TrajSelector: Harnessing Latent Representations for Efficient and Effective Best-of-N in Large Reasoning Model
作者: Bin Yu, Xinming Wang, Shijie Lian, Haotian Li, Changti Wu, Ruina Hu, Bailing Wang, Yuliang Wei, Kai Chen
分类: cs.CL
发布日期: 2025-10-18
备注: 13 pages, 6 figures. Project website: https://zgca-ai4edu.github.io/TrajSelector
💡 一句话要点
TrajSelector:利用LLM隐空间表征,高效选择最优推理轨迹,提升大模型推理性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理优化 隐空间表征 轨迹选择 过程奖励模型
📋 核心要点
- 现有Best-of-N方法依赖高计算开销的过程奖励模型,且未充分利用LLM的隐空间信息。
- TrajSelector利用LLM的隐状态进行过程级评分,使用轻量级验证器评估轨迹质量。
- 实验表明,TrajSelector在多个基准测试中超越多数投票和现有过程奖励模型,同时降低推理成本。
📝 摘要(中文)
大型语言模型(LLMs)在复杂推理任务中取得了显著进展,这主要得益于测试时扩展(TTS)范式,该范式在推理过程中分配额外的计算资源。其中,外部TTS(特别是Best-of-N选择范式)通过从多个独立生成的推理轨迹中进行选择,实现了可扩展的性能改进。然而,这种方法面临着关键的限制:(i)部署过程奖励模型的高计算开销,(ii)LLM固有潜在表征的未充分利用。我们引入了TrajSelector,这是一个高效的Best-of-N框架,它利用采样器LLM中的隐藏状态进行过程级评分。一个轻量级的验证器(只有0.6B参数)评估逐步轨迹的质量,然后聚合这些分数以识别最佳推理轨迹。我们的框架采用完全数据驱动的端到端训练方法,消除了对大量步骤级注释的依赖。在五个基准测试中的实验结果表明,TrajSelector提供了持续的性能提升。在Best-of-32设置中,它超过了多数投票4.61%的准确率,并且优于现有的过程奖励模型4.31%到12.21%,同时保持了较低的推理成本。
🔬 方法详解
问题定义:现有Best-of-N方法在大型语言模型推理中,依赖于计算密集的过程奖励模型来选择最佳推理轨迹,这导致了高昂的计算成本。此外,这些方法通常忽略了LLM自身在生成推理轨迹时产生的丰富隐空间表征,造成了信息浪费。因此,如何高效且有效地利用LLM的内在信息,降低推理成本,同时提升推理性能,是本文要解决的核心问题。
核心思路:TrajSelector的核心思路是利用LLM在生成推理轨迹过程中产生的隐状态,作为轨迹质量的评估依据。通过训练一个轻量级的验证器,对每个步骤的隐状态进行评分,然后将这些分数聚合起来,作为整个轨迹的质量评估。这种方法避免了使用复杂的外部奖励模型,降低了计算开销,同时充分利用了LLM的内在信息。
技术框架:TrajSelector的整体框架包括以下几个主要模块:1) 轨迹生成器:使用LLM生成N条独立的推理轨迹。2) 隐状态提取器:从LLM中提取每条轨迹在每个步骤的隐状态。3) 轻量级验证器:使用一个小型神经网络(0.6B参数)对每个步骤的隐状态进行评分,评估该步骤的质量。4) 轨迹聚合器:将每个步骤的分数聚合起来,得到整个轨迹的质量评估。5) 轨迹选择器:选择质量评估最高的轨迹作为最终的推理结果。
关键创新:TrajSelector的关键创新在于:1) 隐状态利用:首次将LLM的隐状态用于过程级轨迹评分,充分利用了LLM的内在信息。2) 轻量级验证器:使用小型神经网络作为验证器,降低了计算开销。3) 端到端训练:采用完全数据驱动的端到端训练方法,无需大量步骤级标注,降低了训练成本。与现有方法的本质区别在于,TrajSelector避免了使用复杂的外部奖励模型,而是直接利用LLM自身的隐状态进行轨迹评估。
关键设计:TrajSelector的关键设计包括:1) 验证器结构:验证器采用Transformer结构,输入为LLM的隐状态,输出为该步骤的质量评分。2) 损失函数:采用对比学习损失函数,鼓励高质量轨迹的评分高于低质量轨迹的评分。3) 聚合策略:采用加权平均的方式聚合每个步骤的评分,权重可以根据步骤的重要性进行调整。4) 训练数据:使用LLM生成的推理轨迹作为训练数据,通过自监督的方式学习验证器的参数。
🖼️ 关键图片
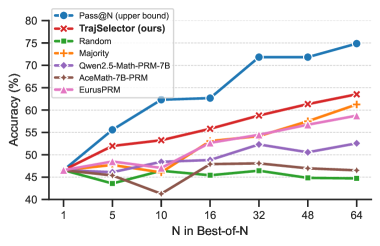

📊 实验亮点
TrajSelector在五个基准测试中取得了显著的性能提升。在Best-of-32设置下,TrajSelector的准确率超过了多数投票4.61%,并且优于现有的过程奖励模型4.31%到12.21%,同时保持了较低的推理成本。这些结果表明,TrajSelector能够有效利用LLM的隐状态信息,提升推理性能,并降低计算开销。
🎯 应用场景
TrajSelector具有广泛的应用前景,可应用于各种需要复杂推理的大型语言模型任务中,例如数学问题求解、代码生成、知识问答等。该方法能够有效提升LLM的推理性能,降低推理成本,并提高模型的可靠性。未来,TrajSelector可以进一步扩展到其他类型的模型和任务中,例如多模态推理、强化学习等。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable progress in complex reasoning tasks, largely enabled by test-time scaling (TTS) paradigms that allocate additional compute during inference. Among these, external TTS (particularly the Best-of-N selection paradigm) yields scalable performance improvements by selecting from multiple independently generated reasoning trajectories. However, this approach faces key limitations: (i) the high computational overhead of deploying process reward models, (ii) the underutilization of the LLM's intrinsic latent representations. We introduce TrajSelector, an efficient and effective Best-of-N framework that exploit the hidden states in the sampler LLM for process-level scoring. A lightweight verifier (with only 0.6B parameters) evaluates the quality of step-wise trajectory, and then aggregates these scores to identify the optimal reasoning trajectory. Our framework employs a fully data-driven, end-to-end training recipe that eliminates reliance on massive step-level annotations. Experiential results across five benchmarks demonstrate that TrajSelector delivers consistent performance gains. In Best-of-32 settings, it surpasses majority voting by 4.61% accuracy and outperforms existing process reward models by 4.31% to 12.21%, all while maintaining lower inference costs.