可行性,并在精确率和召回率方面取得了显著提升。RAVEN还表现出强大的泛化能力,缓解了与监督微调相关的灾难性遗忘问题。
🔬 方法详解
问题定义:论文旨在解决广告视频中违规行为的精确时序定位问题。现有方法面临的痛点包括:1) 时序定位精度不足,难以准确定位违规片段;2) 标注数据存在噪声,影响模型训练效果;3) 泛化能力有限,难以适应新的违规类型或场景。
核心思路:论文的核心思路是利用课程强化学习,结合多模态大语言模型,逐步提升模型在复杂环境下的推理和认知能力。通过强化学习,模型可以学习如何在视频中进行探索,并根据奖励信号优化其定位策略。多模态大语言模型则可以提供丰富的语义信息,帮助模型更好地理解视频内容和违规行为的含义。
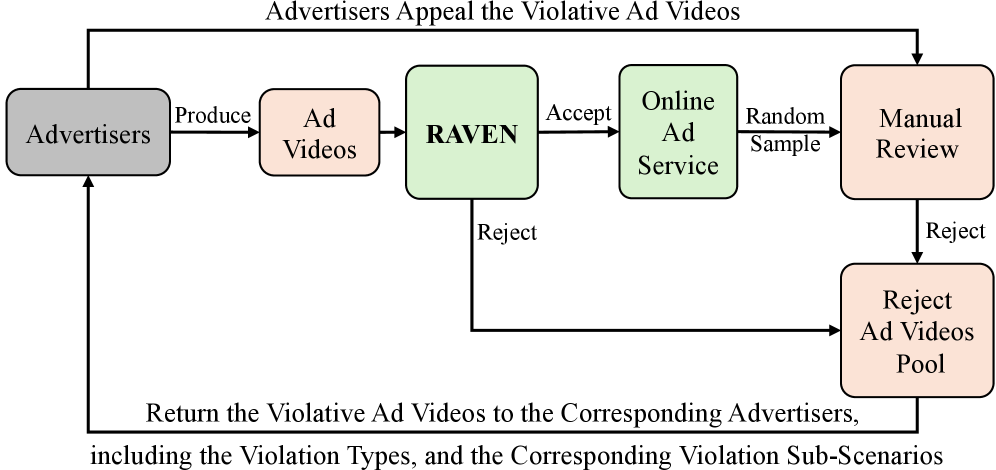
技术框架:RAVEN框架主要包含以下几个模块:1) 多模态特征提取模块,用于提取视频和文本等多模态特征;2) 强化学习代理,负责学习违规行为的时序定位策略;3) 奖励机制,用于指导强化学习代理的训练;4) 课程学习策略,用于逐步增加训练难度,提升模型的泛化能力。整体流程是,首先利用多模态特征提取模块提取视频特征,然后将特征输入到强化学习代理中,代理根据当前状态选择一个动作(例如,调整时间窗口),并获得一个奖励。通过不断迭代,代理可以学习到最优的定位策略。
关键创新:RAVEN的关键创新在于:1) 提出了一个基于课程强化学习的框架,可以有效地解决广告视频违规行为的时序定位问题;2) 结合了多模态大语言模型,提升了模型的推理和认知能力;3) 设计了一个分层复杂的奖励机制,确保了精确的时序定位和一致的类别预测;4) 采用了群体相对策略优化(GRPO),发展涌现的推理能力,而无需显式的推理标注。
关键设计:RAVEN的关键设计包括:1) 课程学习策略,从粗略标注到精确标注,逐步增加训练难度;2) 分层奖励机制,包括类别预测奖励、时序定位奖励等,用于指导强化学习代理的训练;3) GRPO算法,用于优化强化学习代理的策略;4) 多模态特征融合方法,用于将视频和文本等多模态特征进行有效融合。
🖼️ 关键图片

📊 实验亮点
RAVEN在工业数据集和公共基准上均取得了优异的性能。在违规类别准确性和时间间隔定位方面,RAVEN显著优于现有方法。在线A/B测试表明,RAVEN在精确率和召回率方面均有显著提升,验证了其在实际应用中的可行性。此外,RAVEN还表现出强大的泛化能力,有效缓解了灾难性遗忘问题。
🎯 应用场景
RAVEN可应用于在线广告平台的内容审核,自动检测和定位违规广告视频,降低人工审核成本,提高审核效率和准确性。该技术还可扩展到其他视频内容审核场景,例如短视频平台、直播平台等,具有广阔的应用前景和重要的社会价值。未来,RAVEN有望进一步提升泛化能力,适应更多类型的违规行为和更复杂的视频场景。
📄 摘要(原文)
Advertisement (Ad) video violation detection is critical for ensuring platform compliance, but existing methods struggle with precise temporal grounding, noisy annotations, and limited generalization. We propose RAVEN, a novel framework that integrates curriculum reinforcement learning with multimodal large language models (MLLMs) to enhance reasoning and cognitive capabilities for violation detection. RAVEN employs a progressive training strategy, combining precisely and coarsely annotated data, and leverages Group Relative Policy Optimization (GRPO) to develop emergent reasoning abilities without explicit reasoning annotations. Multiple hierarchical sophisticated reward mechanism ensures precise temporal grounding and consistent category prediction. Experiments on industrial datasets and public benchmarks show that RAVEN achieves superior performances in violation category accuracy and temporal interval localization. We also design a pipeline to deploy the RAVEN on the online Ad services, and online A/B testing further validates its practical applicability, with significant improvements in precision and recall. RAVEN also demonstrates strong generalization, mitigating the catastrophic forgetting issue associated with supervised fine-tuning.